Azure Databricksとは?特長と基本的な使い方を紹介

Azure Databricksとは、Databricks社が提供するDatabricksをマイクロソフト社が提供するMicrosoft Azure環境向けに最適化した、統合データ分析プラットフォームです。
Azure Databricksでは、データ分析・AIソリューションを大規模に構築・デプロイ・共有・保守することが可能です。
本ブログでは、Azure Databricksの特長と使い方について紹介します。
1.Azure Databricksの特長
■データ分析
処理エンジンにApache Sparkを採用しているため、分散処理に秀でており、大量のデータを高速で処理することが可能です。
また、構造・非構造データを問わずに分析できます。
■共同ノートブック
共同ノートブックにより共同での開発作業ができ、Databricks Reposを設定することでGit操作でのソース管理を行うことが可能です。
また、ノートブック開発言語を選択して開発を行うことが可能です。
(Python、SQL、Scala、R)
■機械学習
ML FLOWといった機械学習のライフサイクル管理サービス、組み込みの機械学習ライブラリ等が用意されており、機械学習環境が整えられています。
■セキュリティ
Microsoft Entra ID(旧Azure Active Directory)との統合により、シングルサインオンでの強固なデータアクセス制御が可能です。
■拡張性
Azure Data Factory、Azure Synapse Analytics、Azure Data Lake Storage Gen2、Power BIといった各Azureサービスとの統合が容易であり、さまざまなサービスとの連携が可能です。
2.Azure Databricksの基本的な使い方
今回は、クラスター(計算リソース)作成からデータ取込・加工・可視化までの一連の流れを実行してみます。
<前提条件>
- Azureサブスクリプション・リソースグループを作成している
