機械学習とBIツールでデータ可視化してみた<実践編>~MotionBoard実装~

データ活用ことはじめ
「BIツールから機械学習を実行し、可視化する」
――社内に眠っているデータを活用し、過去の分析だけにとどまらず、未来を予測する。そんなケースが増えてきました。
機械学習では、裏で膨大な計算をさせるためにチューニングに奮闘したり、デー タベースから機械学習用基盤にデータを送る仕組みを構築したり… メインの機械学習をさせるまでには様々な作業が発生します。
そんな作業を一気に解決してくれるのが「Oracle Autonomous Data Warehouse」 です!
そこで本ブログでは連載形式で、データベースにOracle Cloud の「Autonomous Data Warehouse(以下、ADWと表記)」、BIツールに”ADW対応”、かつ、”豊富な表現力でデータドリブンを可能とする”「MotionBoard」(MB)を使用した、機械学習を検証していきます。
今回は<実践編>~OracleMachineLearning実装~で作成したADW の機械学習をMotionBoard で動かしていきます。
1.検証環境
ADW
Oracle Cloud Free Tierでクラウドアカウントを作成し、ADW を構築
Motion Board
オンプレミス環境 (Windows) に MotionBoard 6.1 をインストール
2.予測テーマ
Kaggle入門として有名な「タイタニック号の生存予測」
https://www.kaggle.com/c/titanic
簡単に分析テーマのおさらい
チケットクラスや性別、年齢などの情報から生存フラグ「Survived」の値を分類の機械学習を使って予測します。
下記、train.csvのデータでモデルを構築し、test.csv(Survivedのカラムが無いデータ)に適用し、予測結果をKaggleに投稿、正解率を確認します。
(以下、画面内の文字が小さく読みにくい場合は、お手数ですがブラウザの拡大率をあげてご覧ください。)
・train.csvの中身

・test.csvの中身

| Passengerid | 変数定義キー |
|---|---|
| Survived | サバイバル0 =いいえ、1 =はい |
| Pclass | チケットクラス1 = 1st、2 = 2nd、3 = 3rd |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢年齢 |
| SibSp | タイタニック号に乗っている兄弟/配偶者の数 |
| Parch | タイタニック号に乗っている親/子供 |
| Ticket | チケット番号 |
| Fare | 運賃乗客運賃 |
| Cabin | キャビン番号 |
| Embarked | 乗船ポートC =シェルブール、Q =クイーンズタウン、S =サウサンプトン |
3.手順
<実践編>~OracleMachineLardning実装~でご紹介した通り、今回実装の機械学習の流れは以下のとおりです。
- モデル作成に使用する説明変数のカラム指定と欠損値補完用にVIEWを作成
- プロシージャ(CREATE_MODEL)でモデルを作成
- SELECT句にPREDICTION関数でモデルを指定
(またはモデル作成時にできあがったテーブルをSELECT)
MotionBoard では ADW に対してプロシージャも SELECT文も実行することができますので、「モデルの作成」も「モデルを使った予測の表示」もできることになります。
プロシージャの設定は下記の手順で行います。
右上の「管理」から、「システム設定」>「接続/認証」>「外部接続」
左側の外部接続から ADW と接続設定をしたものを選び、「プロシージャコール」タブに遷移(接続設定方法は<構築編>参照)
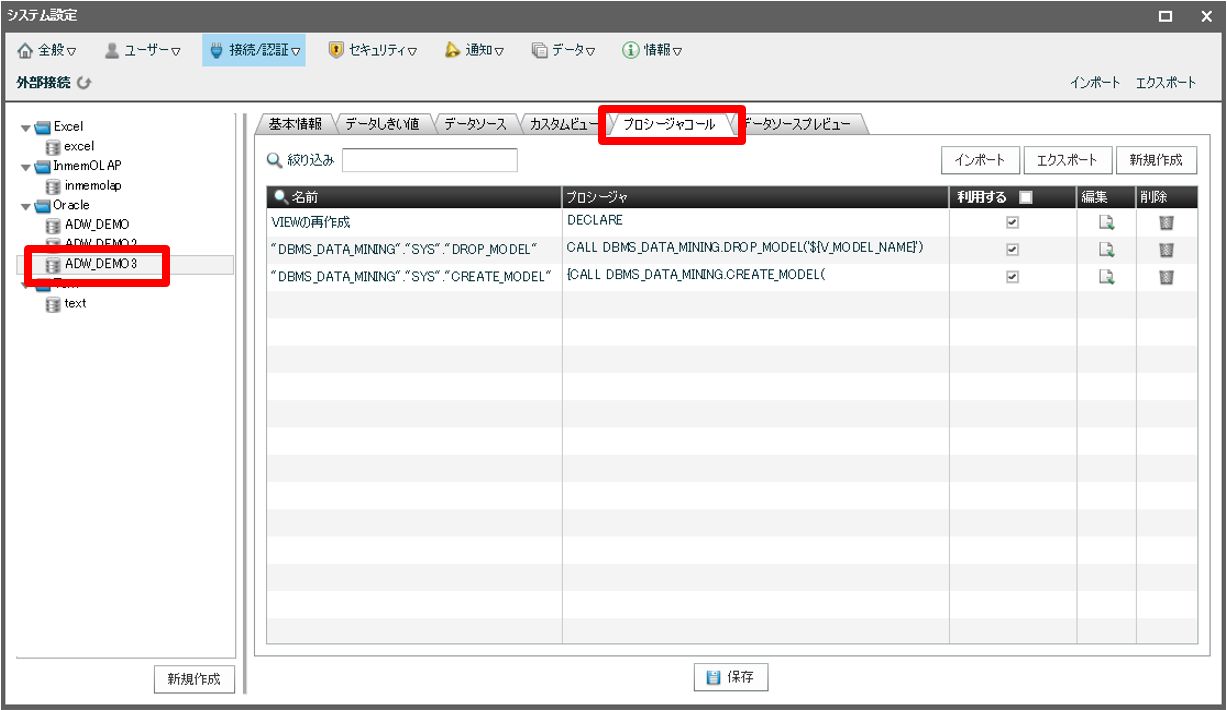
サンプルとして一つ記載いたします。
-- 設定名:"DBMS_DATA_MINING"."SYS"."DROP_MODEL"(モデル削除)
BEGIN
DBMS_DATA_MINING.DROP_MODEL('${MODEL_NAME}');
END;
ここでOracle上の実行と違うのが、MotionBoard内の変数「${システム変数名}」をスクリプトに埋め込んでいるところです。
次にモデルを実行する SELECT文を「カスタムビュー」タブで設定していきます。
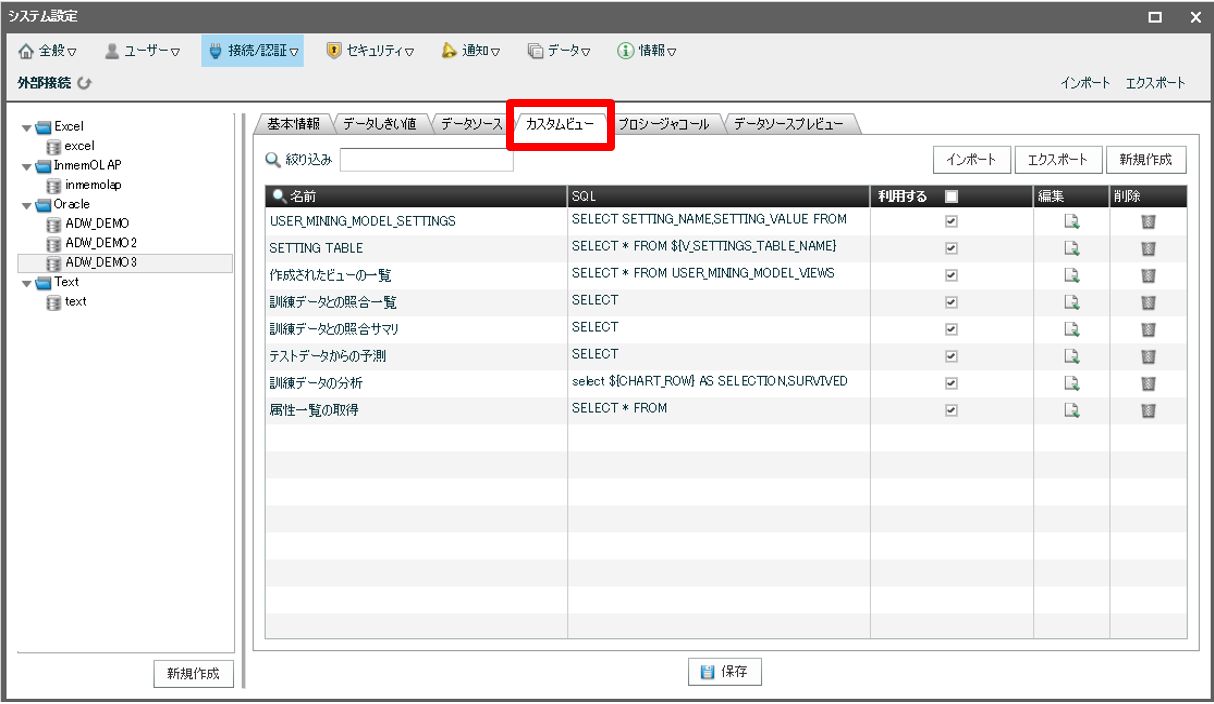
サンプルとして一つ記載します。
こちらにも今回、モデル名として MotionBoard のシステム変数を埋め込んでいます。
SELECT SETTING_NAME, SETTING_VALUE FROM USER_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = '${MODEL_NAME}'
それでは早速、上記で設定したプロシージャコールとカスタムビューを使用して、チャートや明細を作成していきます!
