Dr.SumのPython連携機能を使った機械学習

BI技術者の雑記
今回は、Dr.SumのPython連携機能を使って、KaggleのTitanicのチュートリアルを機械学習(ランダムフォレスト)で予測する方法をご説明します。
※Dr.SumのPython連携機能の説明がメインなので、ランダムフォレストやPythonの細かい説明は割愛します。
1. 手順① 環境構築
前提として、Dr.Sumサーバがインストールされている必要があります。(Ver.5.6以上)
①-1 データの準備
まず、Kaggleサイトから「タイタニック号の生存者データ」を入手します。
「training set (train.csv)」「test set (test.csv)」の両方をダウンロードしてください。
次に、入手したデータをDr.Sumのテーブルに登録します。
テーブルのデータをインメモリ化します。
「Dr.Sum 5.6 In-Memory Server」のサービスが起動しているか確認し、起動していない場合は起動します。

作成したテーブルの上で右クリックし、「プロパティ」→「インメモリ化する」を選択します。
もう一度テーブルの上で右クリックし、「インメモリ」→「データをロード」を選択します。
これでデータの準備は完了です。
①-2 Dr.Sumサーバの設定
| <環境情報> | |
| Dr.Sum | Localhost:6001 |
| Python連携ルート設定パス | C:DrSum56Serversamplesudtf-py |
| クライアント用Python環境 | C:DrSum56AdminToolsudtf-pythonpython |
| サーバ用Python環境 | C:DrSum56IMServerlaunchpythonenvpython |
「Dr.Sum 5.6 Launch Server」のサービスが起動しているか確認し、起動していない場合は起動します。
Dr.Sumのクライアントおよびサーバ用Python環境に、コマンドラインから使用するライブラリをインストールします。
例:C:DrSum56AdminToolsudtf-pythonpythonpython.exe -m pip install scikit-learn
2. 手順② 予測モデルの作成
Dr.Sumに登録したトレーニングデータを使用して、予測モデルを作成します。
②-1 予測モデル作成用スクリプトの作成
<ファイル名>
C:/DrSum56/Server/samples/udtf-py/script/titanic_train.py
<スクリプト>
import io
import pandas as pd
from sklearn.model_selection import train_test_split
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import mean_squared_error
import numpy as np
import csv
# Dr.SumからODBC接続で訓練データを取得
def import_data():
import pyodbc
con = pyodbc.connect(DRIVER="Dr.Sum 5.6 ODBC Driver",
HOST="localhost", DATABASE="test", trusted_connection="yes",
user="Administrator", password="", port = "6001"
)
TBL = "titanic_train"
query = "SELECT * FROM {tbl} ;".format(tbl=TBL)
train_data = pd.read_sql(query, con)
return train_data
def train(context,input):
input = preprocess(input)
# 訓練データとバリデーション用データを7:3で分割
train_x, test_x ,train_y, test_y = train_test_split(
input.drop("Survived", axis = 1).values,
input["Survived"].values,
test_size = 0.3, random_state = 0)
model = RandomForestClassifier(random_state=0)
model.fit(train_x, train_y)
y_pred = model.predict(test_x) # 予測
mse= mean_squared_error(test_y, y_pred) # 評価
# アウトプットとなるdataframeを定義
model_status = pd.DataFrame(columns = ["description", "value"])
# 各説明変数の重要度データをアウトプットとして追加する。
for i, feat in enumerate(input.columns[input.columns!="Survived"]):
model_status.loc[feat] = [feat, model.feature_importances_[i]]
# モデルの保存
stream = io.BytesIO()
joblib.dump(model, stream)
context.write_remote_file("PY_DATA_ROOT/titanic_model.sav", stream.getvalue())
return model_status
def preprocess(df):
df['Fare'] = df['Fare'].fillna(df['Fare'].mean())
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Embarked'] = df['Embarked'].fillna('Unknown')
df['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0)
df['Embarked'] = df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2, 'Unknown': 3} ).astype(int)
df['Age'] = df['Age'].astype(int)
df['Fare'] = df['Fare'].astype(int)
df['Survived'] = df['Survived'].astype(int)
df['Pclass'] = df['Pclass'].astype(int)
df['SibSp'] = df['SibSp'].astype(int)
df['Parch'] = df['Parch'].astype(int)
df = df.drop(['Cabin','Name','PassengerId','Ticket'],axis=1)