- Azure Databricksサービスをデプロイしている
※今回のデモではAzure Databricks試用版を利用しています。
クラスター作成
Azure Databricksのホーム画面から「クラスター」を選択し、「コンピューティングを作成」をクリックします。
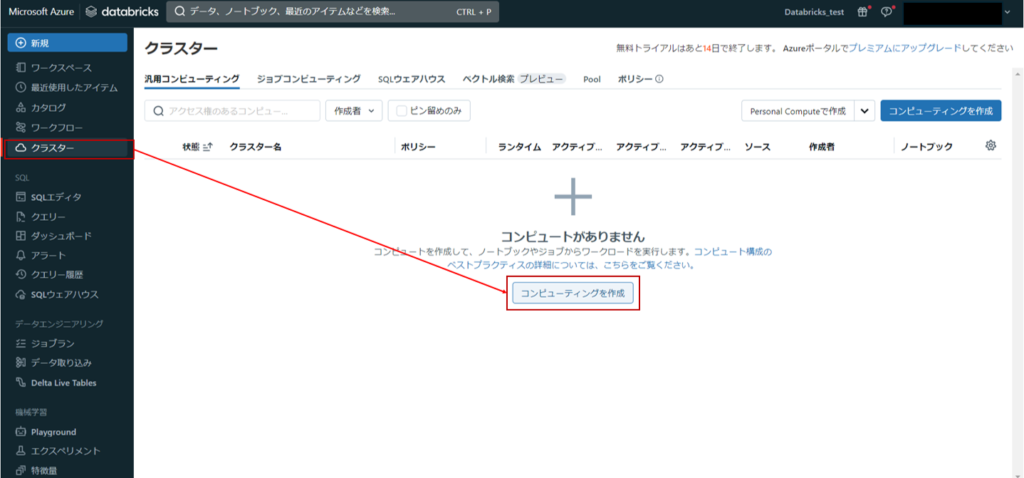
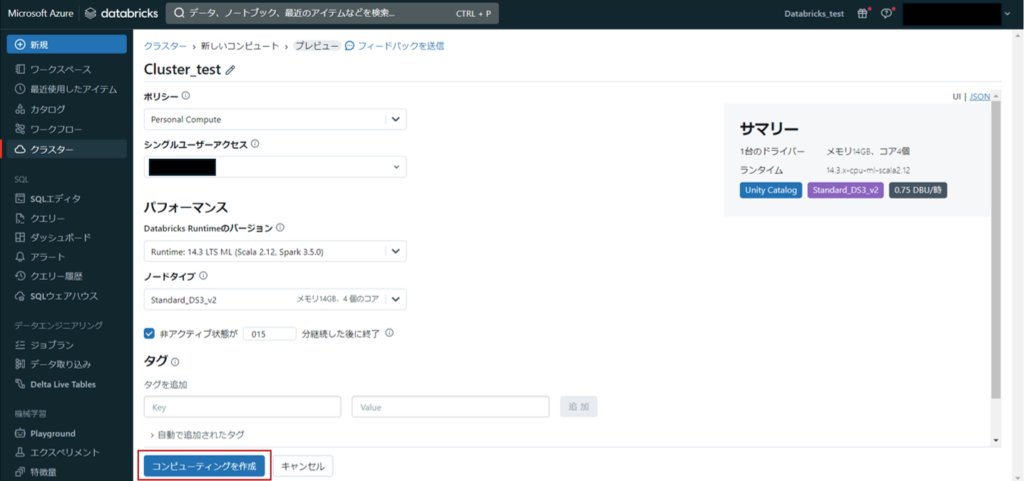
各種設定を行った後、「コンピューティングを作成」をクリックすると、クラスターが作成されます。
データアップロード
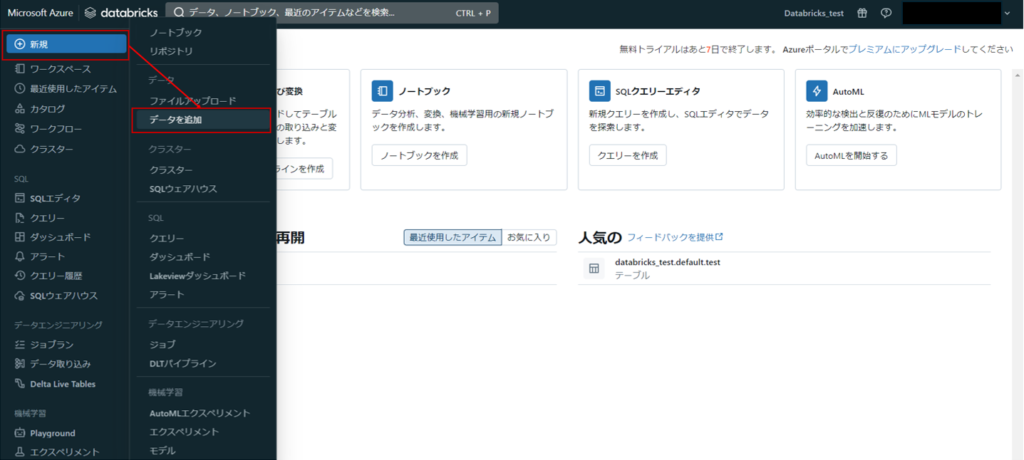
Azure Databricksのホーム画面から「新規」→「データを追加」の順に選択します。
今回は「テーブルを作成または変更」を選択します。
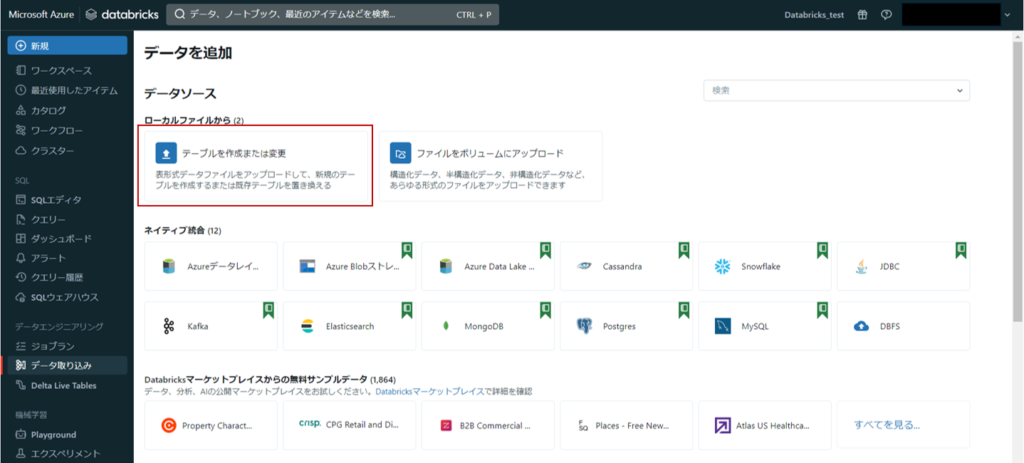