今回作成した画面は下記の4種類です。
【タブ1】訓練データ
まず、モデルを作成するための訓練データを分析するための画面です。
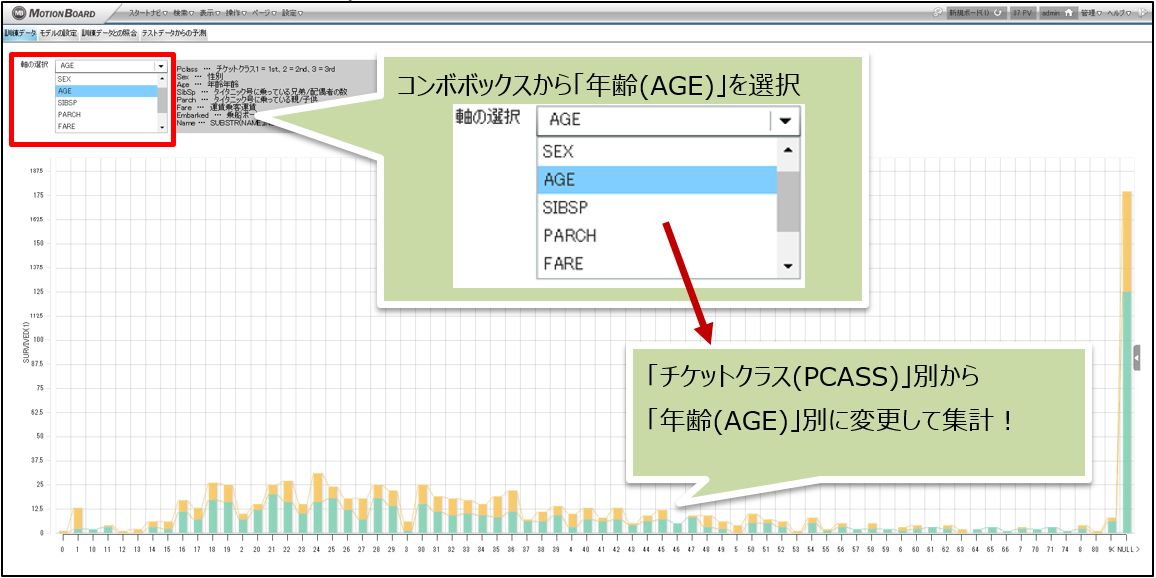
説明変数になり得そうな軸を左上のコンボボックスから選択し、目的変数「SURVIVED」の1と0を積み上げ棒グラフで表示しています。
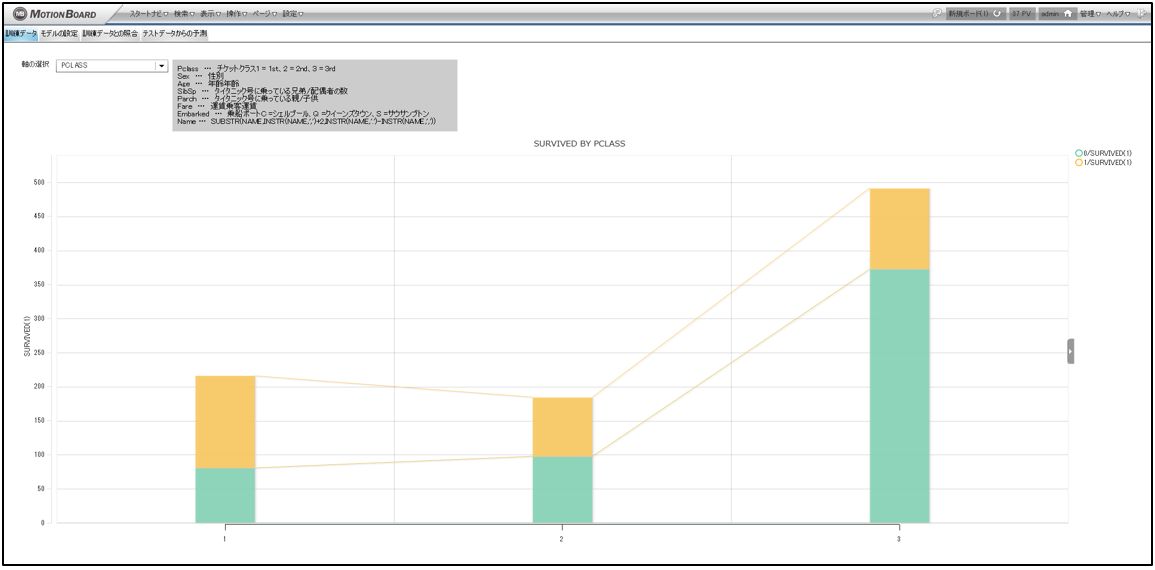
コンボボックスでは「PCLASS」「SEX」「AGE」「SIBSP」「PARCH」「FARE」「EMBARKED」「NAME」を選択できるようにしています。
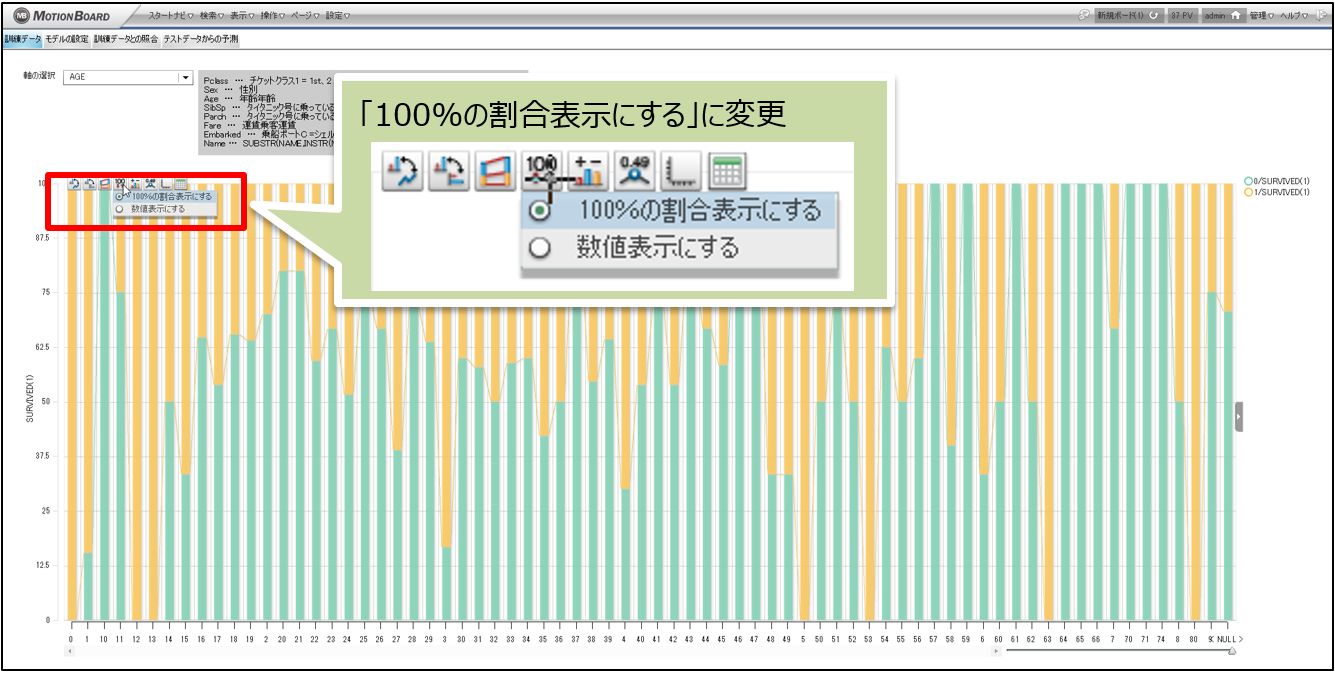
MotionBoard のチャート機能で100%積み上げにも簡単に変更可能です。
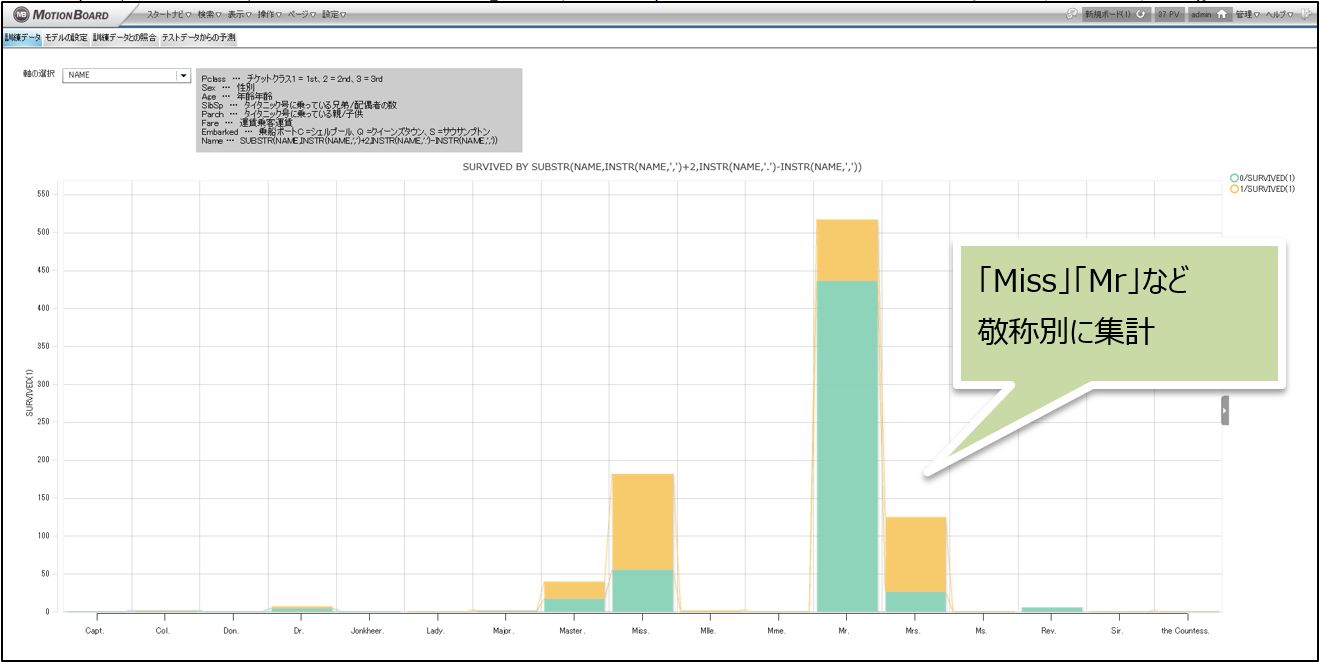
なお、今回のチャートでは「NAME」はすべて、 “Miss” や “Mr” を切り取って取り扱っています。
画面の裏で実行されている SQL は下記です。
SELECT ${CHART_ROW} AS SELECTION, SURVIVED FROM TITANIC_TRAIN
【タブ2】モデルの設定
次に、モデルを作成する画面です。
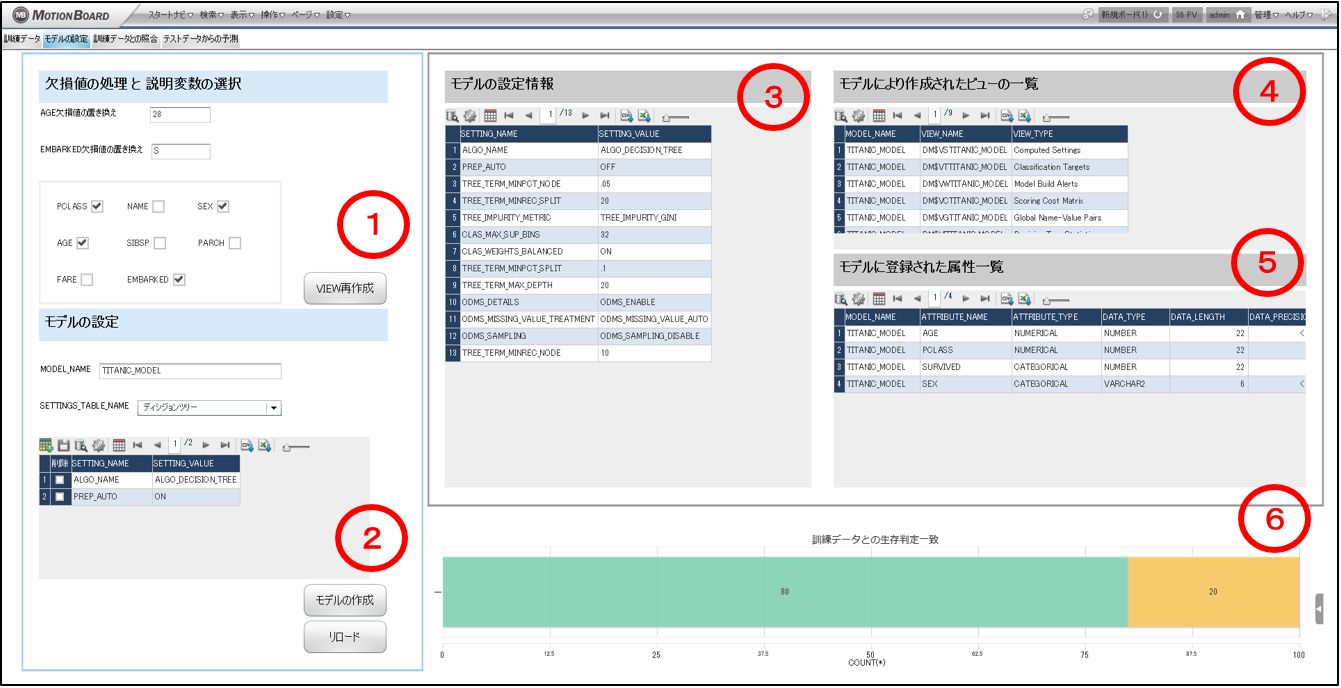
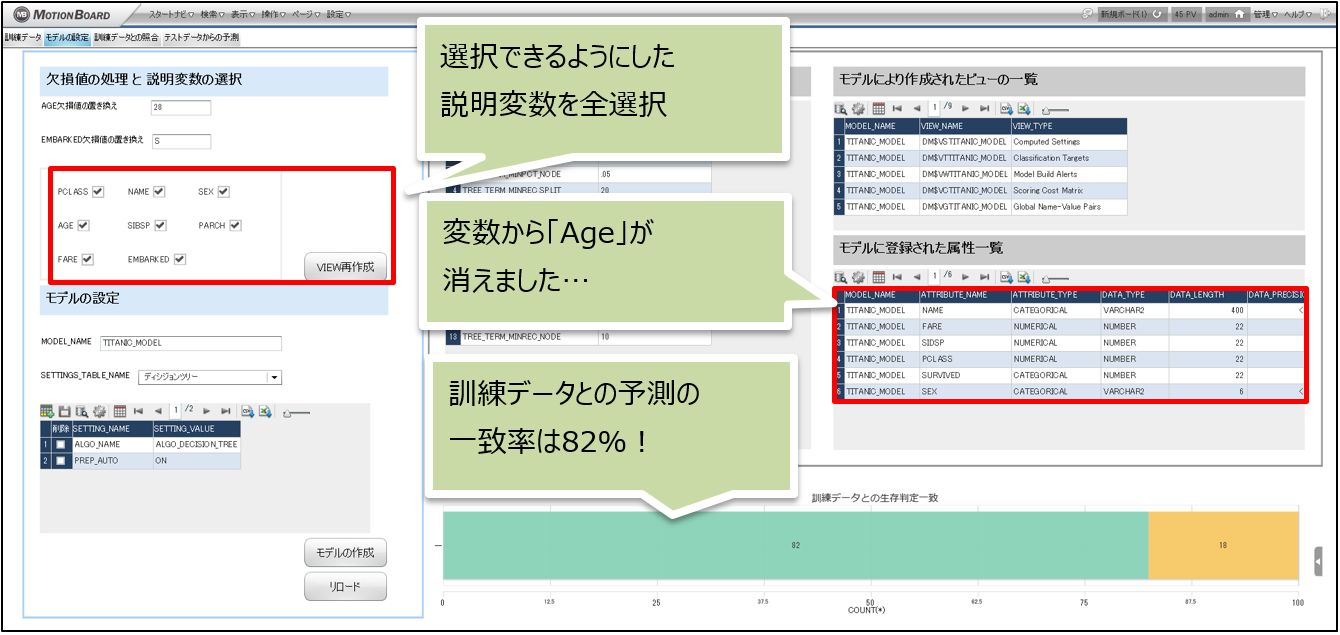
①欠損値の処理と説明変数の選択
モデル作成時に参照させるVIEWの定義を作り変える操作が可能です。
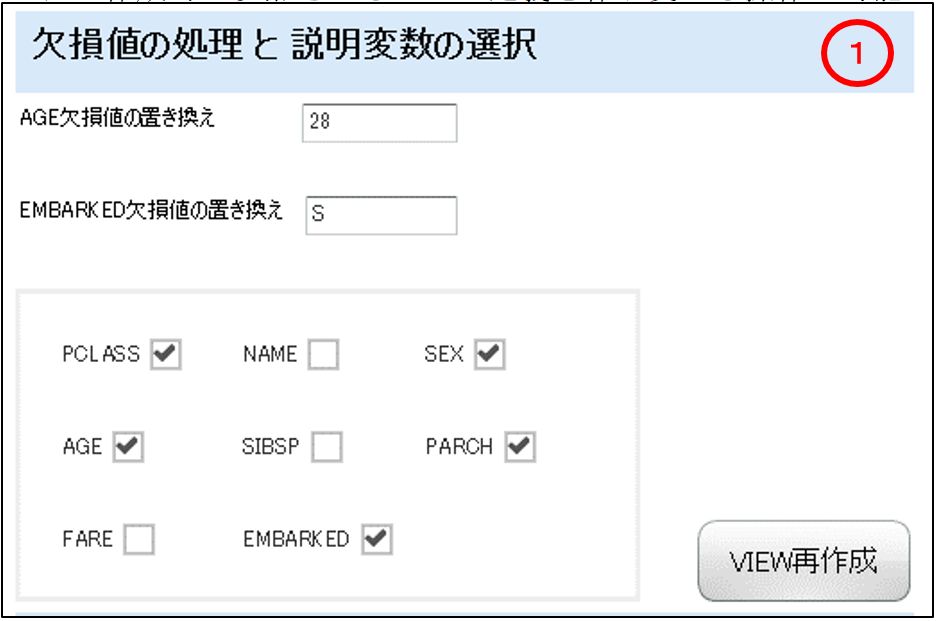
発行SQLはプロシージャコールで設定の下記です。
-- 設定名:VIEWの再作成
DECLARE
VSQL VARCHAR2(1000);
BEGIN
VSQL:='CREATE OR REPLACE VIEW V_TITANIC_TRAIN AS SELECT PASSENGERID ,SURVIVED ${SELECT_PCLASS} ${SELECT_NAME} ${SELECT_SEX} ${SELECT_AGE} ${SELECT_SIBSP} ${SELECT_PARCH} ${SELECT_FARE} ${SELECT_EMBARKED} FROM TITANIC_TRAIN';
