機械学習とBIツールでデータ可視化してみた<実践編>~OracleMachineLearning実装~

データ活用ことはじめ
「BIツールから機械学習を実行し、可視化する」
――社内に眠っているデータを活用し、過去の分析だけにとどまらず、未来を予測する。そんなケースが増えてきました。
機械学習では、裏で膨大な計算をさせるためにチューニングに奮闘したり、デー タベースから機械学習用基盤にデータを送る仕組みを構築したり… メインの機械学習をさせるまでには様々な作業が発生します。
そんな作業を一気に解決してくれるのが「Oracle Autonomous Data Warehouse」 です!
そこで本ブログでは連載形式で、データベースにOracle Cloud の「Autonomous Data Warehouse(以下、ADWと表記)」、BIツールに”ADW対応”、かつ、”豊富な表現力でデータドリブンを可能とする”「MotionBoard」(MB)を使用した、機械学習を検証していきます。
今回は ADW 単体で機械学習をしていきます!(MotionBoard からの実行は次回ご紹介します。)
1.検証環境
Oracle Cloud Free Tierでクラウドアカウントを作成し、ADW を構築
※Oracle上のユーザは<構築編>で作成した「ML」を使用
2.予測テーマ
Kaggle入門として有名な「タイタニック号の生存予測」
https://www.kaggle.com/c/titanic
今回はこちらの題材をお借りして ADW で実装していきます。
3.手順
(1)データをCSVファイルで用意し、ADW にロードします。
今回使用するCSVファイルはこちら
https://www.kaggle.com/c/titanic/data
| train.csv | 訓練データ |
|---|---|
| test.csv | 実際に予測を適用するテストデータ |
データのロード方法は今回2通り試してみます。
