Pythonを使って簡単データ分析-初級編

データ活用ことはじめ
Pythonには様々なライブラリがあります。
本ブログでは、主にPandasライブラリで簡単なデータ解析を行う方法をご紹介します。
今回は、普段Excelで扱う表データをPandasでデータ分析しました。
大量のデータを計算処理、分析処理する場合は、Pythonの方が高速かつ正確にできるというメリットがあります。
本ブログでは、AnacondaというPythonプラットフォームの中のJupyter Notebookを用いて開発していますが、AnacondaにはPythonだけではなく色々な数値計算やデータ解析ツールがあり、とても便利です。
1.Pandasの導入およびデータの読み込み
①Pandasの導入
Jupyter NotebookでPython3(ipykernel)を新規作成し、下記の通りにコードを入力し実行します。

次のセルにカーソルが移ればPandasの導入は成功です。
エラーメッセージが出る場合は、AnacondaがCドライブ以外の場所にインストールされていることが一因である場合があるので、ご確認ください。
②データの読み込み
Jupyter Notebookでは、ExcelファイルやCSVファイルのほか、テキストファイルの読み込みも可能です。
今回はこちらで作成した作業用のExcelファイルを使って読み込んでいきたいと思います。
(データはすべてRAND関数で生成されたもの)
読み込みデータの中身は以下の通りです。
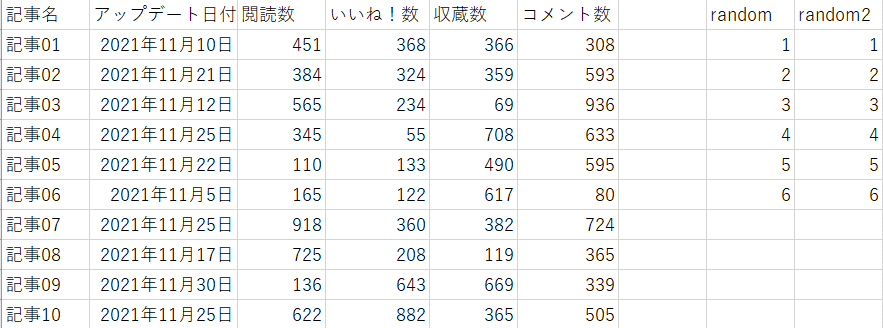
df=pd.read_excel(r"…/Example.xlsx")
・ダブルクォーテーションに囲まれている部分は読み込みファイルのフルパスです。
・CSVファイルの場合はpd.read_csvを入力します。
新規セルに上記のコードを入力し実行すると、このようになります。
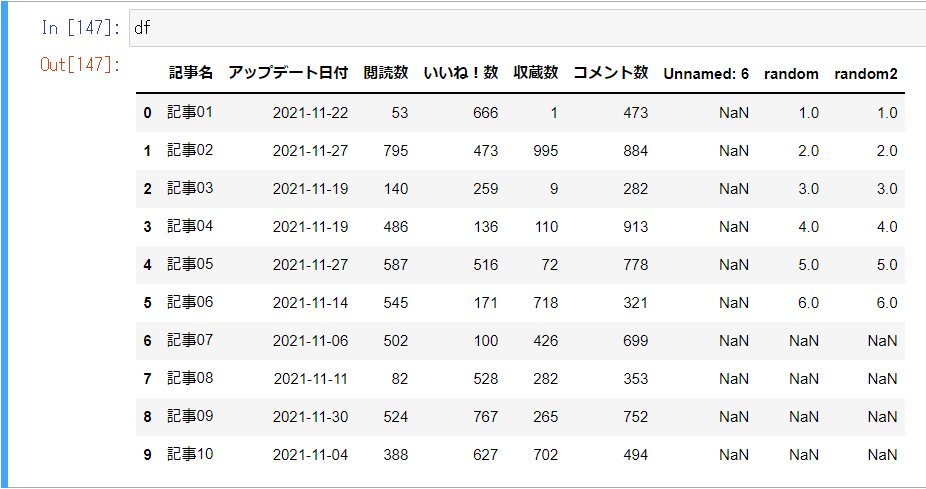
これでJupyter NotebookへのExcelファイルのデータ読み込みが完了しました。
2.データの前処理
データは正しく読み込まれましたが、「コメント数」以降の3列は今回は使用しません。
この章では不要な行や列を削除する方法をご紹介します。
ここでは見やすくするため、下記のコードを入力し、5行目まで表示させます。
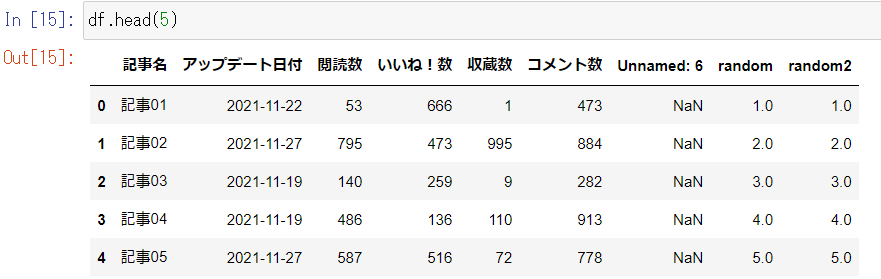