EXECUTE IMMEDIATE VSQL;
VSQL:='CREATE OR REPLACE VIEW V_TITANIC_TEST AS SELECT PASSENGERID ${SELECT_PCLASS} ${SELECT_NAME} ${SELECT_SEX} ${SELECT_AGE} ${SELECT_SIBSP} ${SELECT_PARCH} ${SELECT_FARE} ${SELECT_EMBARKED} FROM TITANIC_TEST';
EXECUTE IMMEDIATE VSQL;
END;
②モデルの設定、③モデルの設定情報
モデル名の指定、モデルに使用するアルゴリズム情報を含む SETTINGS_TABLE を画面から編集しながらモデルを作成することが可能です。
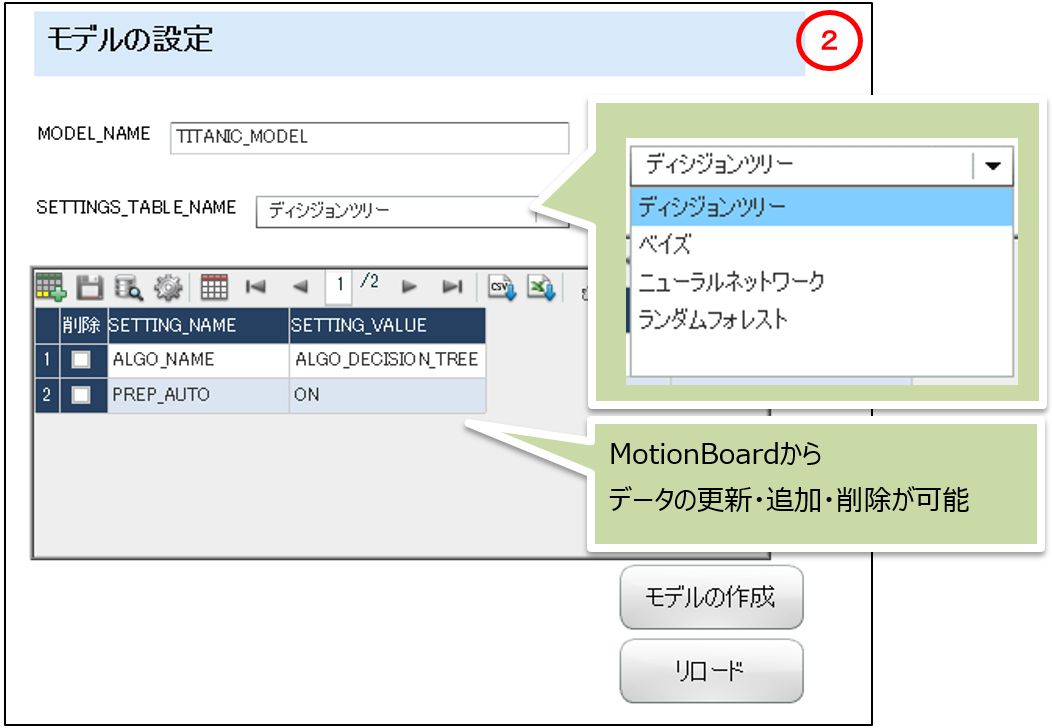
SETTINGS_TABLE の SETTING_NAME の一覧は「③モデルの設定情報」で確認ができます。
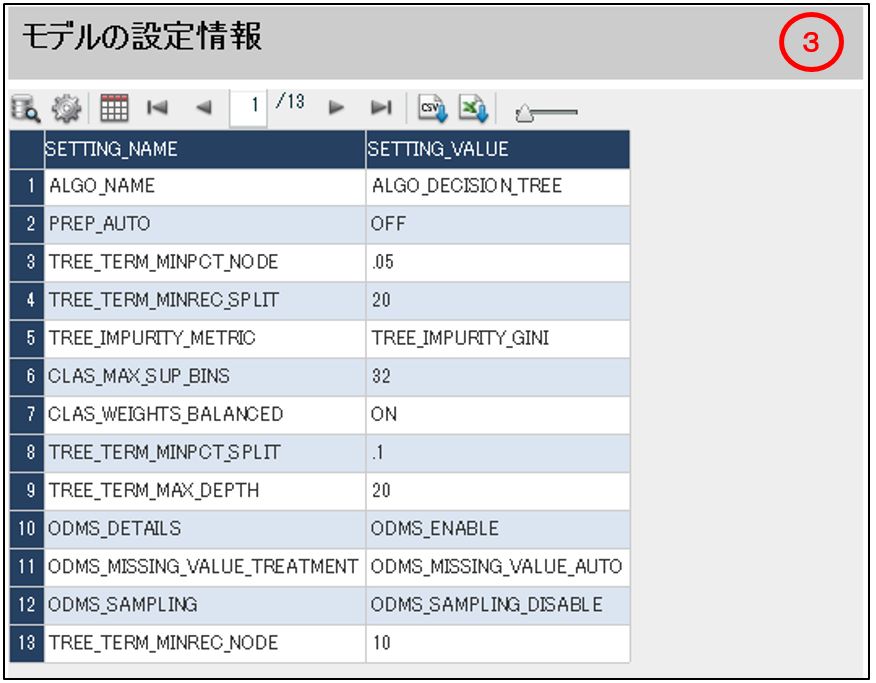
発行 SQL は下記です。
・「モデルの作成」から呼び出されるプロシージャコール
-- 設定名:"DBMS_DATA_MINING"."SYS"."DROP_MODEL"(モデルの削除)
CALL DBMS_DATA_MINING.DROP_MODEL('${MODEL_NAME}')
-- 設定名:"DBMS_DATA_MINING"."SYS"."CREATE_MODEL"(モデルの作成)
{CALL DBMS_DATA_MINING.CREATE_MODEL(
MODEL_NAME => '${MODEL_NAME}',
MINING_FUNCTION => DBMS_DATA_MINING.CLASSIFICATION,
DATA_TABLE_NAME => 'V_TITANIC_TRAIN',
