第12回:SQL Server 2019 新機能「データ仮想化」を試してみた

技術者向け・データベースの技術情報発信
皆様、こんにちは。
マルチDBソリューション部の奥田です。
今回は、「データ仮想化」についてです。
SQL Server 2019では、様々な機能拡張や新機能が追加されていますが、その中の1つ「データ仮想化」について少し検証してみました。
目次
データ仮想化とは?
各種データベース(SQL Server、Oracle、Hadoopなど)に格納されているデータを統合的に操作する技術の1つです。
これらのデータベースの1階層上に仮想のデータベースを構築し、そこでデータを操作するイメージです。この技術によって、複数のデータベースからデータを取り込むようなデータベース(DWHなど)の構築やインポート処理等の運用が不要となります。
また、データベースの追加、削除が柔軟に行えるなどのメリットがあります。
SQL Serverでの実現方法
SQL Server 2019では、データ仮想化を「PolyBase」という機能を使用して実現します。これはSQL Server 2016から実装された機能ですが、対応可能な外部データベースが「Hadoop」のみでした。
2019からはOracle、Postgress、MongoDBが対応可能となり、複数のデータベースからデータ操作可能となりました。
PolyBaseの導入方法
PolyBaseの機能を利用するには、インストーラから機能をインストールする必要があります。インストーラの「機能の選択」画面で以下の機能を適宜選択します。
- 外部データ用PolyBaseクエリサービス