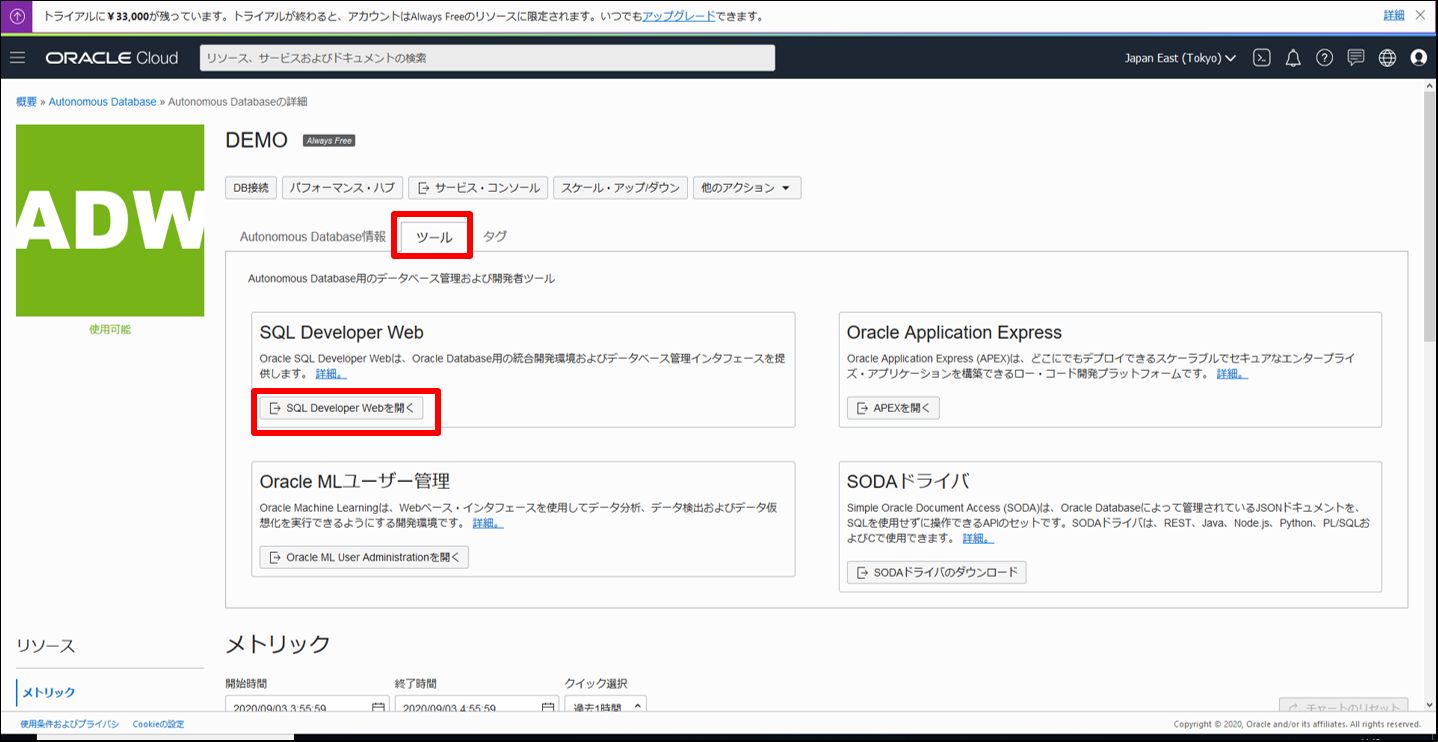
① 「SQL Developer Web」を使用
② 「DBMS_CLOUD.CREATE_CREDENTIAL」を使用
① 「SQL Developer Web」を使用
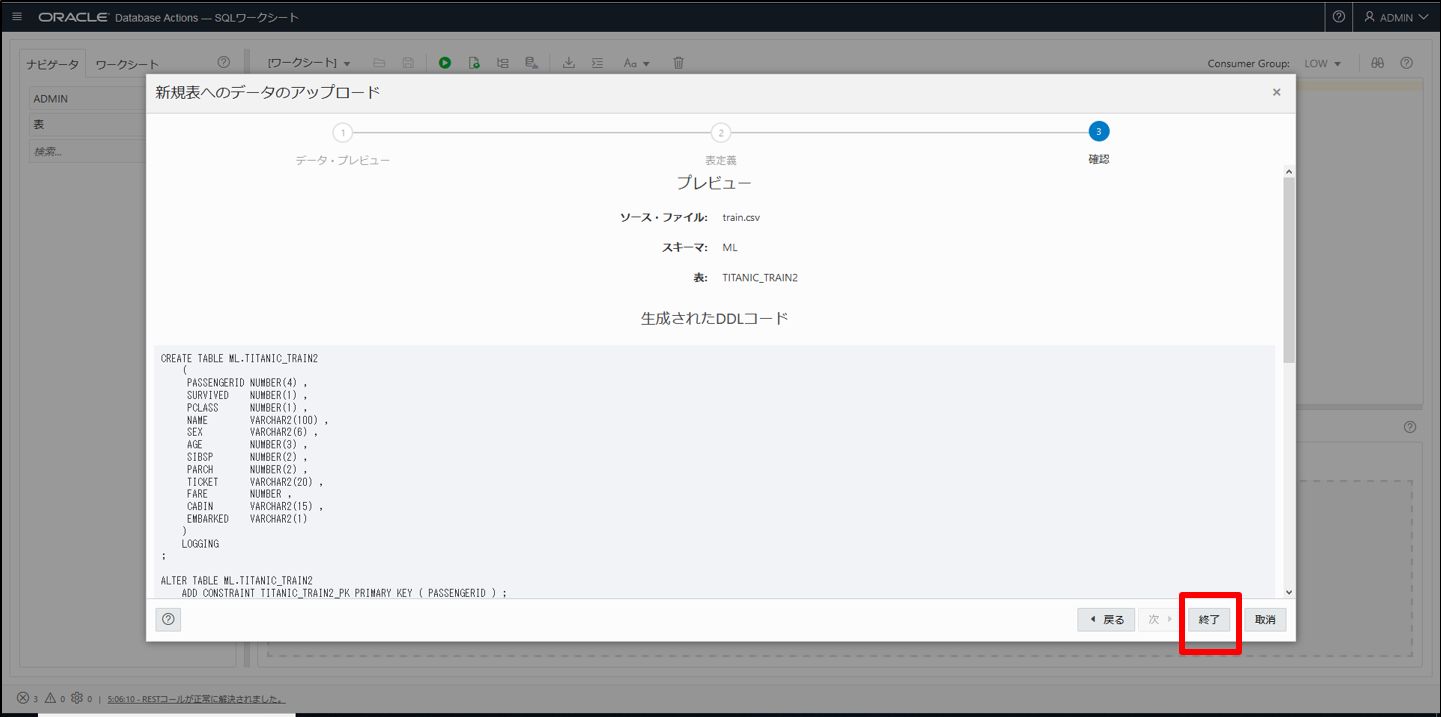
こちらの方法では CSV を画面にドラッグするだけでロードできます。ただし、「SQL Developer Web」には管理者権限のある Oracle ユーザでなければ入れないという注意点があります。
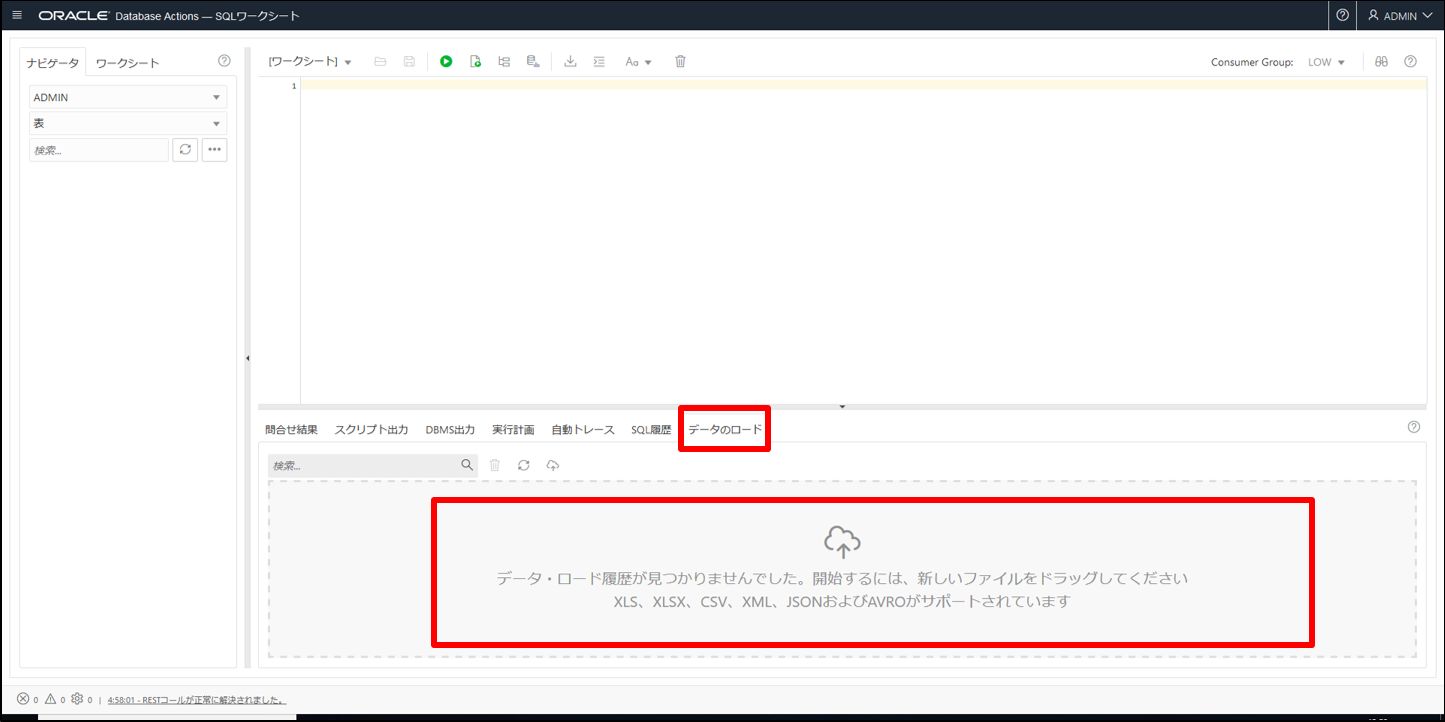
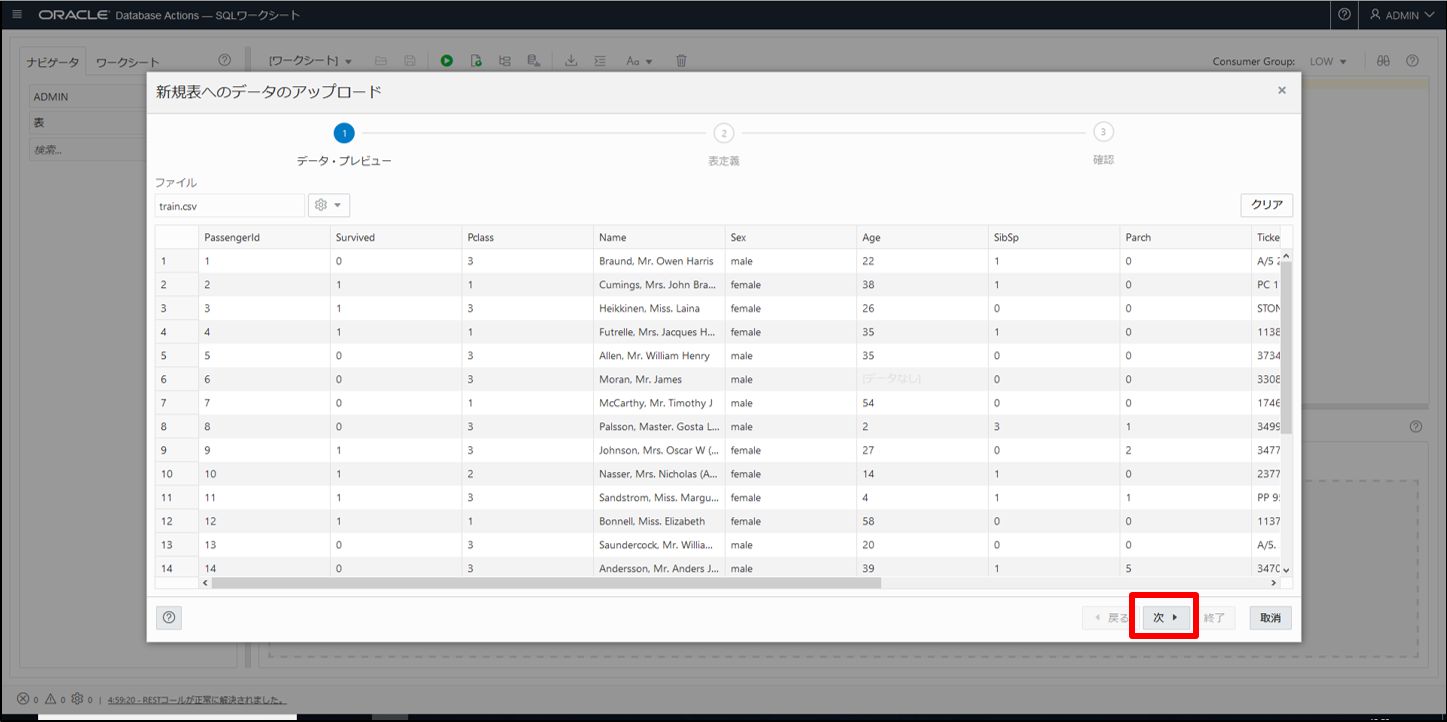
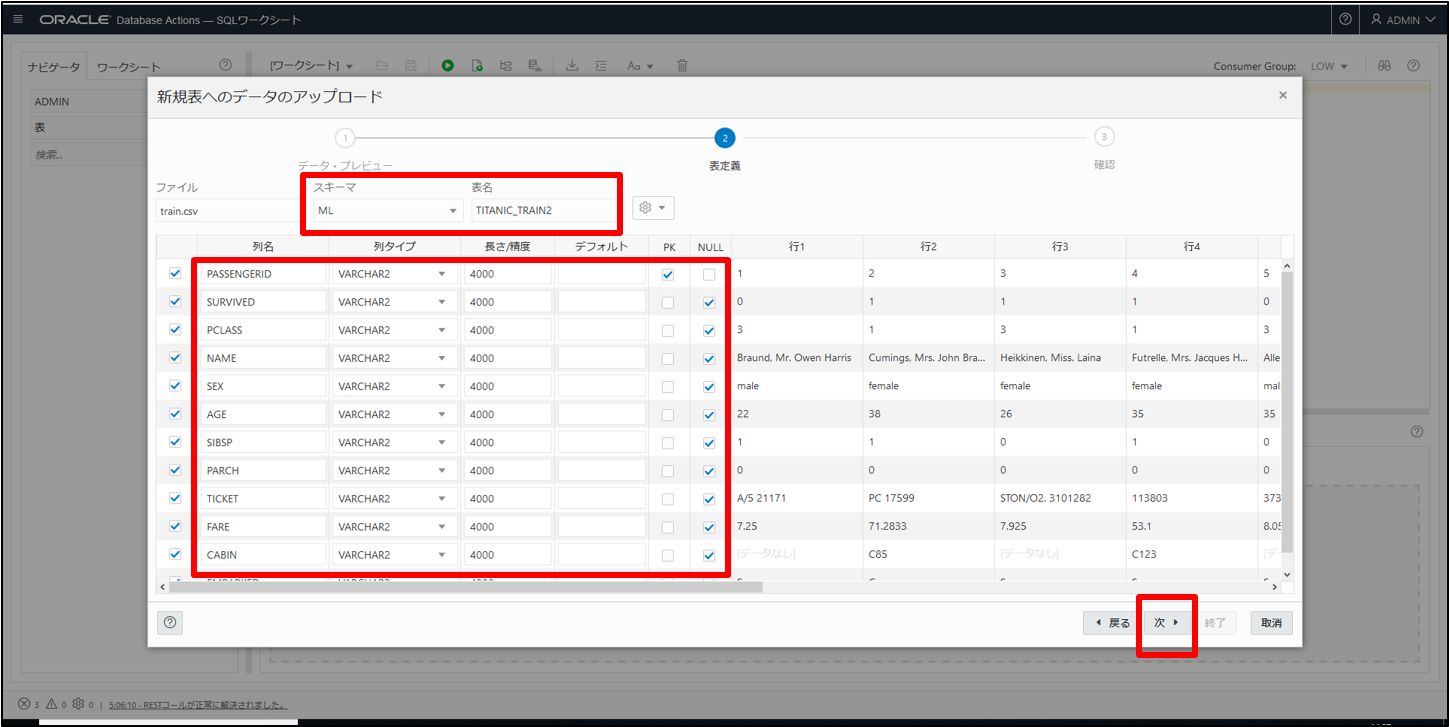
各種設定していきます。
「次へ」のボタンがアクティブにならない場合は表名にカーソルをあわせ、Enterキーを押します。