TARGET_COLUMN_NAME => 'SURVIVED',
CASE_ID_COLUMN_NAME => 'PASSENGERID',
SETTINGS_TABLE_NAME => '${SETTINGS_TABLE_NAME}')
}
・SETTINGS_TABLE
コンボボックス「ディシジョンツリー」「ベイズ」「ニューラルネットワーク」「ランダムフォレスト」それぞれに対応するテーブルを用意し、テーブルの情報を全行表示を行います。
ディシジョンツリー用:SELECT * FROM SETTING_DT
ベイズ用:SELECT * FROM SETTING_B
ニューラルネットワーク用:SELECT * FROM SETTING_NN
ランダムフォレスト:SELECT * FROM SETTING_RF
「モデルの設定情報」に表示させているSQL(カスタムビュー)は下記です。
SELECT SETTING_NAME,SETTING_VALUE FROM USER_MINING_MODEL_SETTINGS
WHERE MODEL_NAME = '${MODEL_NAME}'
④モデルにより作成されたビューの一覧
モデルを作成したときに Oracle が自動で作成するビューの一覧を表示します。
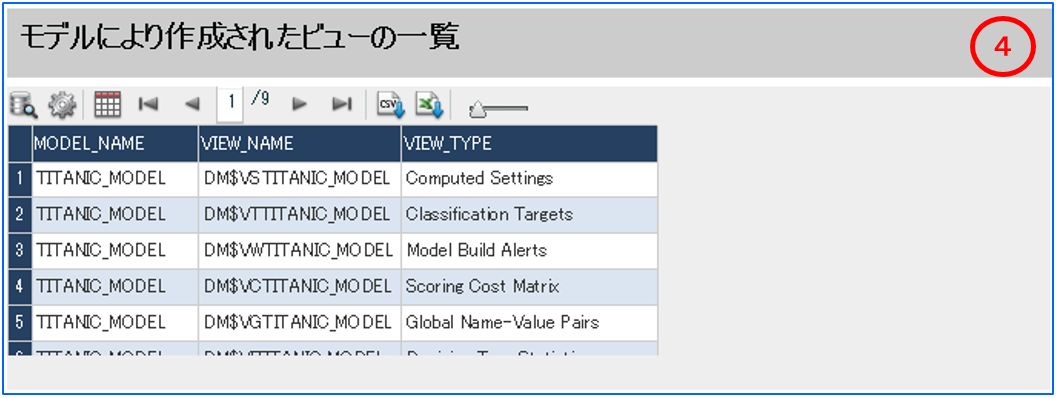
・「モデルにより作成されたビューの一覧」に表示させているSQL(カスタムビュー)
SELECT * FROM USER_MINING_MODEL_VIEWS WHERE MODEL_NAME = '${MODEL_NAME}'
VIEW_NAME カラムにある VIEW の中身は下記のような内容です。
ディシジョンツリーのノードの中身などが確認できます。
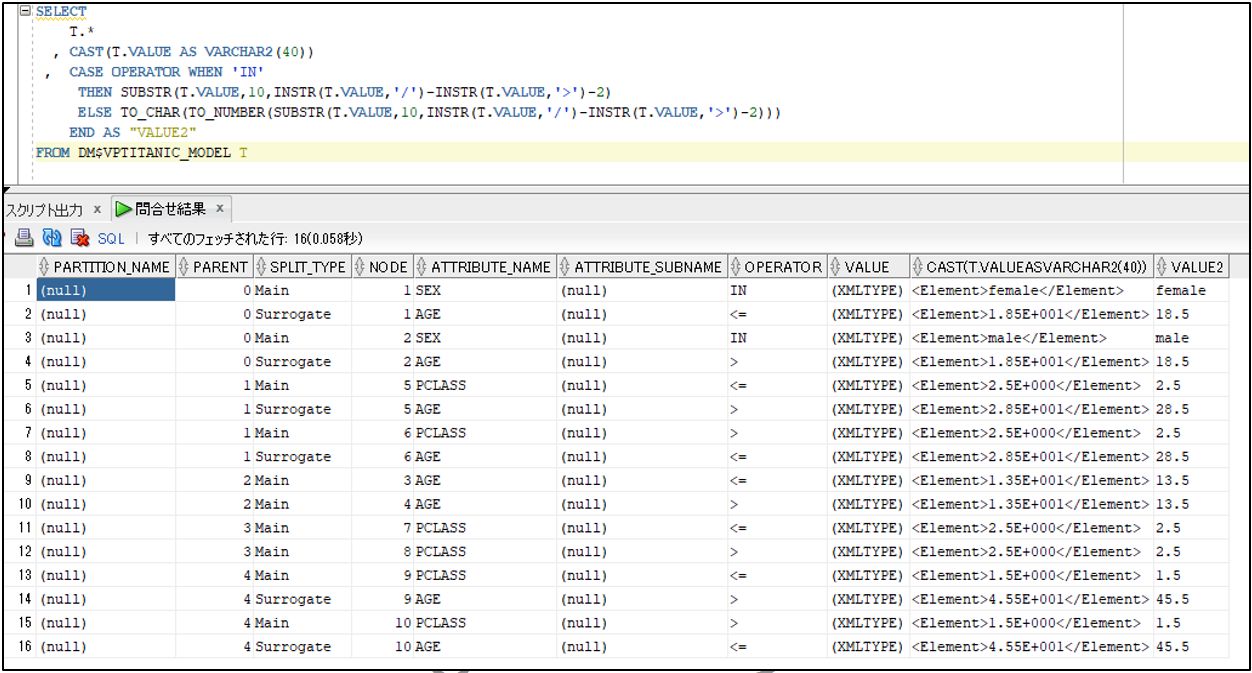
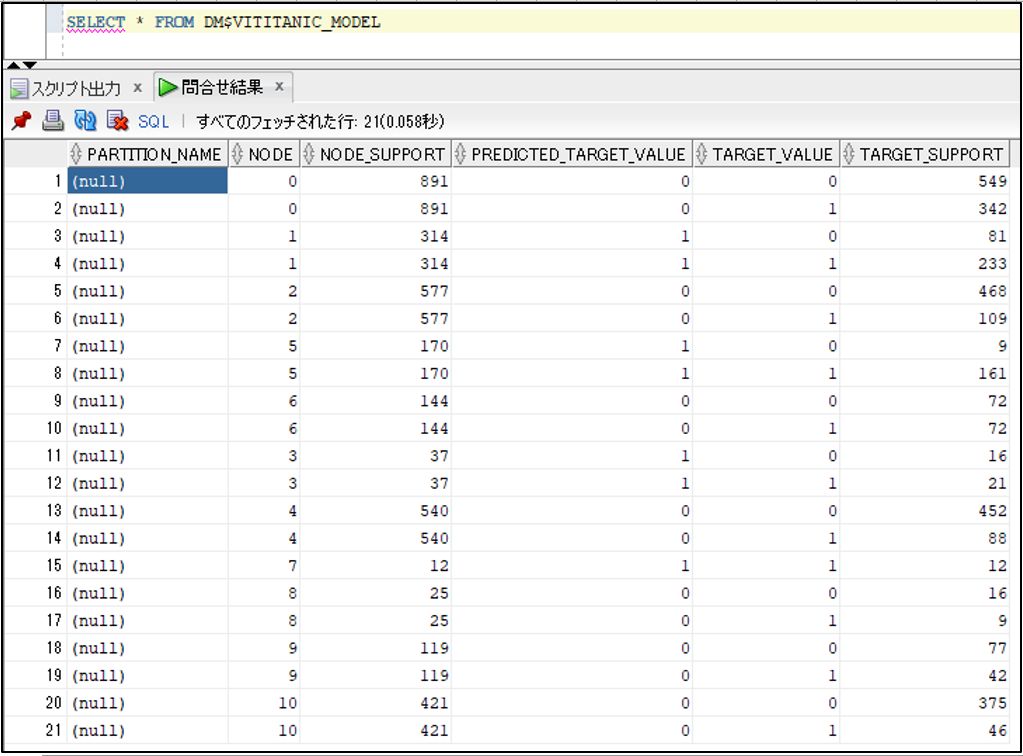
上記の情報を使って、ディシジョンツリーをMotionBoardで可視化することも可能です。
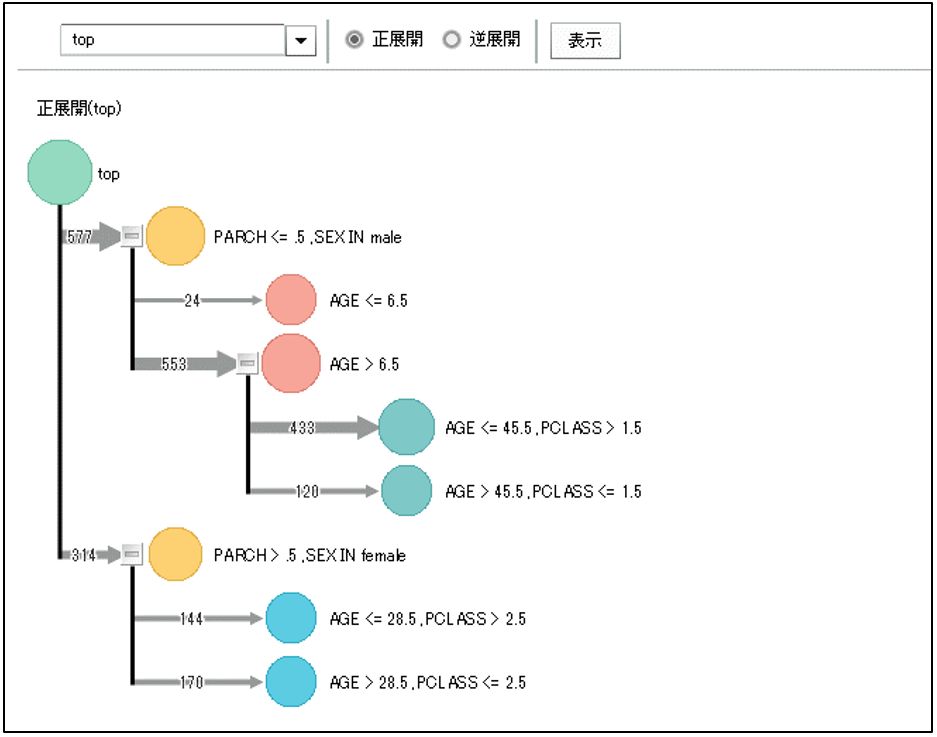