→ SQL Server 2019で導入された機能、Oracle、Postgressなどが対象となる場合はこちらを選択。
- HDFSデータソースのJavaコネクタ
→ SQL Server 2016で導入された機能、Hadoopが対象となる場合はこちらを選択。
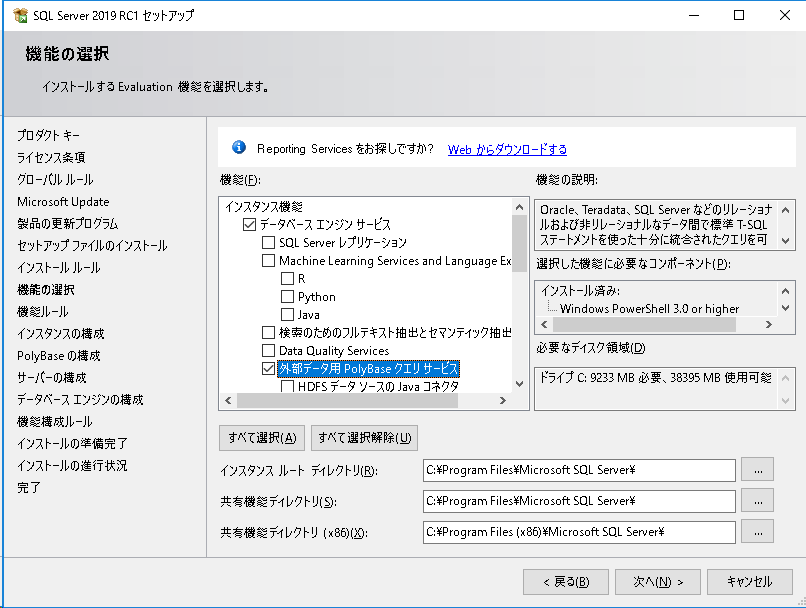
今回Hadoopは対象外のため、「外部データ用PolyBaseクエリサービス」のみにチェックを入れます。
次に「PolyBaseの構成」で以下の設定を行います。
- このSQL ServerをスタンドアロンのPolyBase対応インスタントとして使います
→ 単独でPolyBaseを使用する場合はこちらを選択。
- このSQL ServerをPolyBaseスケールアウトグループの一部として使います
→ 複数のSQL ServerをSQL Serverインスタンスクラスターとして
PolyBaseを使用する場合はこちらを選択。
この構成にすることで大量データの並行処理が可能となり、パフォーマンスが向上します。
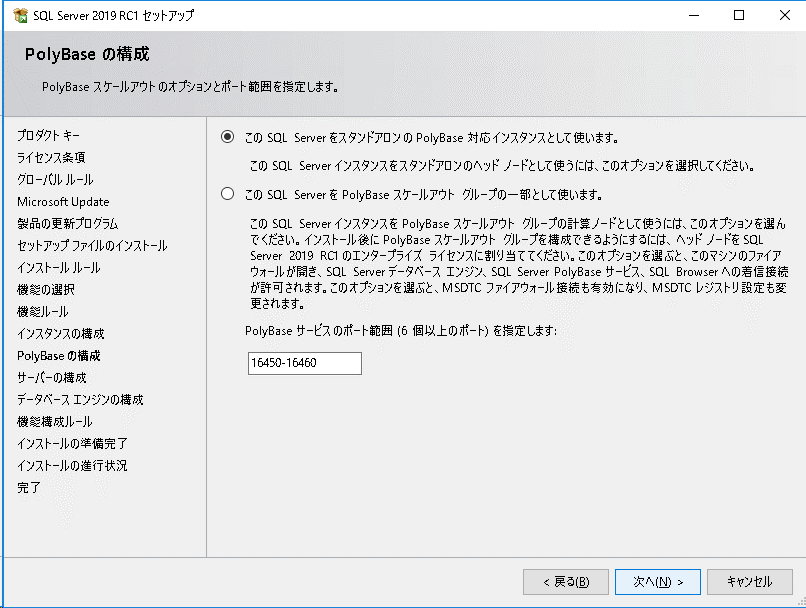
今回は簡単な検証を行うことが目的なので、スタンドアロンを選択します。因みにスケールアウトグループを構成する場合は、全ノード上で稼動するPolyBaseエンジン及びPolyBase Data Movementサービスを同じドメインアカウントで実行することが必須のようです。
インストールが完了したら、T-SQLコマンドでPolyBaseを有効にする必要があります。
今回はSSMSから以下のコマンドを実行しました。
exec sp_configure @configname = 'polybase enabled', @configvalue = 1;