② 「DBMS_CLOUD.CREATE_CREDENTIAL」を使用
「管理者権限がないユーザで実行したい!」「クライアントPCの SQL Developer からもストアドで実行したい!」という方はこちら。
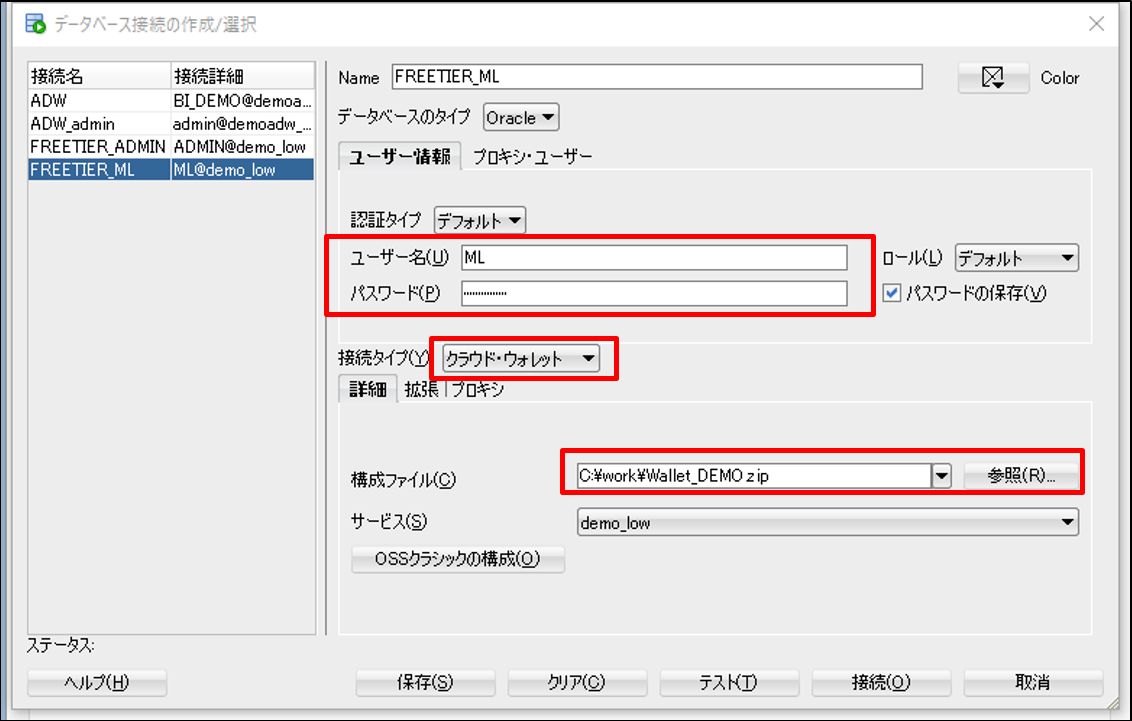
・クライアントPCの SQL Developer から ADW に接続できるように設定
※接続タイプで「クラウド・ウォレット」が出てこない場合は、最新の SQL Developer をインストールする必要があります。※ウォレットのダウンロード方法は<構築編>に記載しています。
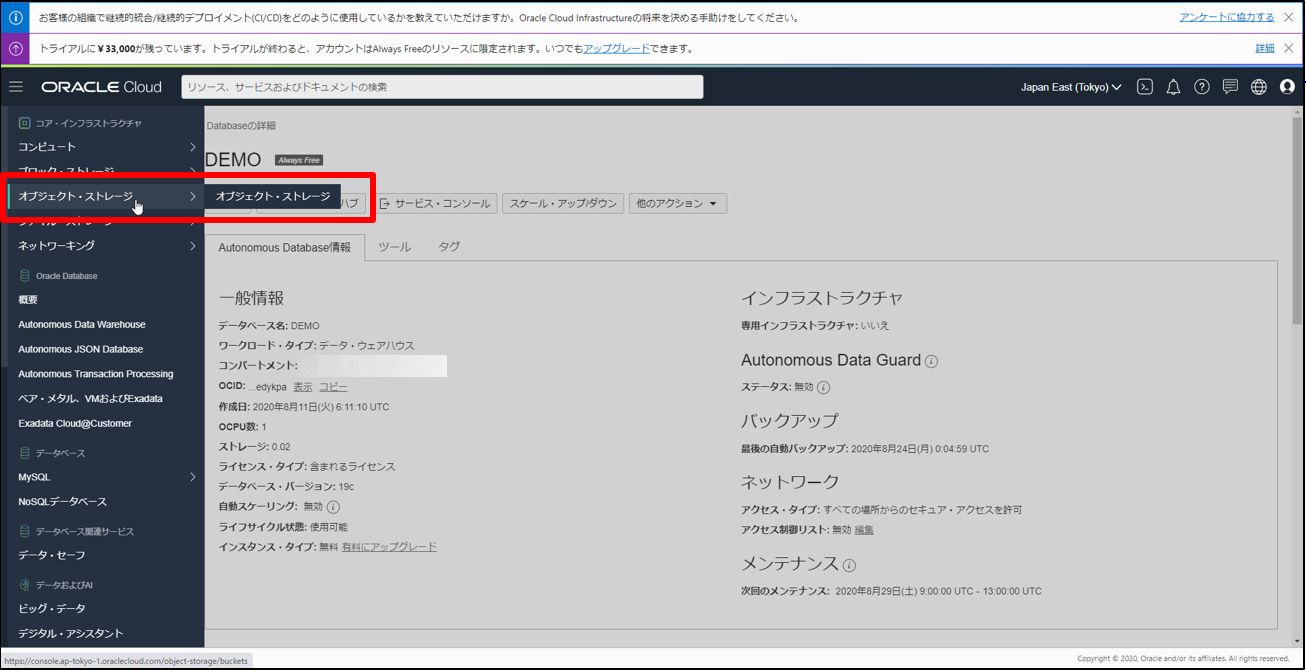
・OCI の画面からオブジェクト・ストレージにCSVを配置
左上のメニューから オブジェクト・ストレージ に移動
バケットを作成
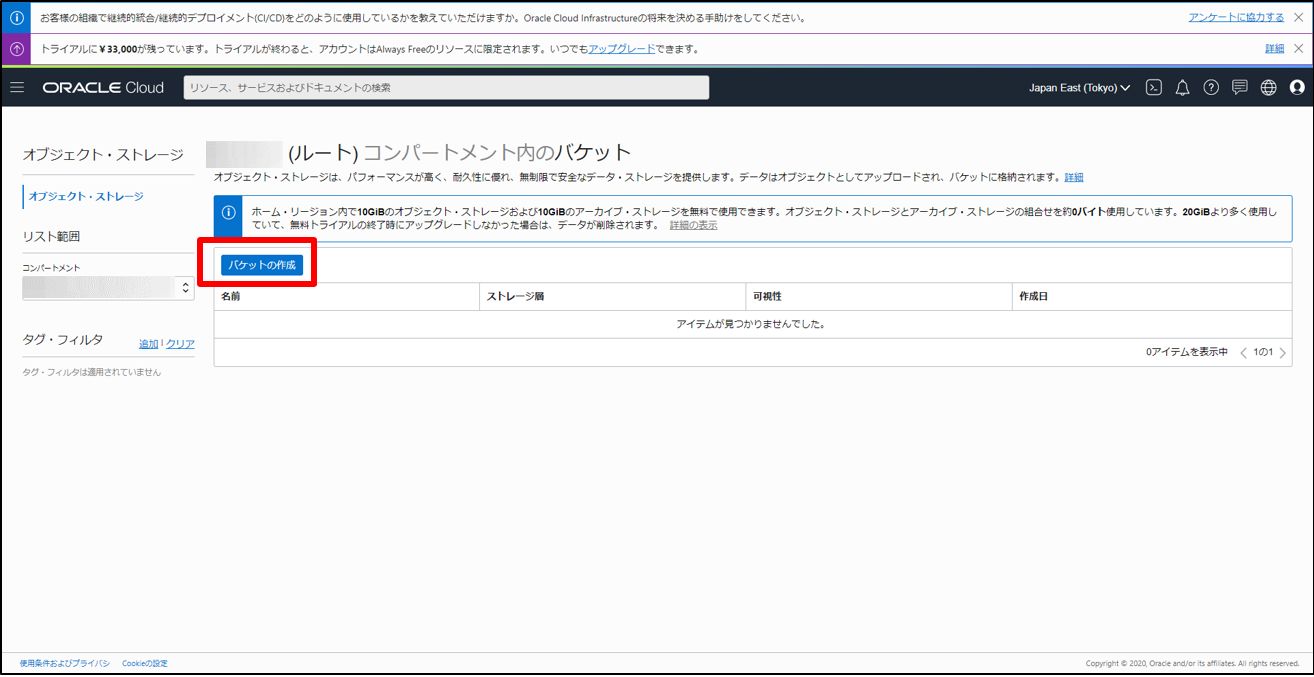
