第17回:OracleDatabaseで異なる文字コード間におけるデータ移行時の注意点

Oracle Databaseの移行案件を扱っていると、異なるキャラクターセットへの移行を任され、文字コードやデータサイズの違いに戸惑う技術者の方も多いのではないでしょうか。
今回は、データベースリプレイス案件時に調査を行ったJA16SJIS(TILDE)からAL32UTF8への移行時の注意点についてご紹介したいと思います。
1.キャラクターセット
Oracle Databaseで取り扱う文字コードは、データベース作成時に設定するデータベースキャラクターセット(CHARACTER SET)、各国語キャラクターセット(NATIONAL CHARACTER SET)で決定されます。
※作成後、変更が出来ないので十分検討が必要です。
データベースキャラクターセット:以下データ型で取り扱う文字コードが決定されます。
CHAR
VARCHAR2
LONG
CLOB
各国語キャラクターセット:以下データ型で取り扱う文字コードが決定されます。
NCHAR
NVARCHAR2
NCLOB
昨今のOracle Databaseバージョンではグローバル化が考慮され、DB作成時のデフォルトはデータベースキャラクターセット:AL32UTF8、各国語キャラクターセット:AL16UTF16が選択されるようになっています。
Unicodeキャラクタ・セットである AL32UTF8 は世界のほとんどの言語をサポートしているため、通常はUnicodeキャラクタ・セットAL32UTF8を選択してください。特に日本語の氏名、住所を取り扱うデータベースではSJISでは取り扱えない特殊文字を考慮する必要があり、この設定で構成することが重要です。
現在でも古いデータベースバージョンで作成されたJA16SJIS(TILDE)キャラクターセットで稼働しているデータベースも存在し、このようなデータベースをAL32UTF8に移行する場合は下記の「データサイズの違い」について注意が必要です。
2.データサイズの違い
データベースキャラクターセット:各文字のバイト数は以下の通りです。
CHAR
VARCHAR2
LONG
CLOB
| JA16SJIS(TILDE) | AL32UTF8 | |
|---|---|---|
| 半角英数 | 1バイト | 1バイト |
| 半角カナ | 1バイト | 3バイト |
| 全角文字 | 2バイト | 3バイト |
| 補助文字 | 2バイト | 4バイト |
※補助文字=サロゲートペアの意味です。
初期化パラメータ「NLS_LENGTH_SEMANTICS = ‘CHAR’」を設定することにより文字数で定義することができますが、推奨されていません。これによって、多数の既存インストール・スクリプトに文字長さセマンティクスを持つ列が予期せず作成され、バッファ・オーバーフローなどのランタイム・エラーが発生する場合があります。
各国語キャラクターセット:現在デフォルトのAL16UTF16を利用する場合は以下の通りです。
NCHAR
NVARCHAR2
NCLOB
カラム長は文字数で定義します。サロゲートペア文字を除き、全て2バイト(1文字)なのでサロゲートペア文字のみ2文字としてカウントします。
3.データサイズの確認方法
カラム内の文字のバイト数を確認するにはdump関数を利用します。Unicodeに対応しているSQL Developerで確認した例を以下に示します。(Len=文字のバイト数: 文字の16進表記)
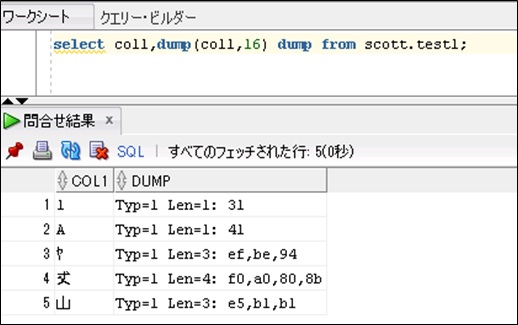
※4行目が補助文字(サロゲートペア)になります。
4.おわりに
異なるキャラクターセット間のデータ移行を行う場合は、有名な「波ダッシュ問題」等、多数の注意点があります。紙面の都合上、ここで全てをご紹介できませんが、文字コードの世界は奥が深いので、私も少しずつ探求しようと思っています。