RECONFIGURE ;
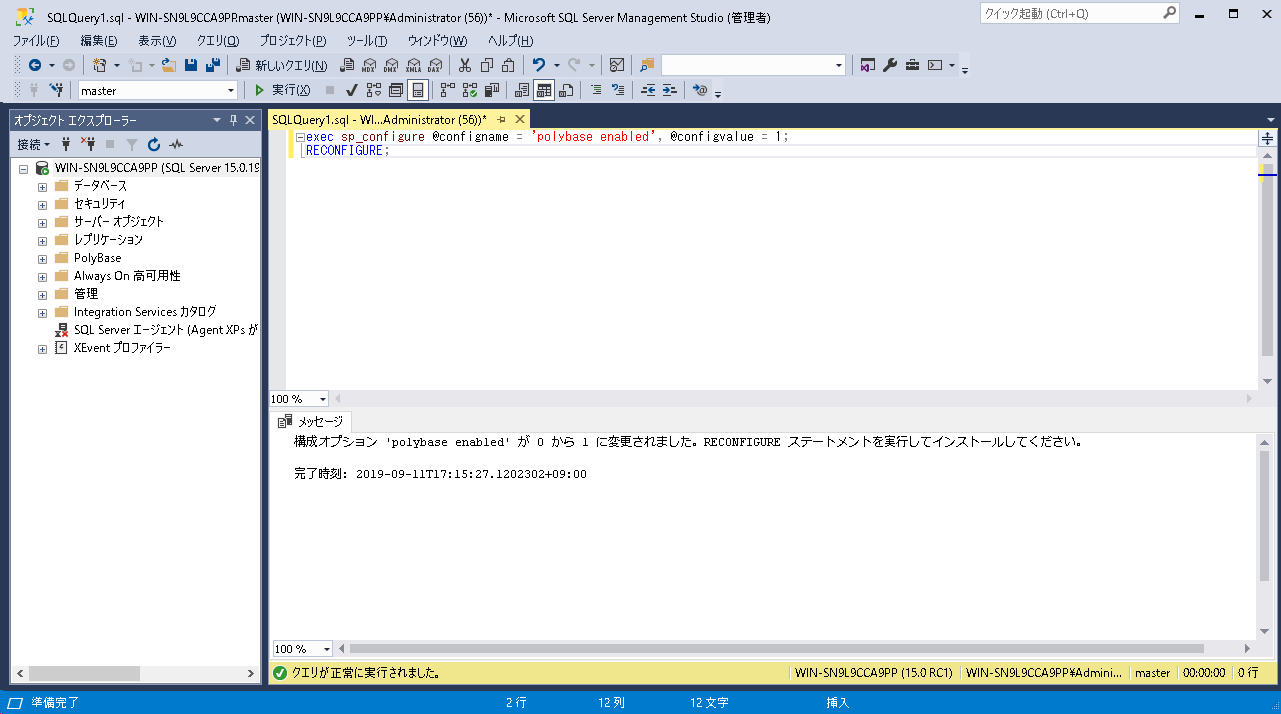
構成オプション「polybase enabled」の設定値が0から1に変更され、有効化したことが分かります。これでPolyBaseを使用する準備が整いました。
データ仮想化の検証
今回は、以下のOracleのテーブルを外部テーブルとして設定し、SQLServerのテーブルと結合してみようと思います。
Oracleテーブル情報
| RDBMS: | ORACLE12cR2 |
| OS: | Oracle Linux 7.2 |
| インスタンス: | orcl |
| PDB: | orclpdb |
| スキーマ: | ora_pdb |
| テーブル: | ora_tbl |
テーブル定義
| COL1 | COL2 | COL3 |
| number(8,0) | DATE | Varchar(8) |
データ
| COL1 | COL2 | COL3 |
| 1 | 2019/9/15 | AAAA |
| 2 | 2019/9/16 | BBBB |
| 3 | 2019/9/17 | CCCC |
| 4 | 2019/9/18 | DDDD |
| 5 | 2019/9/18 | AAAA |
SQLServerテーブル情報
| テーブル: | mss_tbl |
テーブル定義
| COL1 | COL2 |
| Decimal(8,0) | Varchar(8) |
データ
| COL1 | COL2 |
| 1 | YYYYY |
| 2 | ZZZZZ |