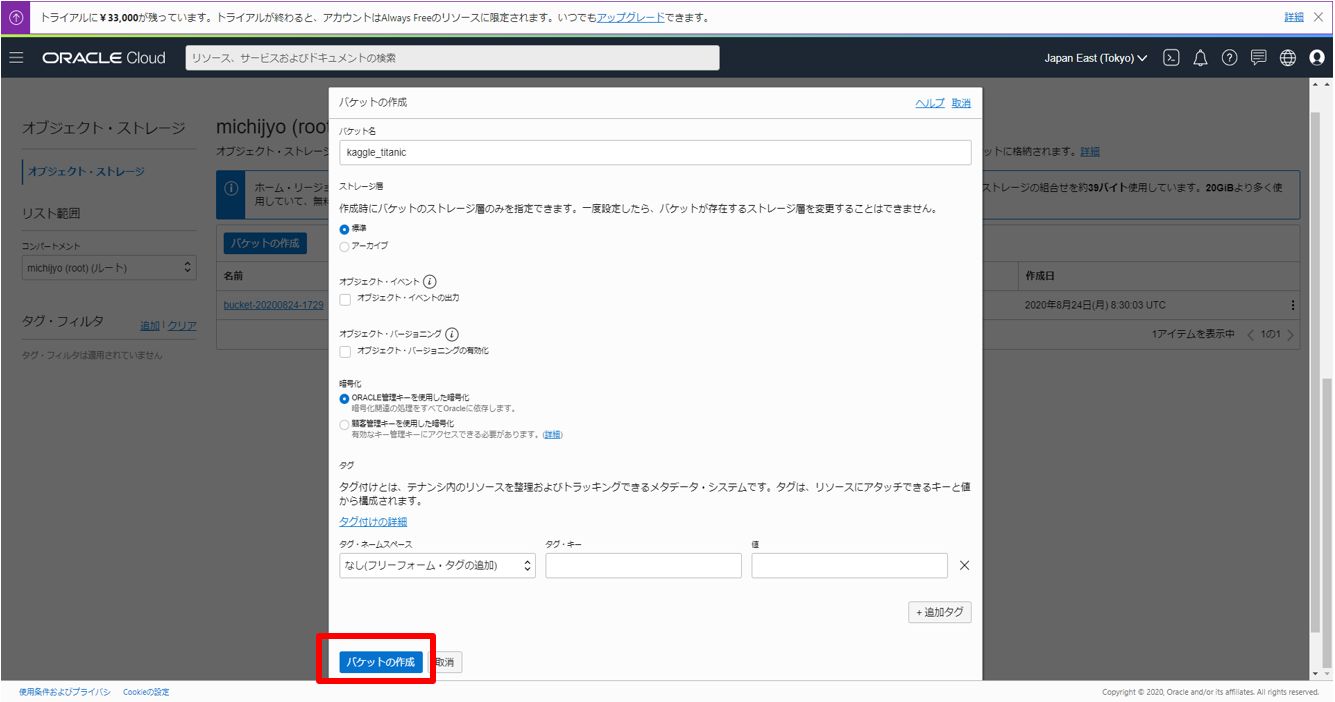
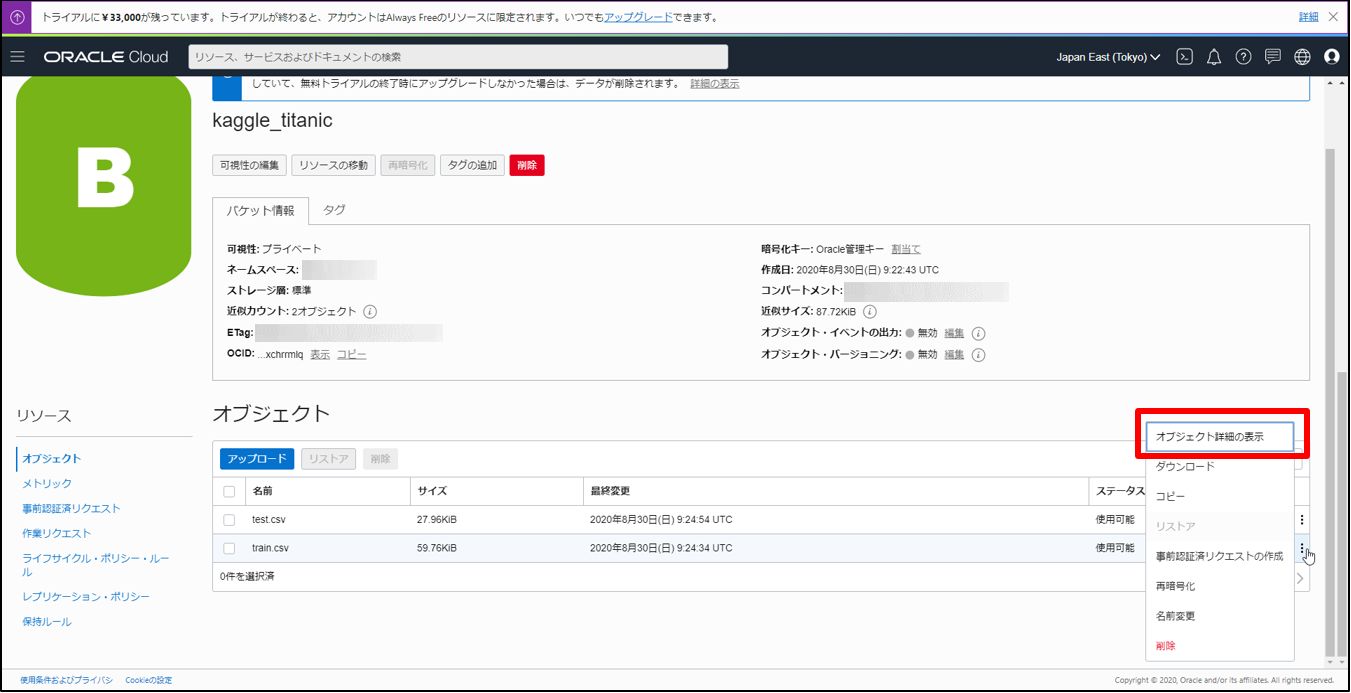
作成したバケットにCSVをアップロード
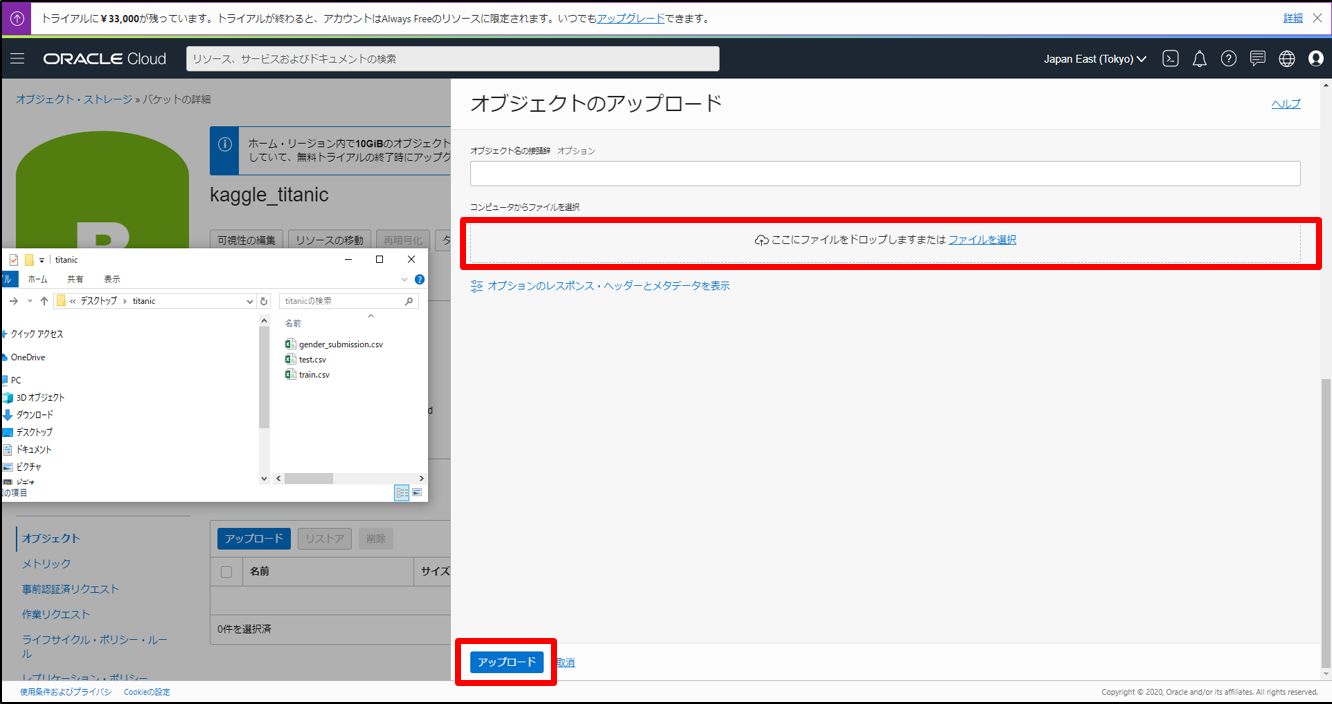
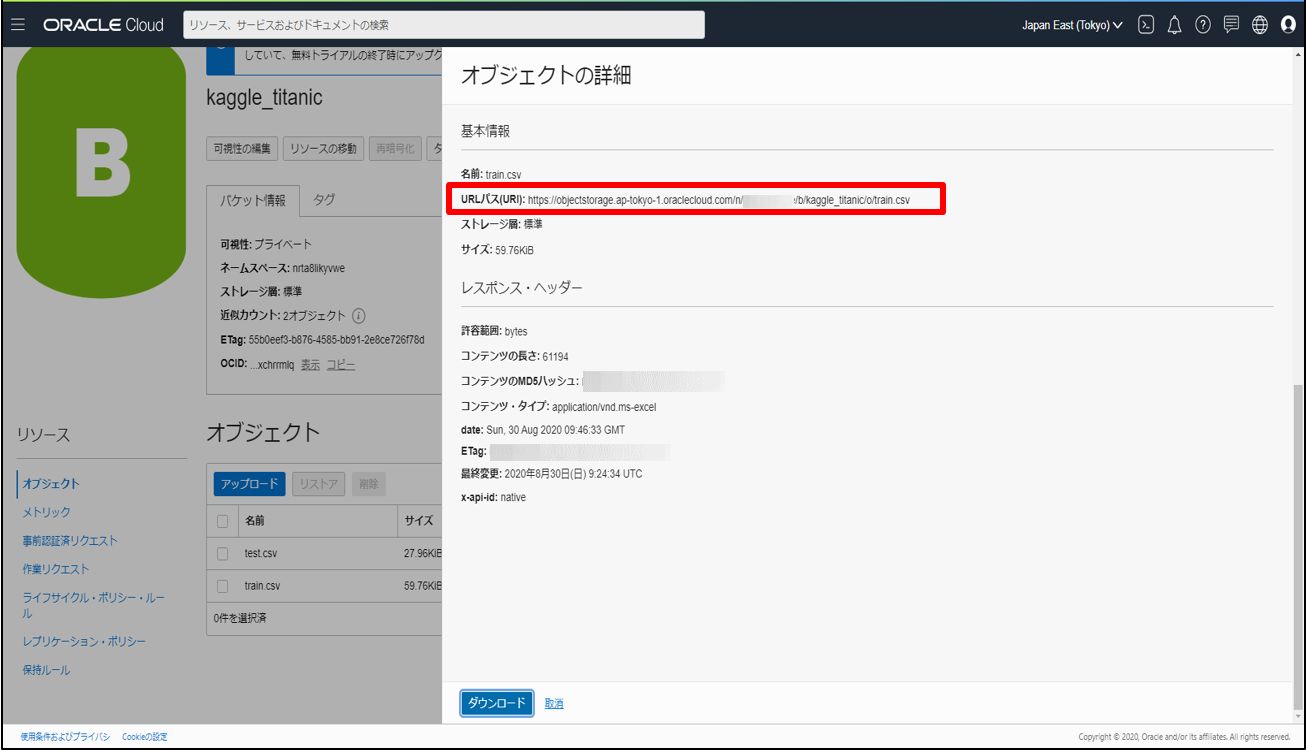
リストの右の方をクリックし、オブジェクト詳細を表示。URLパスを取得します。
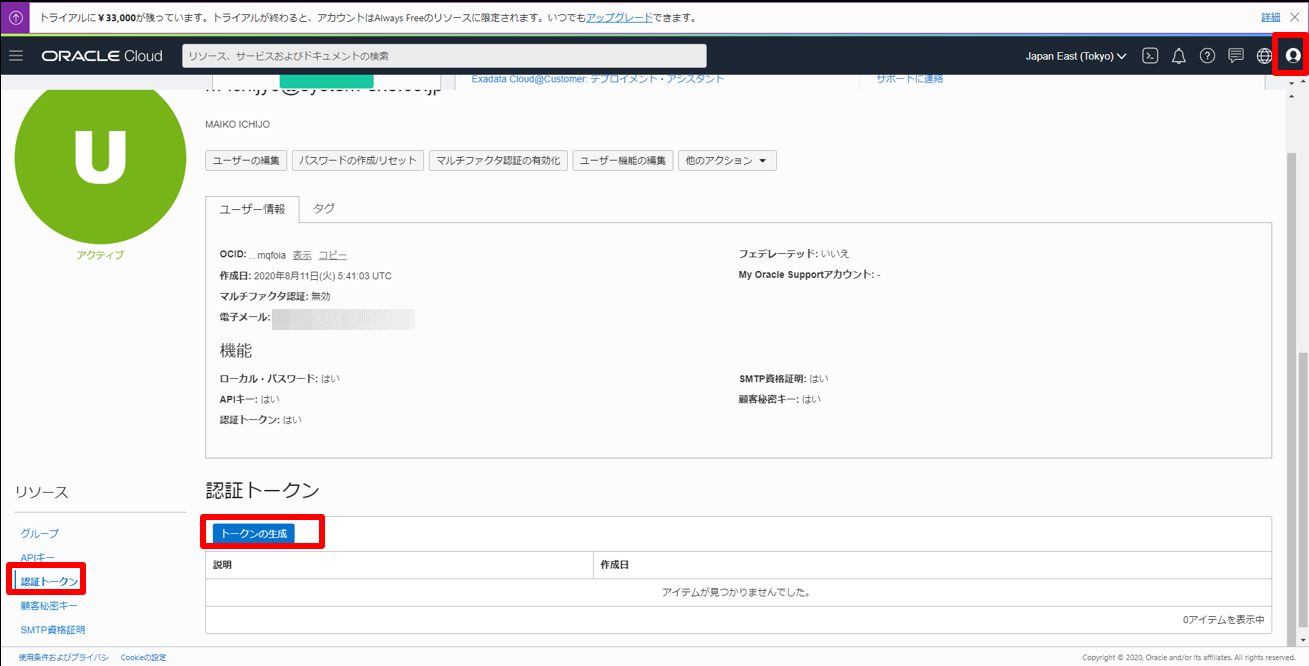
・認証トークンを作成
右上のプロファイルから「ユーザ設定」を開き、左下の「認証トークン」を選択します。
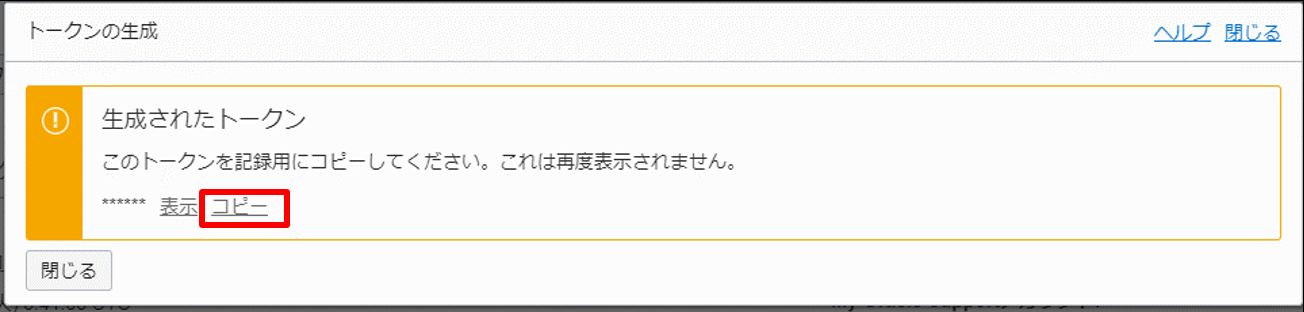
トークンの生成を行い、生成されたトークンをコピーします。

・ストアドの実行
あとは テーブルを用意し、SQL Developer から下記のコマンドを発行すると読み込み完了です!