return df
def main():
import dspy.emulator
train_data = import_data()
# エミュレータを使ったデバッグ
builder=dspy.emulator.EmulatorBuilder(train_data)
emulator=builder.buildSerial(
py_file_path = "PY_SCRIPT_ROOT/titanic_train.py",
func_name = "train",
schema_func_name = "model_status",
)
result=emulator.execute(create_schema_mode = True) # Trueで結果表スキーマ取得関数を出力するようにする
print(result)
if __name__ == "__main__":
main()
<スクリプトの概要>
| 関数 | 内容 |
| def import_data() | Dr.Sumからのデータ取得 |
| def preprocess() | データのクレンジング |
| def train() | モデルの学習、作成 |
| def main() | メイン処理 |
②-2 実行
以下のコマンドでスクリプトを実行します。
C:DrSum56AdminToolsudtf-pythonpythonpython.exe C:DrSum56Serversamplesudtf-pyscripttitanic_train.py
モデルの内容が表示されます。
description value
0 Pclass 0.091828
1 Sex 0.285340
2 Age 0.298141
3 SibSp 0.059709
4 Parch 0.038032
5 Fare 0.185667
6 Embarked 0.041283
どうやら性別、年齢が生存に大きく影響していそうです。
モデルは同フォルダに作成されるので、作成されたファイルをC:DrSum56Serversamplesudtf-pydataにコピーしてください。
※今回のファイル名は「titanic_model.sav」です。
<補足>
実行すると下記のメッセージも表示されます。
この関数を同スクリプトに追加すると、コマンドラインで実施したことがDr.Sumサーバからも実施できますが、Dr.Sumサーバの呼び出しは「手順③ 予測の実行」で説明するため割愛します。
以下のスタブ関数をC:DrSum56Serversamplesudtf-pyscripttitanic_train.pyにコピーしてください。
def model_status(input_schema):
return ['description VARCHAR', 'value NUMERIC']
3. 手順③ 予測の実行
「手順② 予測モデルの作成」で作成したモデルをDr.Sumサーバから呼び出し、テストデータの生存者判定を行います。
スクリプトはPythonで作成しますが、実行はDr.Sumサーバから呼び出します。
③-1 予測実行用スクリプトの作成
<ファイル名>
C:/DrSum56/Server/samples/udtf-py/script/titanic_train.py
<スクリプト>
import pandas as pd
import joblib, io
def predict_schema(input_schema):
return ['PassengerId NUMERIC', 'Survived NUMERIC']
def predict(context, input):
test_data = preprocess(input)
load_stream = io.BytesIO(context.read_remote_file(f"PY_DATA_ROOT/titanic_model.sav"))
model = joblib.load(load_stream)
y_pred = model.predict(test_data.values) # 予測
output = test_data.assign(Survived = y_pred)
input = input['PassengerId']
output = output['Survived']
output = pd.concat([input, output],axis=1)
return output
def preprocess(df):
df['Fare'] = df['Fare'].fillna(df['Fare'].mean())
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Embarked'] = df['Embarked'].fillna('Unknown')
df['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0)
df['Embarked'] = df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2, 'Unknown': 3} ).astype(int)
df['Age'] = df['Age'].astype(int)
df['Fare'] = df['Fare'].astype(int)
df['Pclass'] = df['Pclass'].astype(int)
df['SibSp'] = df['SibSp'].astype(int)
df['Parch'] = df['Parch'].astype(int)
df = df.drop(['PassengerId','Cabin','Name','Ticket'],axis=1)
return df
<スクリプトの概要>
| 関数 | 内容 |
| def preprocess() | データのクレンジング |
| def predict() | モデルの読み込み、予測 |
| def predict_schema() | 結果のインターフェース |
※Dr.Sumサーバから呼び出されるため、main処理はありません。
③-2 予測の実行(Dr.SumサーバのSQL ExecutorでSQL実行)
SELECT
T.*
FROM
udtf::serial_py(
titanic_test,
py_file_path='PY_SCRIPT_ROOT/titanic_predict.py',
func_name='predict',
schema_func_name='predict_schema'
) T
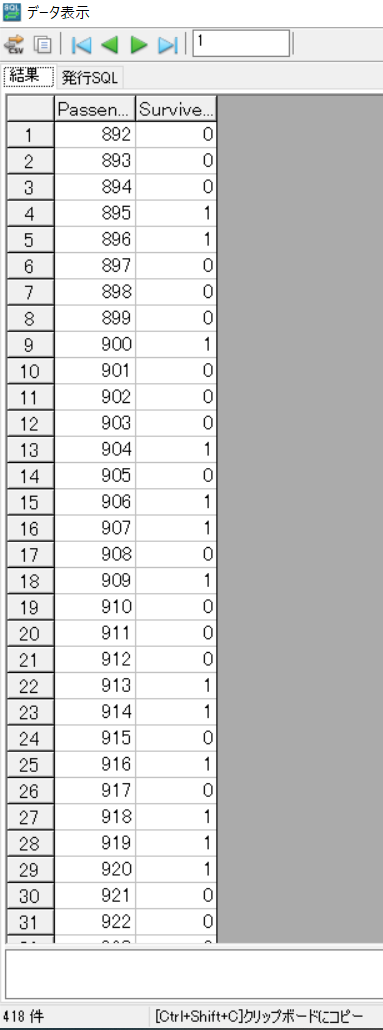
実行すると予測結果が画面に表示されます。
※Survived=1は生存と予測
4.おわりに
今回は、Dr.SumのPython連携機能を使って、Kaggleの「タイタニックの生存者予測」を実施する方法についてご紹介しました。
環境構築は多少手間がかかりますが、構築後の予測の実行は比較的簡単にできると思います。