まずは外部テーブルの設定といきたいところですが、Oracleのバージョンが12cの場合、以下の事前準備が必要です。
- 初期化パラメータ「SEC_CASE_SENSITIVE_LOGON」の値を「FALSE」に変更
→Oracle12cでは当該パラメータが「TRUE」となっています。 - sqlnet.oraに以下のパラメータを追記
SQLNET.ALLOWD_LOGON_VERSION_SERVER=11
→1をFALSEにした場合、当該パラメータのデフォルトは12であり、パスワードの大文字小文字無効化がサポートされていないためユーザがロックアウトとなります。
それを回避するために、パラメータの値を11以下にする設定が必要です。 - パスワードの変更
→2までの作業実施後、検証で使用するユーザでsqlplusにログインします。
ここでORA-01017のエラーとなった場合、対象ユーザには対応するパスワードバージョンが無ない状態です。
alter user identified by < password >
コマンドを実行してパスワードを変更することで、対応したバージョンが作成されます。
また、SQLServer側でも外部テーブルを作成するデータベースに対して、以下の事前準備が必要です。
- マスターキーの作成
→以下のコマンドを実行して作成します。CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
さて、それでは外部テーブルの設定を行います。外部テーブル作成までの流れは以下の通りです。
- データスコープの作成:
外部テーブルに接続するユーザを登録します。コマンドは以下の通りです。CREATE DATABASE SCOPED CREDENTIAL <データスコープ名> WITH IDENTITY = '<ユーザ名>', Secret = '<パスワード>';