赤枠で囲んだ点線内にテーブル化したいファイルをドロップ、または点線内をクリックしファイルを参照します。
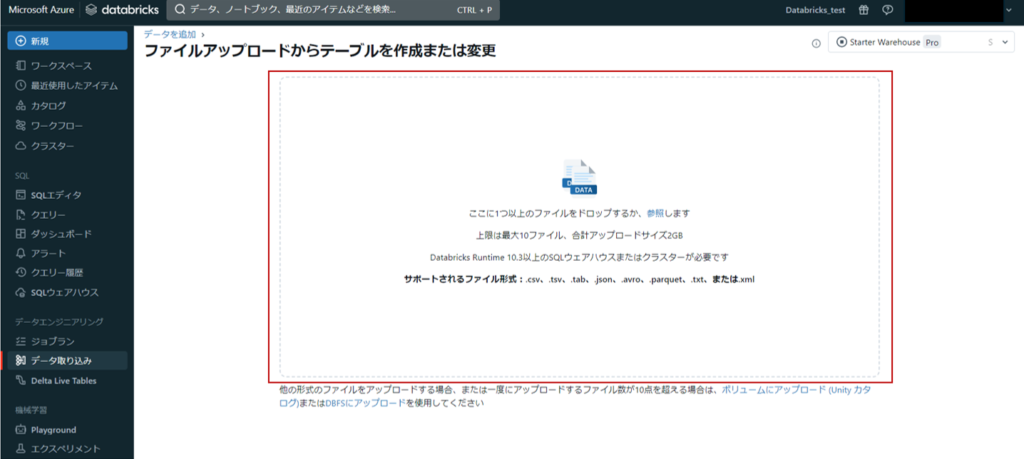
今回はsample.tsvというファイルをアップロードしました。
カタログとスキーマは選択ができ、選択したカタログとスキーマの配下にテーブルが作成されます。
「テーブルを作成」をクリックします。
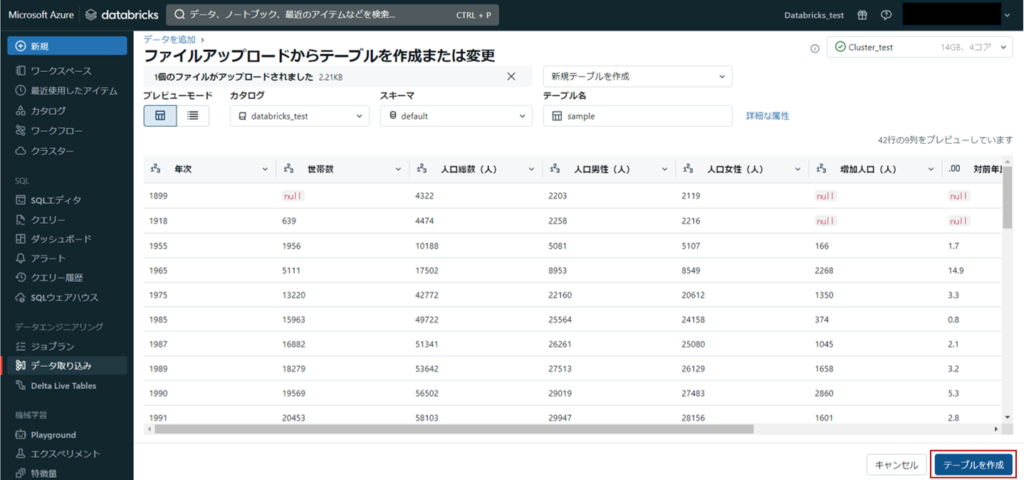
※このサンプルデータは、以下の著作物を改変して利用しています。
稲城市 世帯数及び人口の推移(CSVファイル)、東京都、クリエイティブ・コモンズ・ライセンス 表示4.0国際(https://creativecommons.org/licenses/by/4.0/deed.ja)
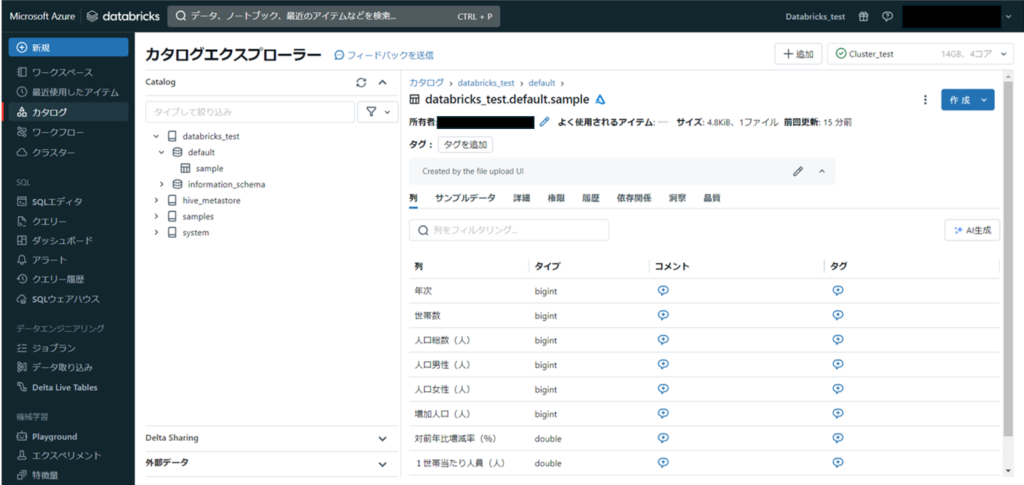
テーブルの作成が開始されます。

sampleテーブルが作成されました。
ノートブック作成・データ加工