CREATE TABLE TITANIC_TRAIN
(
PASSENGERID NUMBER(4)
, SURVIVED NUMBER(1)
, PCLASS NUMBER(1)
, NAME VARCHAR2(100)
, SEX VARCHAR2(6)
, AGE NUMBER(3)
, SIBSP NUMBER(2)
, PARCH NUMBER(2)
, TICKET VARCHAR2(20)
, FARE NUMBER(8,4)
, CABIN VARCHAR2(15)
, EMBARKED VARCHAR2(1)
)
;
SET DEFINE OFF
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'CRED_TEST',
username => 'xxxxx@xxxxxxxxxx.co.jp', -- OCIにログインするときに使用しているメールアドレス
password => 'k3C1AxxxxxxxvAiK)KT)' -- 前手順で生成したトークン
);
END;
/
BEGIN
DBMS_CLOUD.COPY_DATA(
table_name =>'TITANIC_TRAIN',
credential_name =>'CRED_TEST',
file_uri_list =>'https://objectstorage.ap-tokyo-1.oraclecloud.com/n/nrta8likyvwe/b/kaggle_titanic/o/train.csv',
format => json_object('type' value 'csv','ignoremissingcolumns' value 'true','skipheaders' value 1)
);
END;
(2)Oracle Machine Learning ノートブックから機械学習を試す
クライアントPC の SQL Developer からでも機械学習のストアドは実行できますが、せっかくなので ADW ならではの「Oracle Machine Learningノートブック」を使っていきます。
・MLユーザで「Oracle Machine Learningノートブック」を使うための手順
Oracle Machine Learningノートブック を立ち上げるユーザに権限を与えます。
1.Oracle MLユーザ管理に「ADMIN」でログインします。
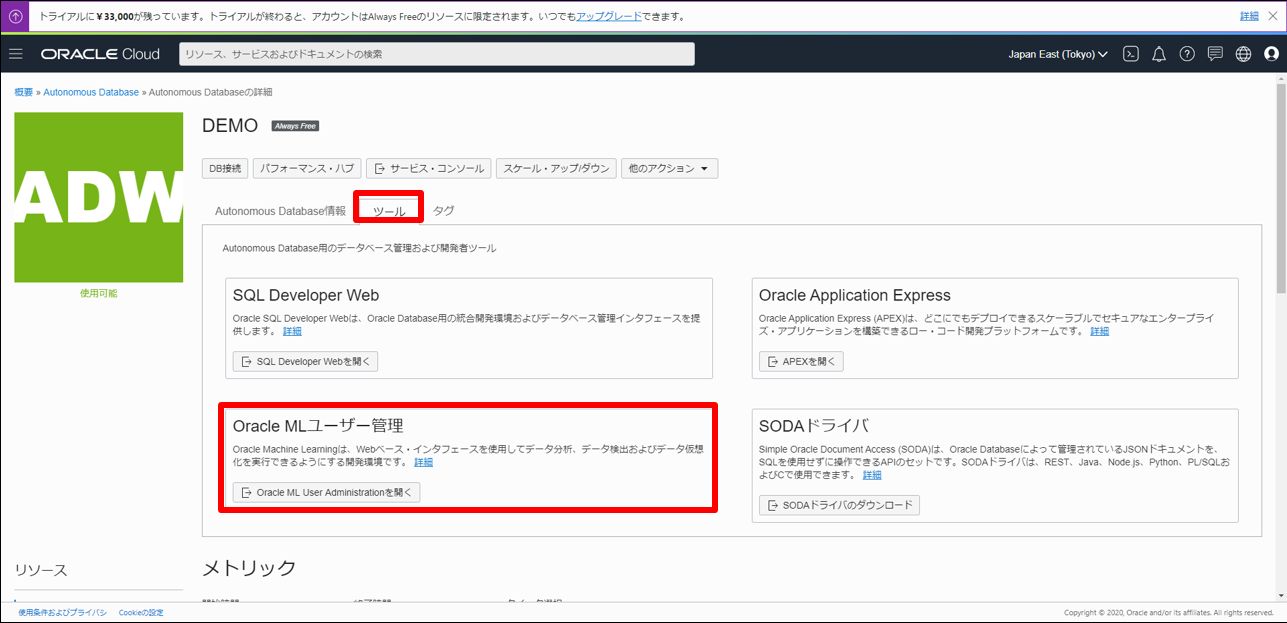
2.すべてのユーザを表示にチェックを入れ、権限を付与したいユーザ名の編集画面を表示し、保存しなおすだけで権限付与は完了です。

・「Oracle Machine Learningノートブック」にログイン
ADW の画面から「サービス・コンソール」→「開発」を開き、立ち上げます。
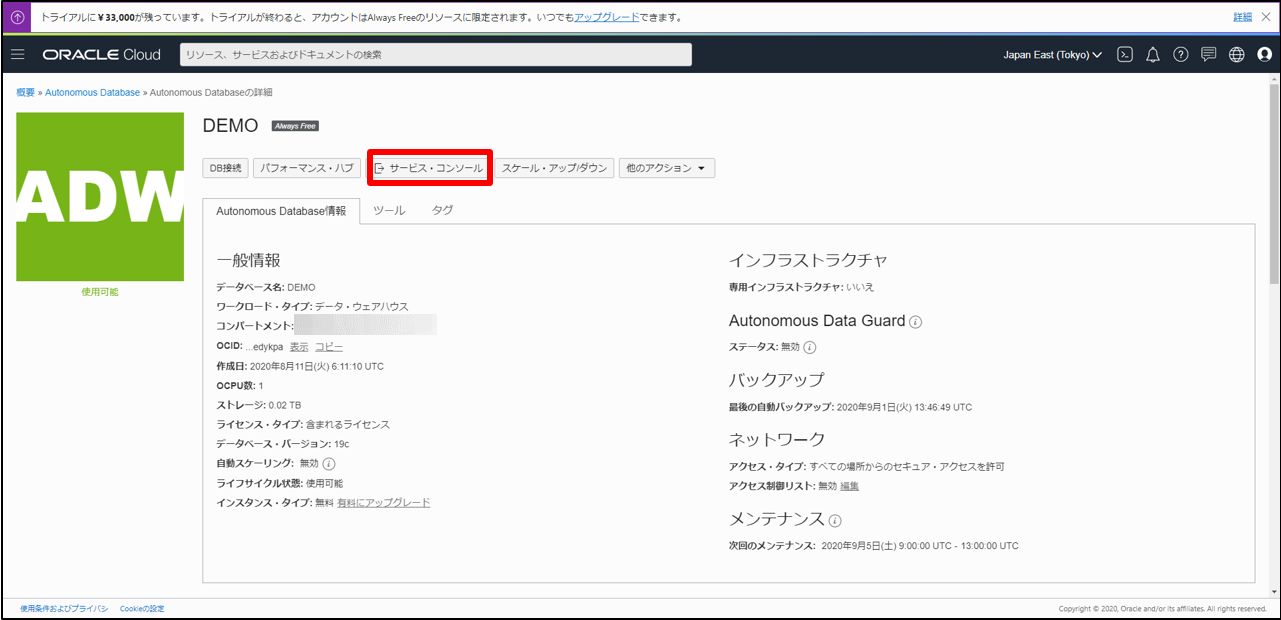
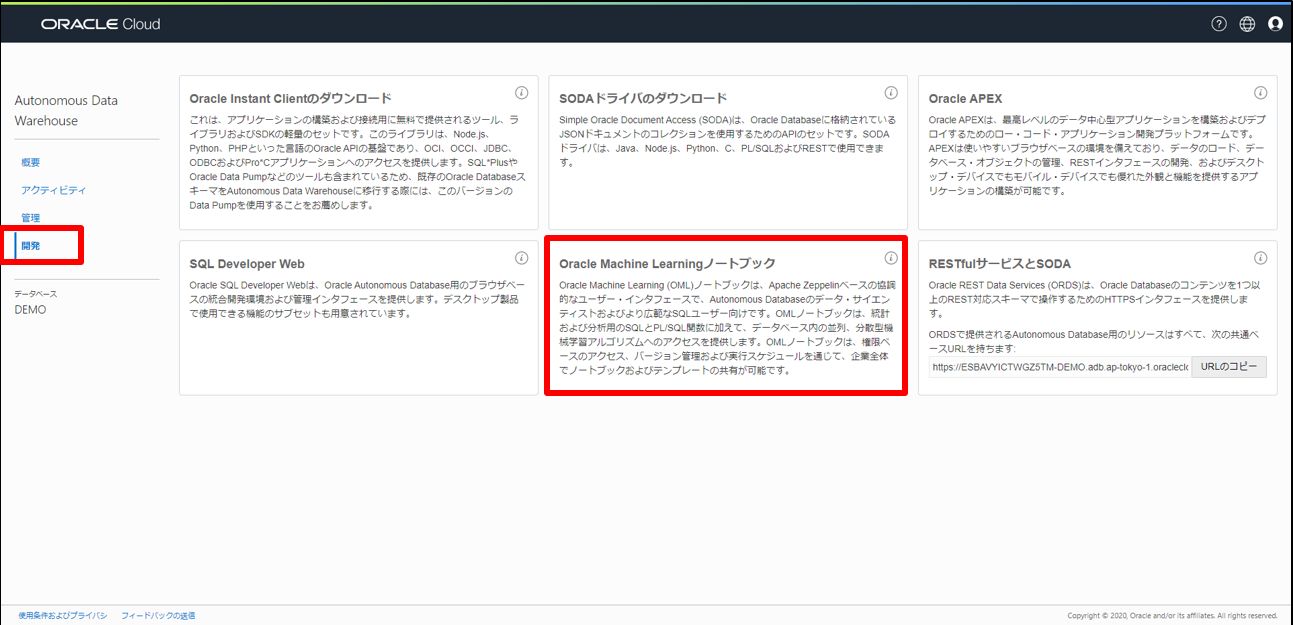
・訓練データを確認
今回使用する訓練データの内容はこちら。
| Passengerid | 変数定義キー |
|---|---|
| Survived | サバイバル0 =いいえ、1 =はい |
| Pclass | チケットクラス1 = 1st、2 = 2nd、3 = 3rd |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢年齢 |
| SibSp | タイタニック号に乗っている兄弟/配偶者の数 |
| Parch | タイタニック号に乗っている親/子供 |
| Ticket | チケット番号 |
| Fare | 運賃乗客運賃 |
| Cabin | キャビン番号 |
| Embarked | 乗船ポートC =シェルブール、Q =クイーンズタウン、S =サウサンプトン |