①行、列や空白列の削除
まずは「random」「random2」の2列を列名指定で削除してみましょう。
ここではdf.dropを使います。
(axis=1の場合は列を指定する、0の場合は行を指定する)

次に空白列(「コメント数」の次の列)を削除してみましょう。
ここではdf.dorpnaを使います。
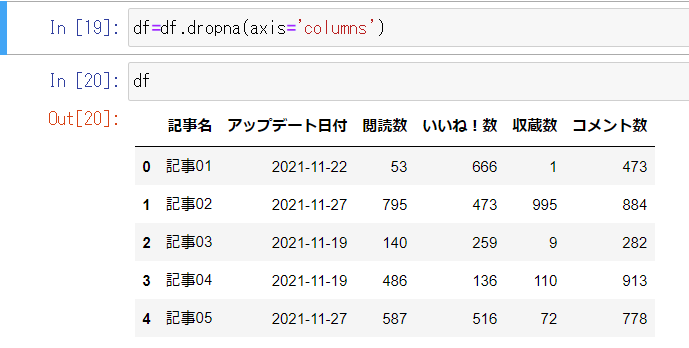
これで不要な列を削除することが出来ました。
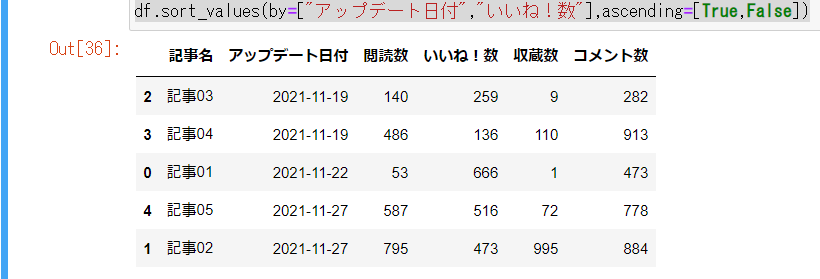
②データの並び替え
ここでは「アップデート日付」の昇順、「いいね!数」の降順にソートしてみます。
・指定方法
df.sort_values(by=["x"],ascending=[y])
x=ヘッダー名、y=Trueの場合は昇順、Falseの場合は降順
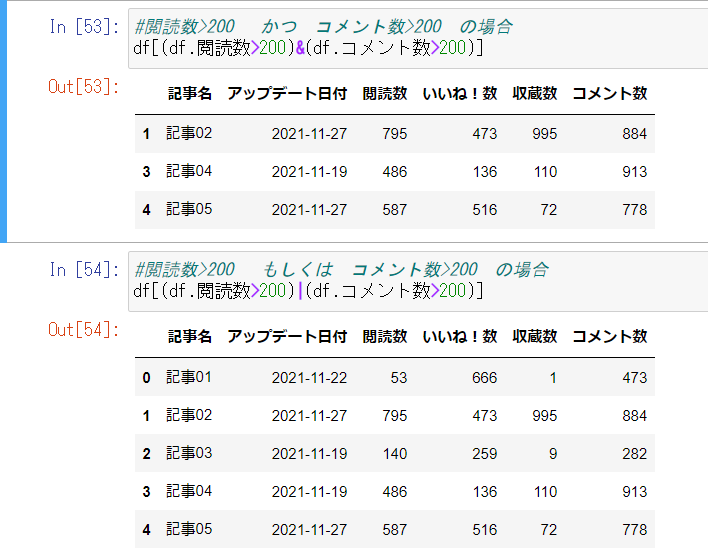
③条件付きデータ抽出
次に様々な条件でデータを抽出してみましょう。
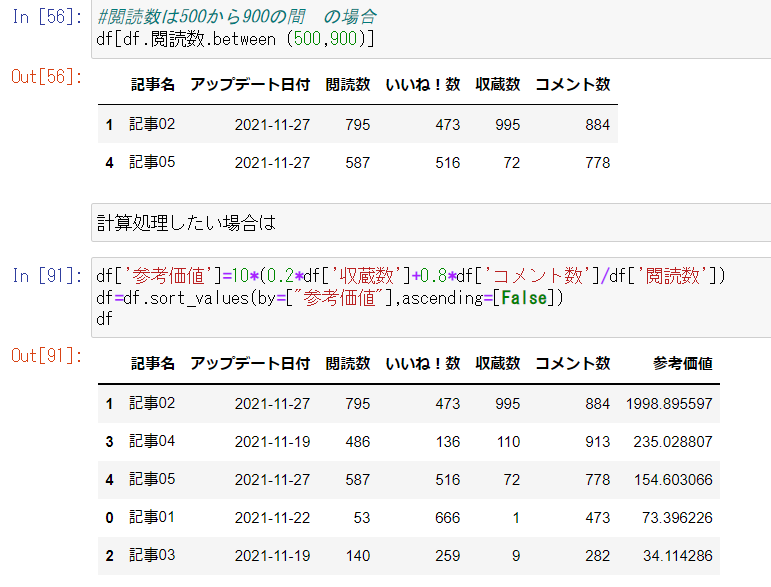
3.データの可視化