⑤モデルに登録された属性一覧
モデルに寄与している説明変数と目的変数の一覧を表示しています。

「EMBARKED」はモデル作成時に画面でチェックをつけましたが、ここに表示されていないので予測に使用しないと判断されたようです。
確かに④で確認した「DM$VPTITANIC_MODEL」や「DM$VITITANIC_MODEL」にも出てきていません。
・「モデルに登録された属性一覧」に表示させているSQL(カスタムビュー)
SELECT * FROM USER_MINING_MODEL_ATTRIBUTES WHERE MODEL_NAME = '${MODEL_NAME}'
⑥訓練データとの生存判定一致
訓練データと「SURVIVED」と機械学習で予測した「SURVIVED」の一致比率を表示しています。

・「訓練データとの生存判定一致」に表示させているSQL(カスタムビュー)
SELECT
COUNT(*),
CASE
WHEN SURVIVED = PREDICTION THEN '一致'
ELSE '不一致'
END AS MATCH
FROM
(
SELECT
TRAIN.*,
PREDICTION(${MODEL_NAME} USING TRAIN.*) AS PREDICTION,
PREDICTION_PROBABILITY(${MODEL_NAME} USING TRAIN.*) AS PREDICTION_PROBABILITY
FROM
V_TITANIC_TRAIN TRAIN
) SUB
GROUP BY
CASE
WHEN SURVIVED = PREDICTION THEN '一致'
ELSE '不一致'
END
【タブ3】訓練データとの照合
続いて、訓練データと予測した値を分析する画面です。
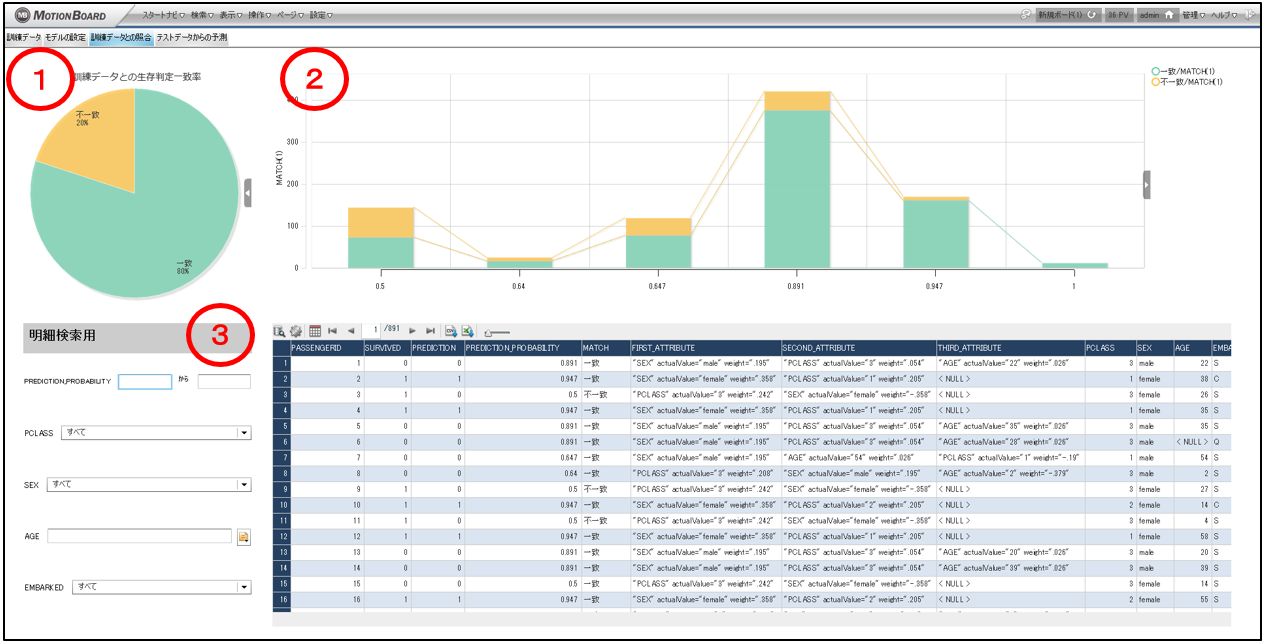
①訓練データとの生存判定一致率
こちらは前画面に表示した棒グラフを円グラフにしたものです。
②PREDICTION_PROBABOLITY(予測に対する確立)
③の明細の予測に対する確率ごとのデータ分布を棒グラフで表したものです。
③訓練データと予測値・予測に対する確率・詳細