Azure Databricksのホーム画面から「新規」→「ノートブック」の順に選択します。
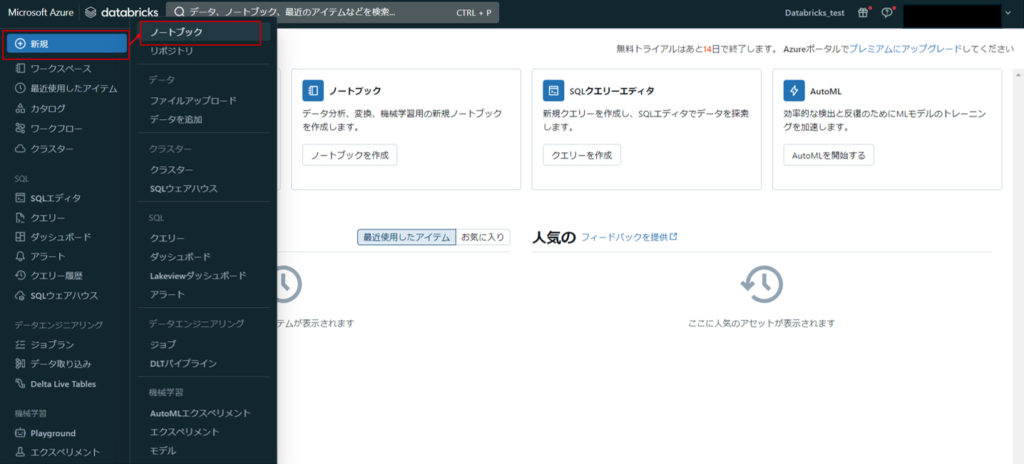
ノートブックが作成されました。
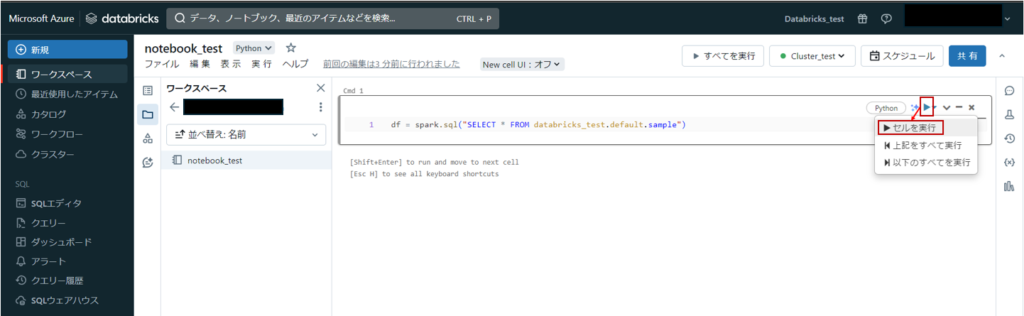
上記で作成したsampleテーブルを読み出してみます。
以下コードをノートブックに記載します。
df = spark.sql("SELECT * FROM databricks_test.default.sample")▶ボタンをクリックするとメニューが表示され、「セルを実行」で処理が実行されます。
セルの実行はshift + enterでも可能です。
実行の際、クラスターが起動していない場合はクラスターの起動待ちとなります。
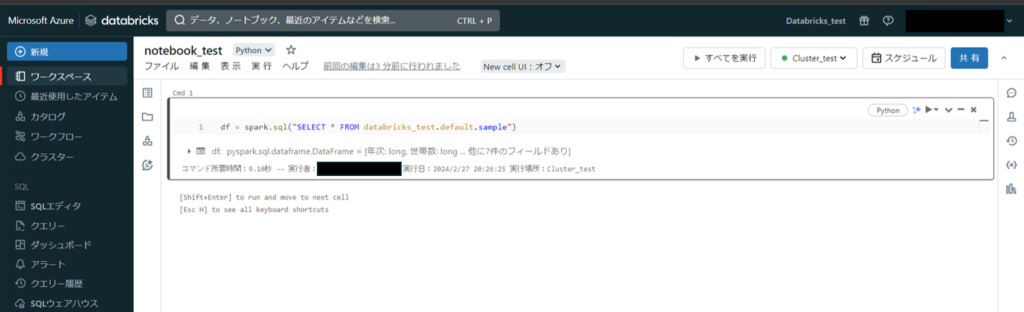
処理が成功しました。
コマンド所要時間・実行者・実行日等が表示されています。