データの中身はこのような感じになっています。

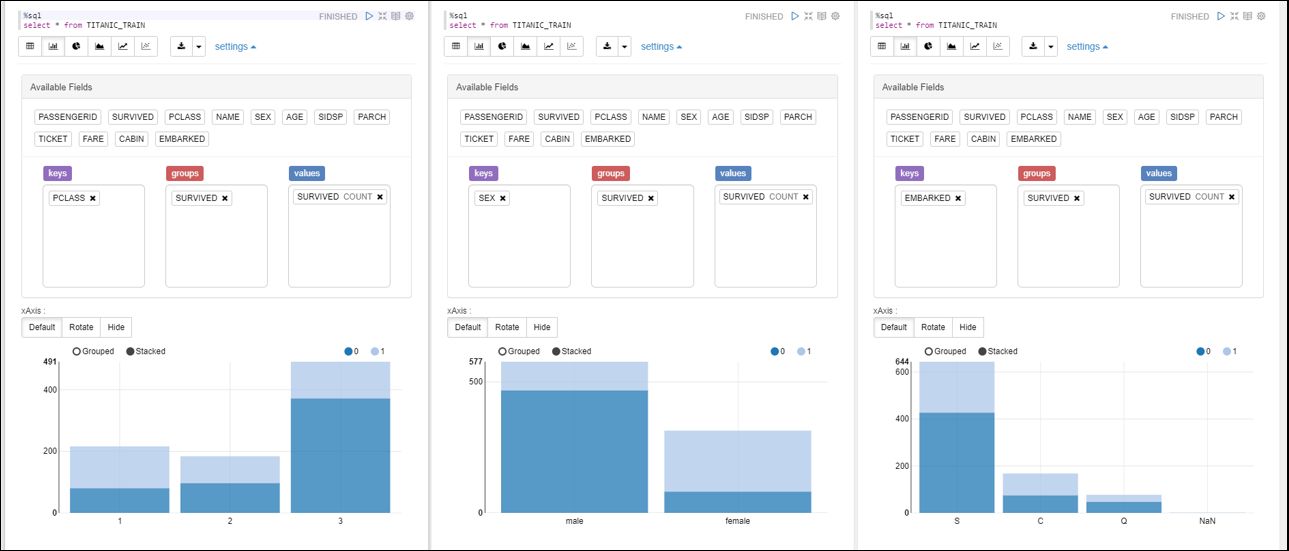
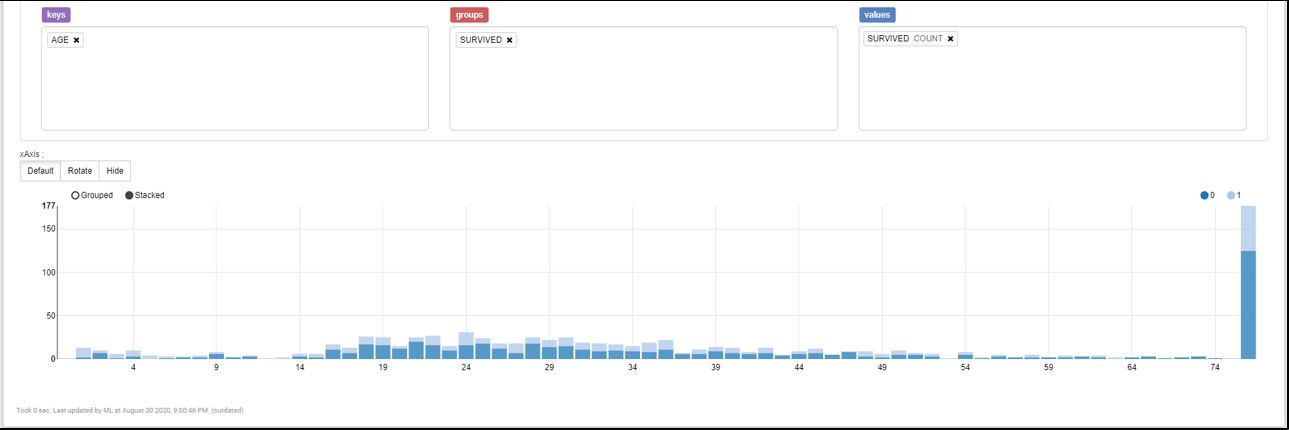
チケットクラスごと、性別ごと、乗船ポートごと、年齢ごとの生存状況も確認していきます。
ノートブックを使用すると、SELECT結果を集計してチャートで見ることができます。
・データの前処理
年齢と乗船ポートに欠損値があるので、年齢を中央値、乗船ポートを一番多い「S」で埋めていきます。
今回はVIEWを作成してNVL関数で欠損値を埋めるようにしていきます。また、今回は予測にこのままでは使えなさそうな「Name」「SibSp」「Parch」「Fare」「Cabin」をSELECT句からのぞきます。
CREATE
OR REPLACE VIEW V_TITANIC_TRAIN AS
SELECT
PASSENGERID,
SURVIVED,
PCLASS,
SEX,
NVL(AGE,28) AS AGE,
NVL(EMBARKED,'S') AS EMBARKED
FROM
TITANIC_TRAIN
;
CREATE
OR REPLACE VIEW V_TITANIC_TEST AS
SELECT
PASSENGERID,
PCLASS,
SEX,
NVL(AGE,28) AS AGE,
NVL(EMBARKED,'S') AS EMBARKED
FROM
TITANIC_TEST
;
・モデルの設定テーブルの作成
「SETTING_NAME」「SETTING_VALUE」2カラムのテーブルを用意し、設定値を挿入します。後述のモデル作成「DBMS_DATA_MINING.CREATE_MODEL」の引数でこのテーブルを指定します。
CREATE TABLE TITANIC_DECISION_TREE_SETTINGS (
SETTING_NAME VARCHAR2(30),
SETTING_VALUE VARCHAR2(4000));
今回はディシジョンツリーのアルゴリズムを使用する設定にします。
BEGIN INSERT INTO TITANIC_DECISION_TREE_SETTINGS (SETTING_NAME, SETTING_VALUE) VALUES (DBMS_DATA_MINING.ALGO_NAME, DBMS_DATA_MINING.ALGO_DECISION_TREE); INSERT INTO TITANIC_DECISION_TREE_SETTINGS (SETTING_NAME, SETTING_VALUE) VALUES (DBMS_DATA_MINING.PREP_AUTO, DBMS_DATA_MINING.PREP_AUTO_ON); COMMIT; END;
・モデルの作成
BEGIN DBMS_DATA_MINING.CREATE_MODEL( MODEL_NAME => 'TITANIC_DECISION_TREE_MODEL', MINING_FUNCTION => DBMS_DATA_MINING.CLASSIFICATION, DATA_TABLE_NAME => 'V_TITANIC_TRAIN', TARGET_COLUMN_NAME => 'SURVIVED', CASE_ID_COLUMN_NAME => 'PASSENGERID', SETTINGS_TABLE_NAME => 'TITANIC_DECISION_TREE_SETTINGS'); END; /
| MODEL_NAME | 任意のモデル名を指定 |
|---|---|
| MINING_FUNCTION | 今回は生存1か0の分類なのでCLASSIFICATIONを指定 |
| DATA_TABLE_NAME | 訓練データ 先ほど欠損値を埋める形にしたVIEWを指定 |
| TARGET_COLUMN_NAME | 予測対象のカラムを指定 |