訓練データに下記のカラムを追加し、表示しています。
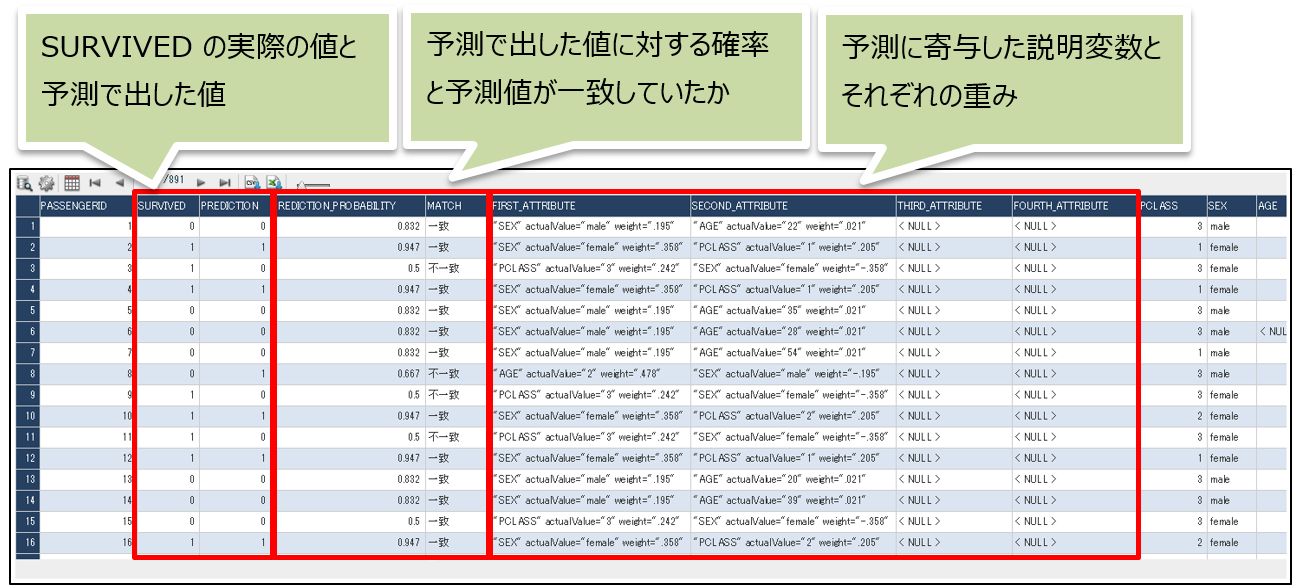
・上記明細に表示させているSQL(カスタムビュー)
SELECT
SUB.PASSENGERID,
SUB.SURVIVED,
SUB.PCLASS,
SUB.NAME,
SUB.SEX,
SUB.AGE,
SUB.SIBSP,
SUB.PARCH,
SUB.TICKET,
SUB.FARE,
SUB.CABIN,
SUB.EMBARKED,
SUB.PREDICTION,
SUB.PREDICTION_PROBABILITY,
CASE
WHEN SURVIVED = PREDICTION THEN '一致'
ELSE '不一致'
END AS MATCH,
RTRIM(TRIM(SUBSTR(OUTPRED."Attribute1",17,100)),'rank="1"/>') FIRST_ATTRIBUTE,
RTRIM(TRIM(SUBSTR(OUTPRED."Attribute2",17,100)),'rank="2"/>') SECOND_ATTRIBUTE,
RTRIM(TRIM(SUBSTR(OUTPRED."Attribute3",17,100)),'rank="3"/>') THIRD_ATTRIBUTE,
RTRIM(TRIM(SUBSTR(OUTPRED."Attribute4",17,100)),'rank="4"/>') FOURTH_ATTRIBUTE
FROM
(
SELECT
ORG.*,
PREDICTION(${MODEL_NAME} USING TRAIN.*) AS PREDICTION,
ROUND(TO_NUMBER(PREDICTION_PROBABILITY(${MODEL_NAME} USING TRAIN.*)),3) AS PREDICTION_PROBABILITY,
PREDICTION_DETAILS(${MODEL_NAME} USING TRAIN.*) AS PREDICTION_DETAILS
FROM
V_TITANIC_TRAIN TRAIN
JOIN