Jupyter Notebookではデータの可視化も簡単にできます。
本章ではその方法をご紹介します。
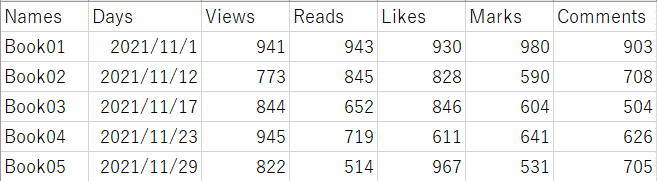
Jupyter Notebookでは、グラフ上の日本語表示は文字化けするので、ヘッダーを英語に変換し、改めて作業用データを用意しました。
読み込みデータの中身は以下の通りです。
下記の通りコードを入力すると、自動的に計算処理し、表形式のデータを棒グラフにしてくれます。
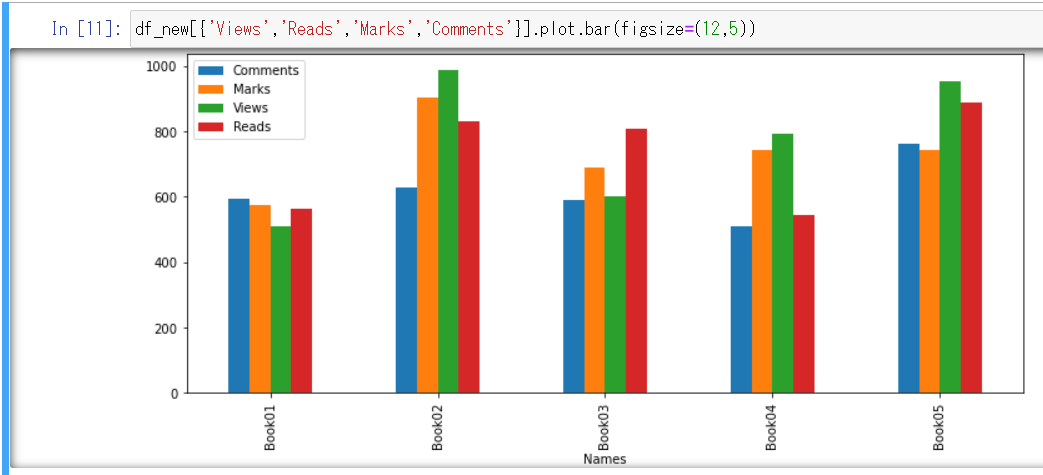
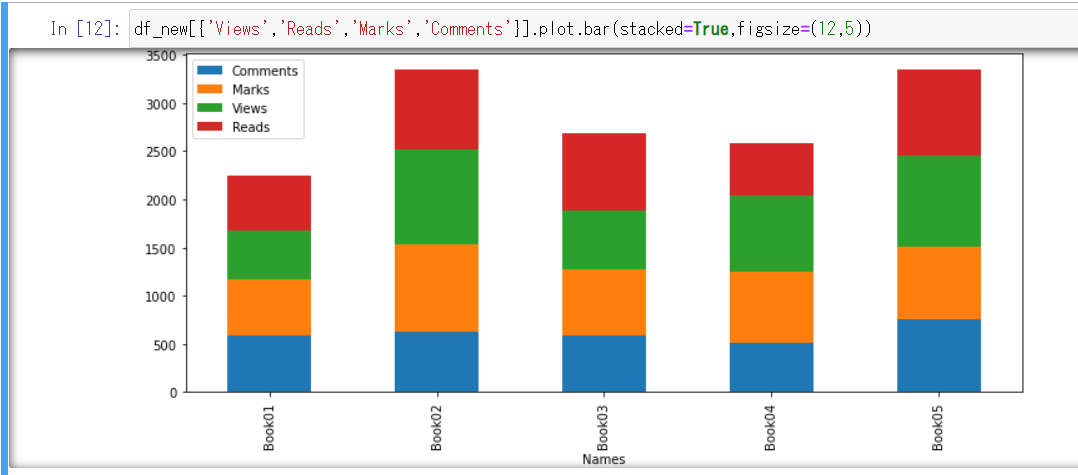
また、stackedを使えば、このような積み上げ棒グラフにすることも可能です。
(figsizeで図のサイズも指定できます)
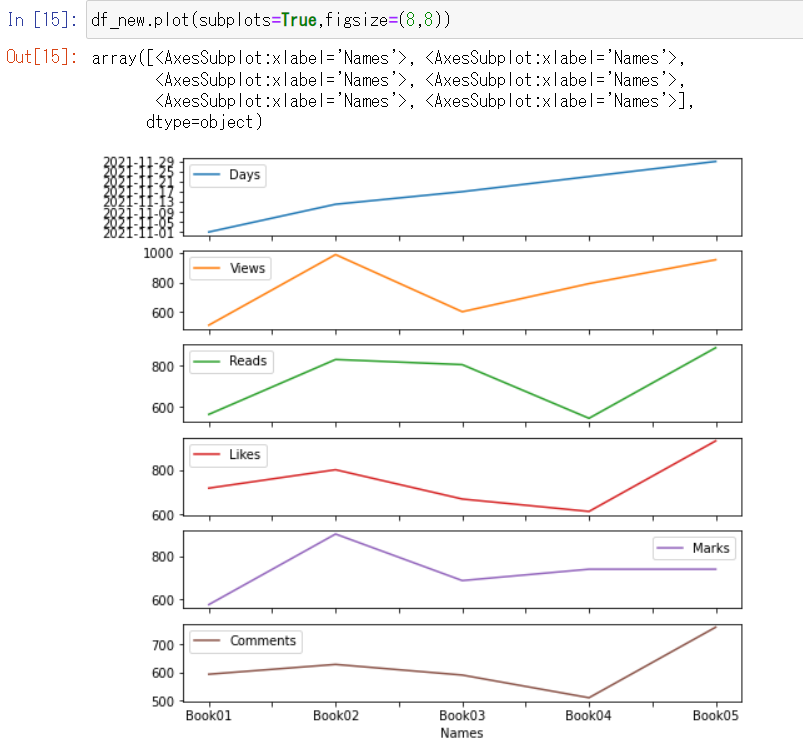
そして、項目ごとに図が欲しい場合は、subplotsを使って一気に作成することもできます。
4.おわりに
今回は初心者向けに、Pythonデータを解析する方法をご紹介しました。
また機会があれば、他の機能もご紹介していきたいと思います。