| CASE_ID_COLUMN_NAME | 一意になる数値が入ったカラムを指定 |
| SETTINGS_TABLE_NAME | 前テーブルで作成したような設定テーブルを指定 |
(CREATE_MODEL2 を使用すれば設定テーブルを作らず、変数で設定することも可能です。)
モデルを作成するとディクショナリテーブルに登録されたり、作成したモデルに紐づくテーブルやVIEWが作成されます。
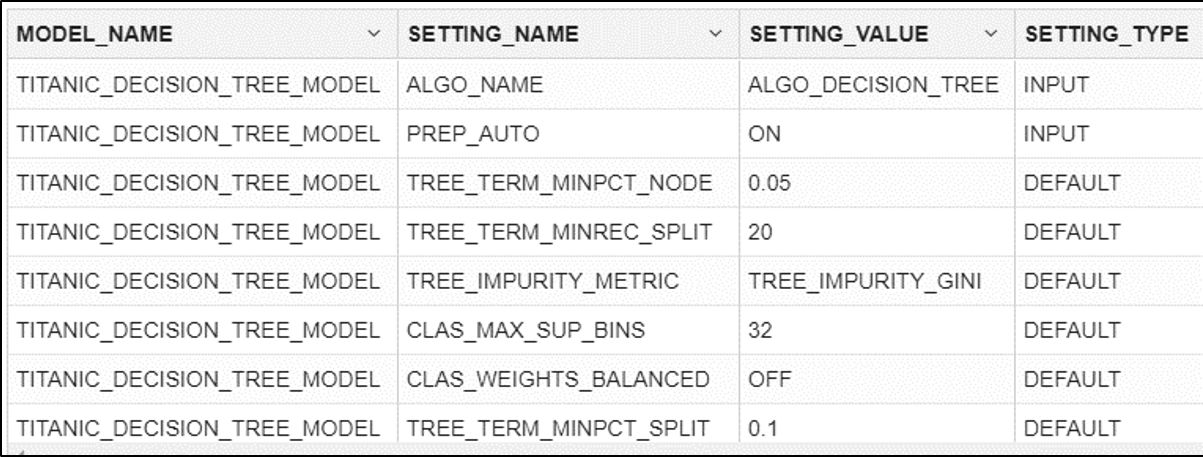
▽登録されたモデルの設定値の確認
SELECT * FROM USER_MINING_MODEL_SETTINGS WHERE MODEL_NAME = 'TITANIC_DECISION_TREE_MODEL'
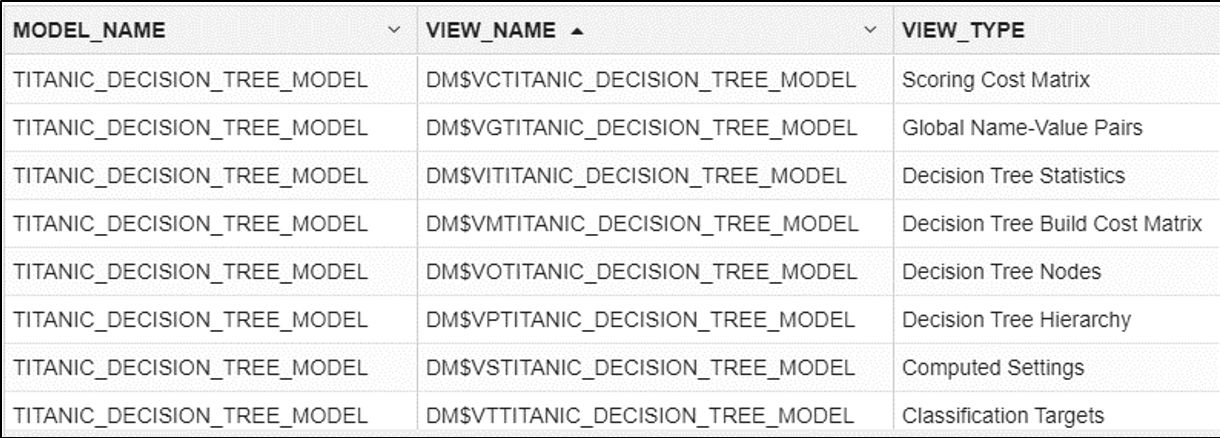
▽作成されたビューの確認
SELECT * FROM USER_MINING_MODEL_VIEWS WHERE MODEL_NAME = 'TITANIC_DECISION_TREE_MODEL'
・モデルを使った予測
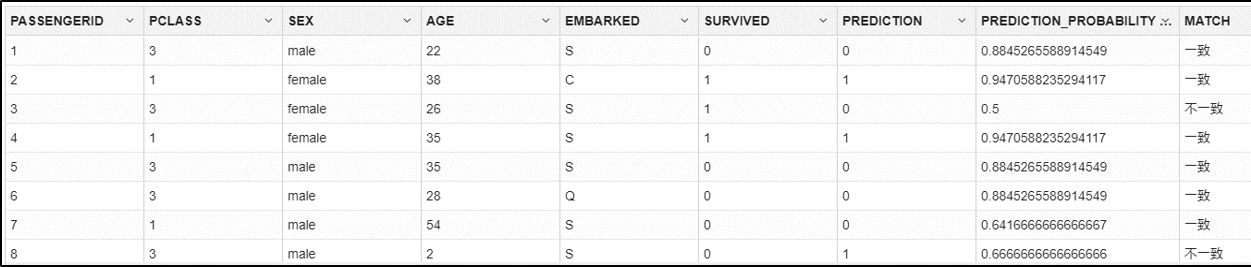
本来は訓練データから6割ほどランダムに抜き取って学習させ、残りの4割で予測値と実際の値を並べてどのくらい正解するかを見ますが、今回は訓練データを分ける工程を省いたので、モデル作成に使用した訓練データ全件の実際の値と予測値を比較し、どのくらい一致するか見ていきます。
SELECT
SUB.*,
CASE
WHEN SURVIVED = PREDICTION THEN '一致'
ELSE '不一致'
END AS MATCH
FROM
(
SELECT
TRAIN.PASSENGERID,
TRAIN.PCLASS,
TRAIN.SEX,
TRAIN.AGE,
TRAIN.EMBARKED,
TRAIN.SURVIVED,
PREDICTION(TITANIC_DECISION_TREE_MODEL USING *) AS PREDICTION,
PREDICTION_PROBABILITY(TITANIC_DECISION_TREE_MODEL USING *)
AS PREDICTION_PROBABILITY
FROM
V_TITANIC_TRAIN TRAIN
) SUB
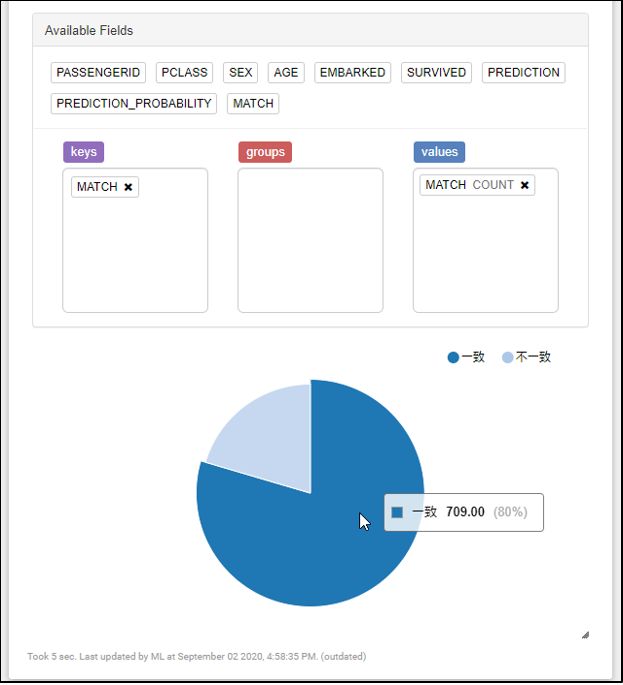
上のSELECT結果を集計してみると、正答率80%となりました。
一つのテストデータを与える場合はUSING句に記載します。
SELECT
PREDICTION(TITANIC_DECISION_TREE_MODEL USING
3 AS PCLASS
, 'male' AS SEX
, 'S' AS EMBARKED
) AS PREDICTION
FROM
DUAL
Kaggleに投稿する用に、テストデータにもモデルを適用してみます!
SELECT
PASSENGERID
, PREDICTION(TITANIC_DECISION_TREE_MODEL USING *) AS SURVIVED
FROM
V_TITANIC_TEST TEST
結果をKaggleのSubmit Predictionsから投稿してみます。
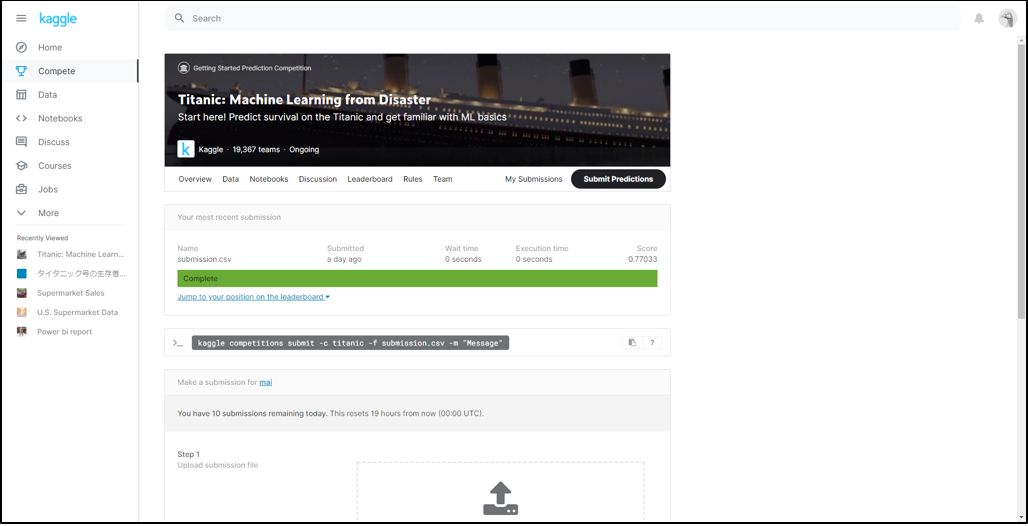
スコアは「0.77033」でした。
使用するアルゴリズムを変えたり、パラメータを変更したり、データの前処理で今回使用しなかった「Name」から「Miss」や「Mrs」などを切り出して分析に使ったりまだまだ改善の余地ありですね。
やってみた感想としては、SQL に慣れている人にはとっつきやすい印象でした。
次回は、同じタイタニックのテーマを使って、MotionBoardからモデルの作成・予測を実装してきます!