TITANIC_TRAIN ORG
ON
TRAIN.PASSENGERID = ORG.PASSENGERID
) SUB
,
XMLTABLE('/Details'
PASSING SUB.PREDICTION_DETAILS
COLUMNS
"Attribute1" XMLType PATH 'Attribute[1]',
"Attribute2" XMLType PATH 'Attribute[2]',
"Attribute3" XMLType PATH 'Attribute[3]',
"Attribute4" XMLType PATH 'Attribute[4]') OUTPRED
【タブ4】テストデータからの予測
最後に、Kaggle へ投稿する用に、テストデータを予測した結果を CSV ダウンロードする画面です。
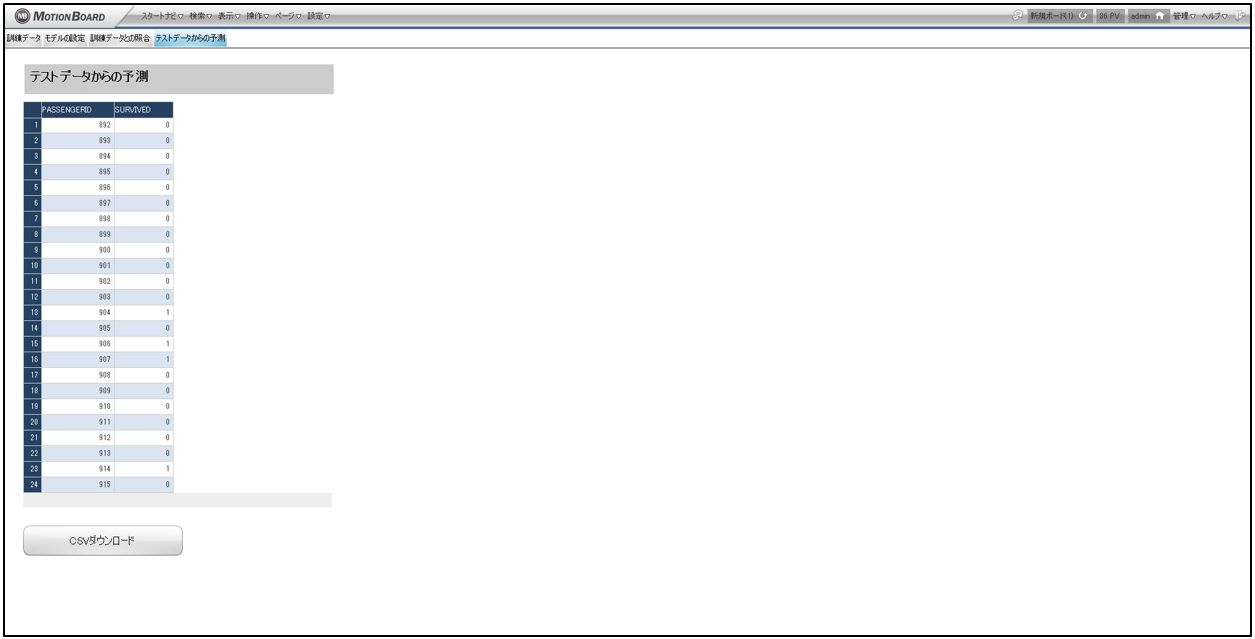
・上記明細に表示させているSQL(カスタムビュー)
SELECT
PASSENGERID,
PREDICTION(${MODEL_NAME} USING *) AS SURVIVED
FROM V_TITANIC_TEST TEST
4.作ったボードの操作(モデルの作成と検証)
試しに何個か画面からモデルを作ってみたいと思います!
モデルパターン1:ディシジョンツリーで説明変数をすべて選択
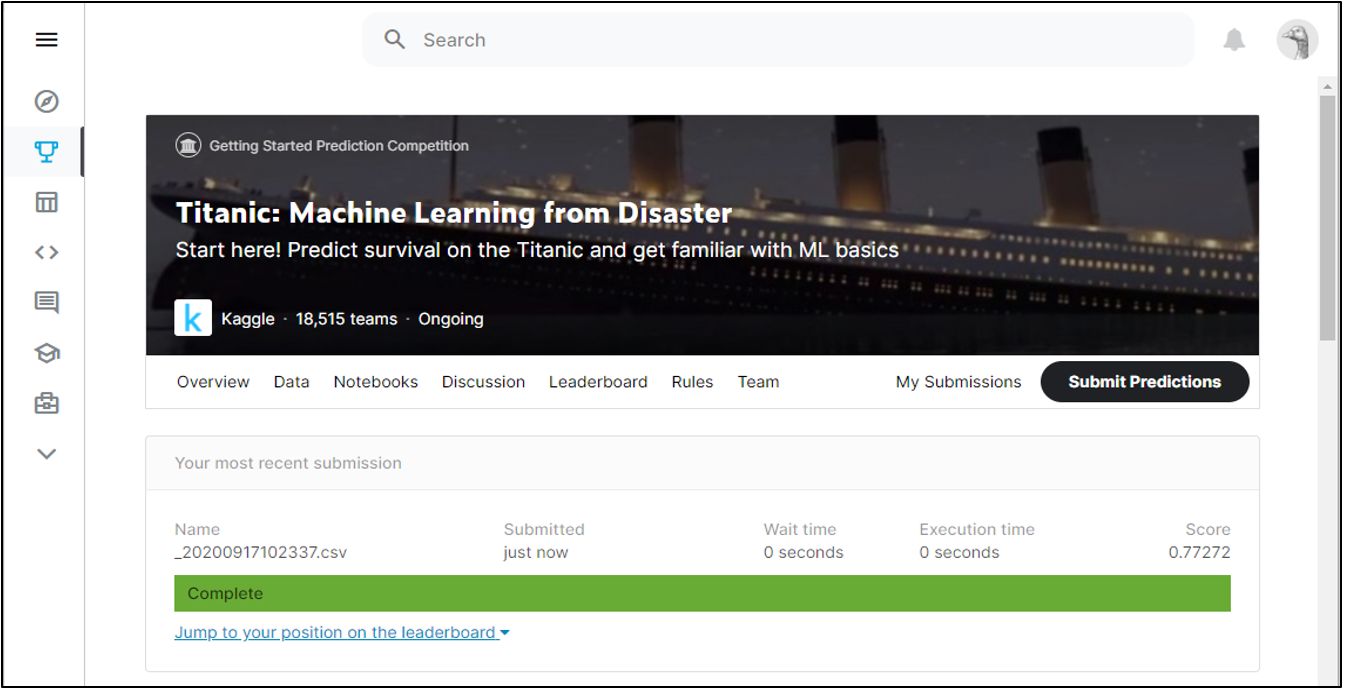
スコアは「0.77272」
訓練データとの一致率は82%だったので少し訓練データへの適合に寄ったモデルになっています。
そこで次に、決定木の深さの階層を浅くしてモデルを簡易化してみます。
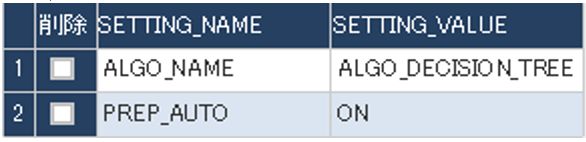
モデルパターン2:ディシジョンツリーで階層を浅くする
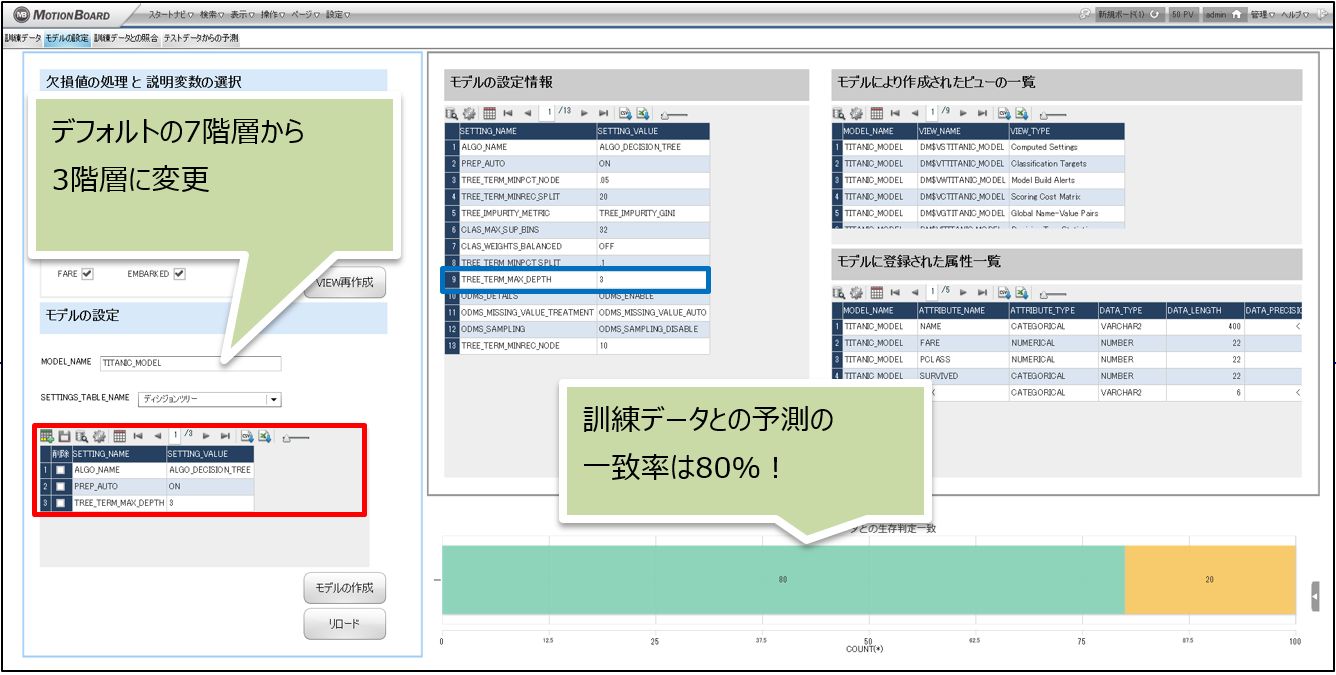
SETTINGS_TABLEの中身を上記のように変更します。
ADWのテーブルの「行の挿入」「データの更新」「行の削除」がMotionBoardの画面からできてしまうので設定変更がとっても簡単です!