以下コードをノートブックに記載し実行すると、sampleテーブルが表示されます。
display(df)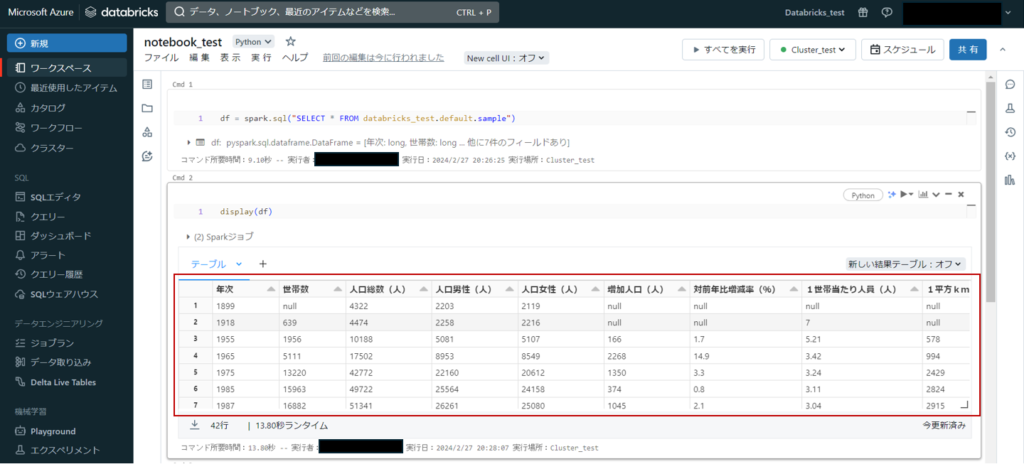
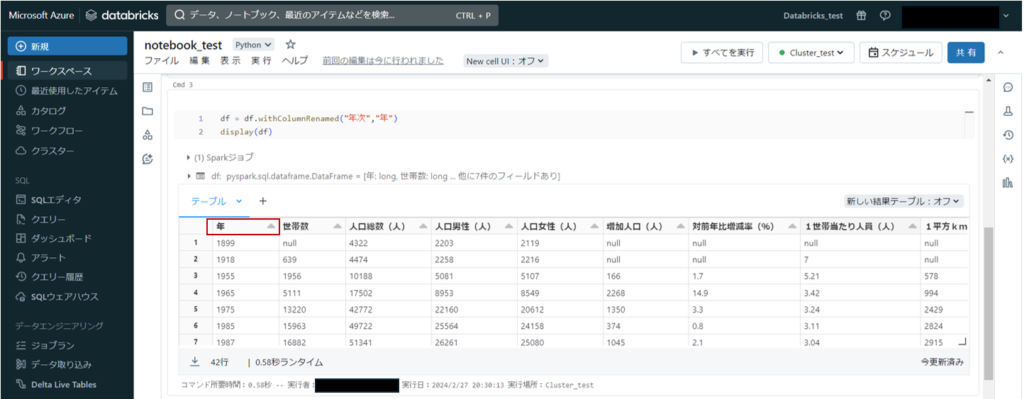
今回はデータ加工の簡単な例として、カラム名を変更してみます。
「年次」カラムを「年」カラムに名称変更します。
以下コードをノートブックに記載し実行します。
df = df.withColumnRenamed("年次","年")
display(df)「年次」カラムが「年」カラムに名称変更されていることが確認できました。
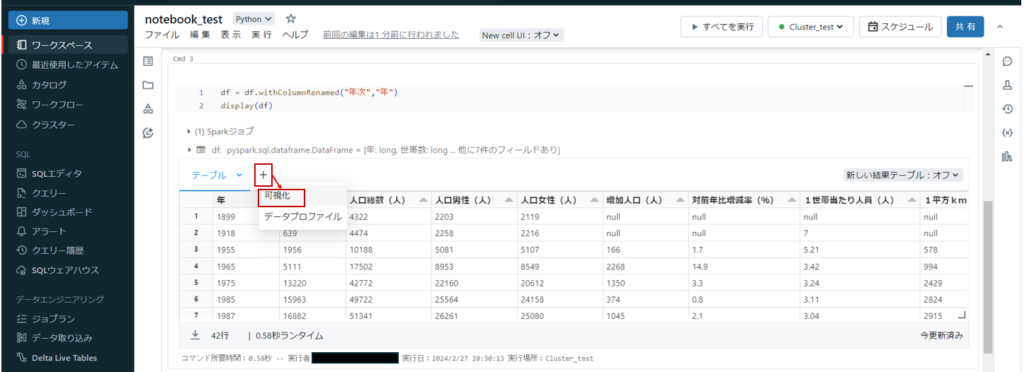
可視化
上記で加工したデータを可視化してみます。
+ボタンをクリックするとメニューが表示されます。
「可視化」をクリックします。
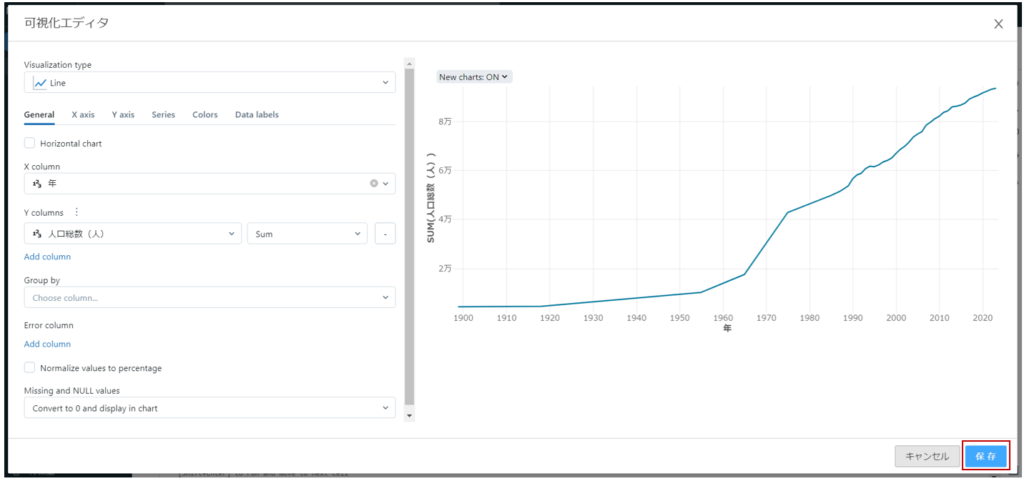
可視化エディタが表示され、可視化タイプ・縦軸・横軸等を選択できます。