ユーザ名とパスワードはデータベースのものを設定します。 - 外部データソースの作成
外部テーブルの接続情報を登録します。コマンドは以下の通りです。
CREATE EXTERNAL DATA SOURCE <データソース名> WITH ( LOCATION = '<ベンダー名>://<ホスト名 or="" ip="">:<ポート>', CREDENTIAL = <データスコープ名>)
今回の場合、ベンダー名には「oracle」、データスコープ名には1で作成したものを設定します。 - 外部テーブルの作成
CREATE EXTERNAL TABLE <外部テーブル名>
(<カラム名> <データ型> [COLLATE …]
[,<カラム名> <データ型> [COLLATE…]]…
)
WITH
(LOCATION='<データベース名>.<スキーマ名>.<テーブル名>’
,DATA_SOURCE=<外部データソース名>
);
データ型については、適宜対応したものを設定してください、COLLATE句は事前に設定する必要はありません。(コマンド実行後、エラーメッセージに設定値が表示されます。)
外部データソースには2で作成したものを設定します。
検証結果
上記コマンドを実行した結果は以下の通りです。
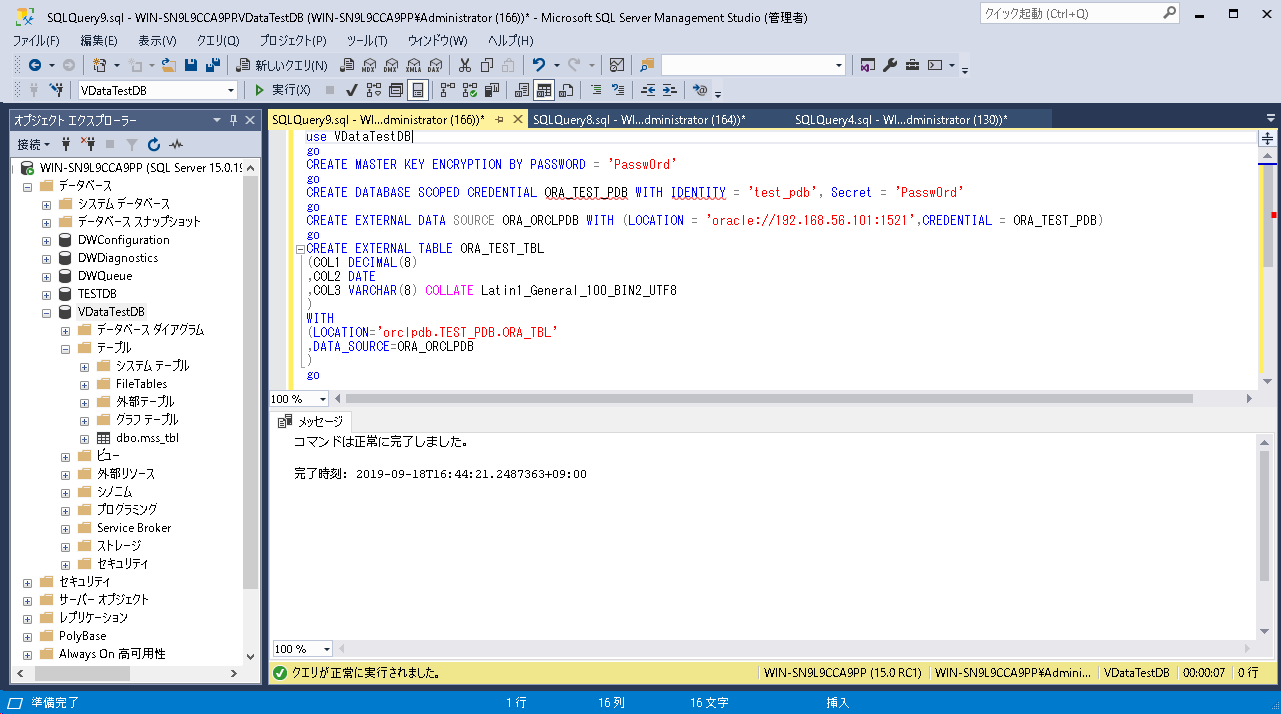
外部テーブルを参照してみました。
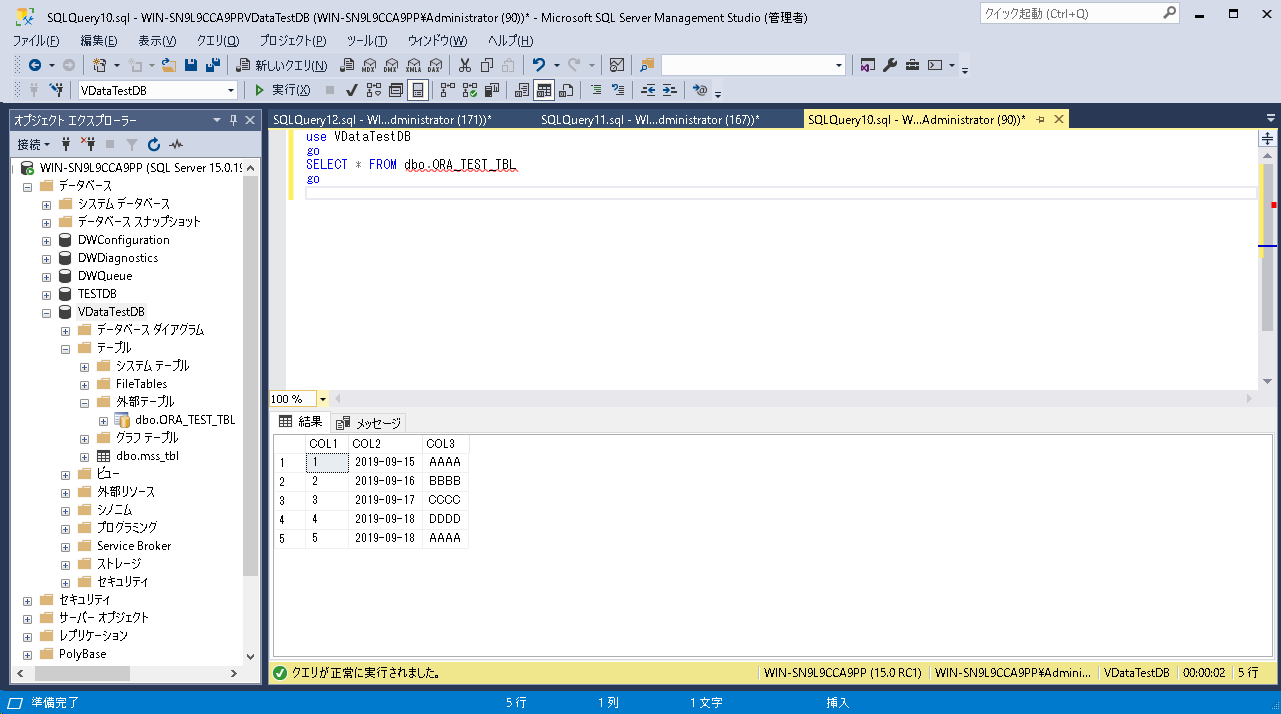
外部テーブルとして設定したOracleのテーブル内のデータが表示できました。