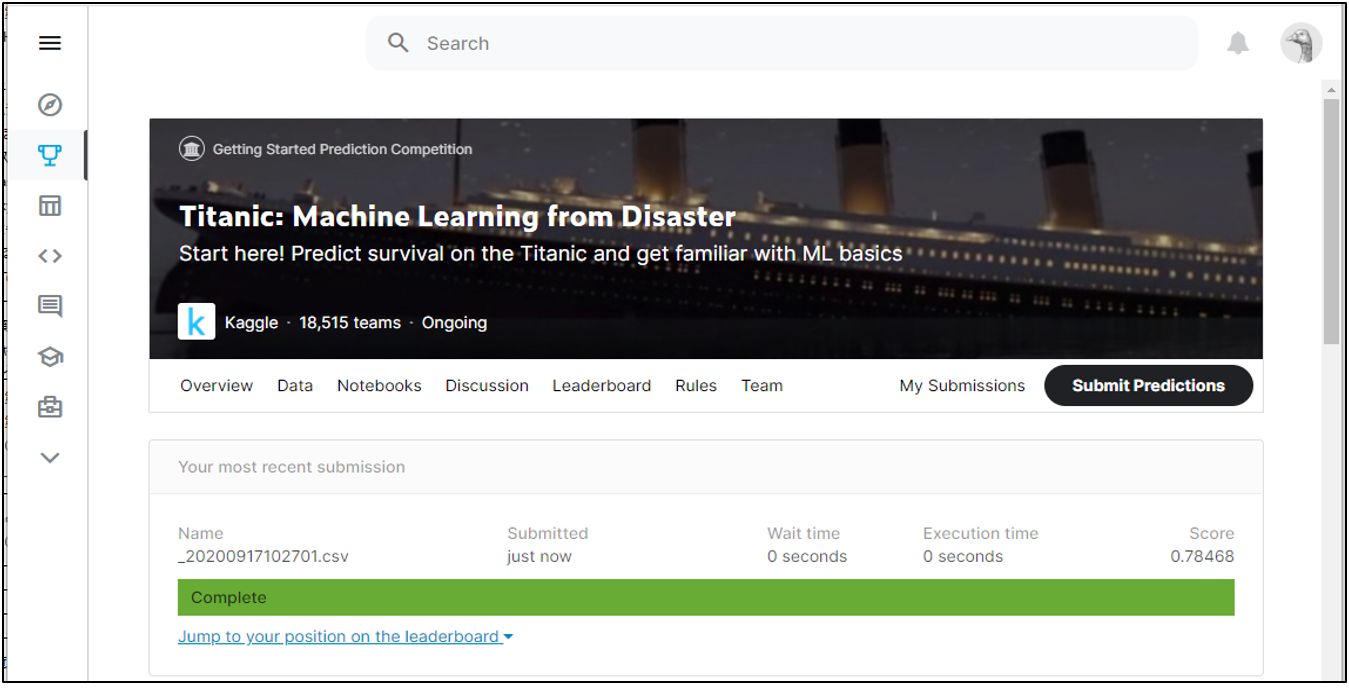
スコアは「0.78468」
少しあがりました。続いて、違うアルゴリズムでモデルを作ってみます。
モデルパターン3:ランダムフォレストのアルゴリズムを使う
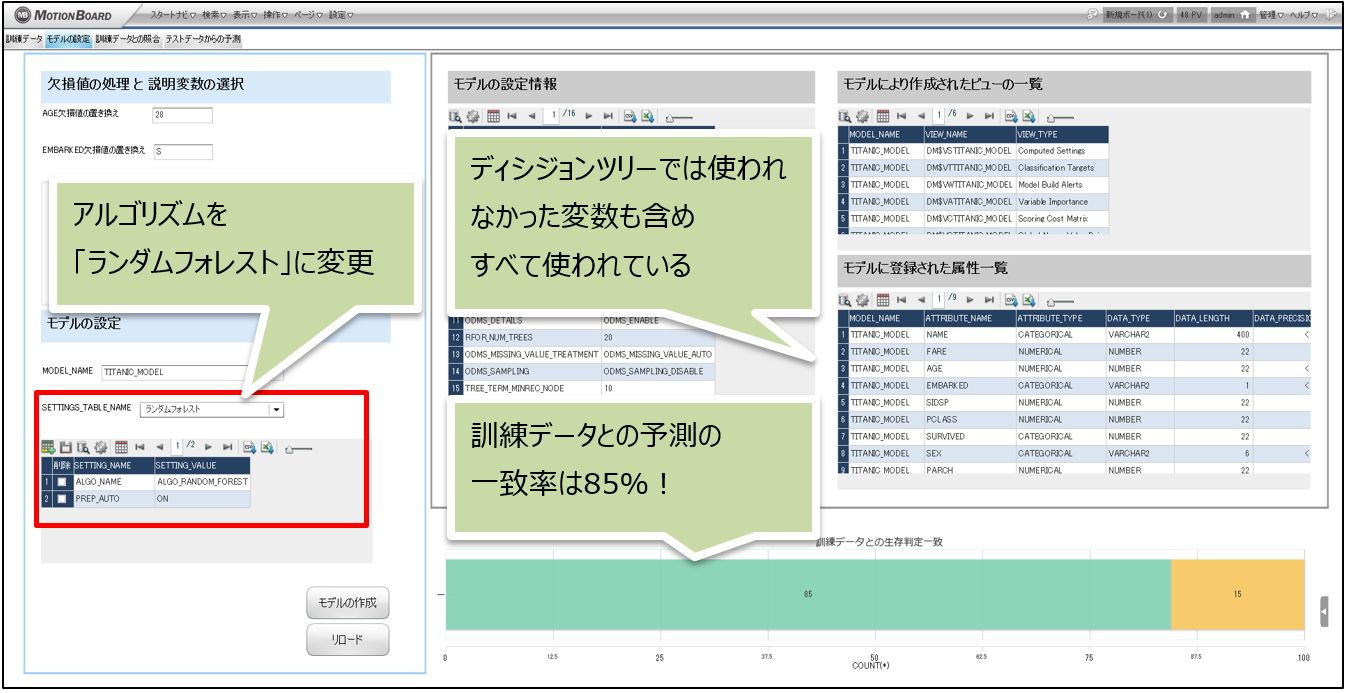

スコアは「0.78229」でした。
デフォルト設定のディシジョンツリーより若干良いくらいですね。
さいごに
今回は、MotionBoardから機械学習のモデルの構築や設定変更ができる画面を実装してみました。
もちろん、大量データでモデルを作る場合には時間がかかりますので、あらかじめ ADW 側でモデルを作成しておいて、MotionBoard からはモデルの参照だけにするなど色々な使い方ができます。
ADWとMotionBoardの機械学習チュートリアルのような内容でしたので、設定用テーブルなど明細アイテムをたくさん配置したチャートになってしまいましたが、次回はもう少しビジネスに近いデータを使用して、「チャートによる可視化」にフォーカスしたレポートを披露できればと思います!