画面右側に、可視化プレビューが表示されます。
今回は、線グラフで経年での人口推移グラフを作成します。
「保存」をクリックします。
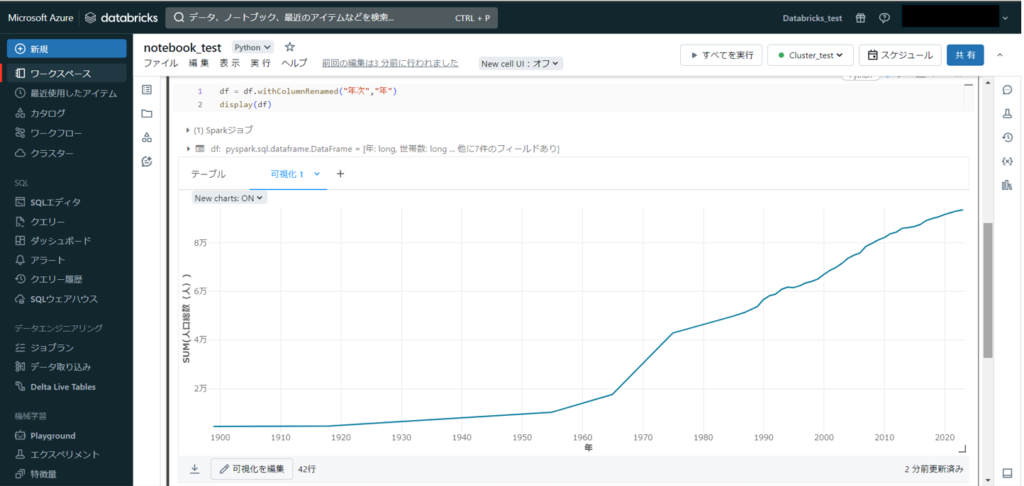
作成したグラフが表示されました。
3.おわりに
Azure Databricksの特長と使用例について紹介しました。
実際に使ってみると、データ蓄積から可視化までをワンストップで行うことができ、とても便利だと感じました。
今回はAzure Databricksサービスのみ使用しましたが、Azure Data Lake Storage Gen2といったストレージサービスからデータを取得し、可視化はPower BIを使用するといった組み合わせによる実装も可能です。
システムエグゼでは、Azure全般の導入・運用支援を行うサービスを展開しています。
Azure Databricks を含めたAzureの導入をご検討の際には、システムエグゼまでお気軽にご相談ください。