次にSQLServerのmss_tblと結合してみました。
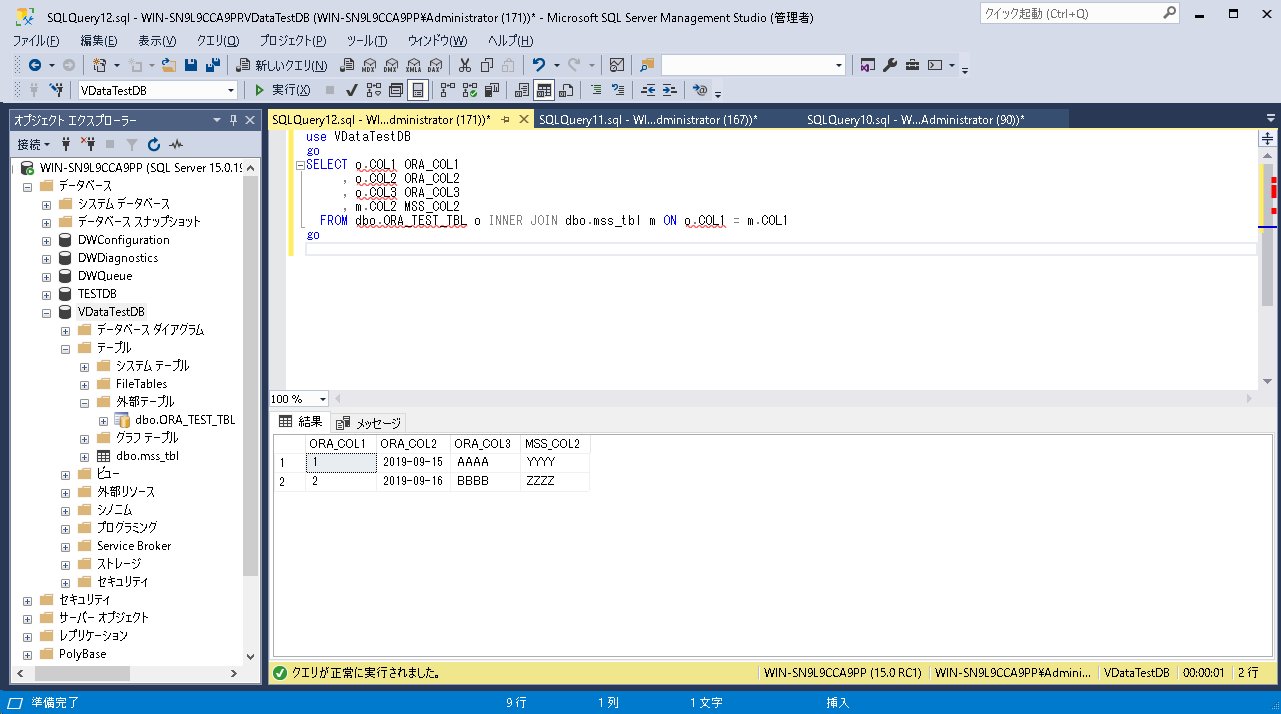
結合条件に合致する行のみ表示されています。
簡単な検証でしたが、SQL Server上で他ベンダーDBのテーブルを結合可能なことが確認できました。今回の検証を踏まえた所感ですが、導入時に仮想データもDWHなどのシステムと同様に外部テーブルの設計が必要なため、 設計フェーズの工数に関しては大差ないと思います。
しかし、導入後の運用において、要件追加等により追加または削除したいデータが発生した場合は、データのインポートを考慮する必要が無いため、設計変更に対するハードルはだいぶ低くなるのではないでしょうか。
(まあ、全データをインポートする場合はDWHなどのシステムでも同じだとは思いますが。。。)
仮想データのメリット・デメリット
今回、パフォーマンスについての検証は行いませんでしたが、DWHなどのシステムと比較して、以下のようなメリット、デメリットがあると思います。
仮想データのメリット
- データインポート等の処理が不要のため、運用コストが削減できる。
- テーブル定義変更等におけるデータ追加・削除について、ビューの定義を変更する場合と同様のため、迅速かつ柔軟に対応できる。
仮想データのデメリット
- 外部データベースとのネットワークがボトルネックとなり、大量データのスループットが遅くなる可能性がある。
デメリットで上げた項目は、PolyBaseスケールアウトグループとして並列処理化することで、どこまで対抗できるかというところも興味をそそられますね。
今回の検証は以上です。
最後まで読んでいただき、ありがとうございました。
















