第1回:基本セットアップ編

目次
はじめに
皆様、はじめまして。マルチDBソリューション部の山本と申します。
DB関連の本部に所属していますが、DBに限らずハードウェアやOS・ソフトウェア関連など日々いろいろな対応をしています。今回、Oracle Autonomous Data Warehouse Cloud(以下、ADW Cloud)について、検証してみました。
本記事は、Oracle社のWebサイト情報やハンズオン資料などを元に、Oracle Cloudの環境で実施した内容となります。
クラウド全般的に言える内容ではありますが、クラウド環境は日々改善され、機能追加やセキュリティ強化など様々なアップデートが頻繁に適用されています。その為、本記事の画面と実際の画面が異なる可能性がございますが、ご容赦の程宜しくお願いします。
※本内容は2018年10月に検証した内容となります。
前提
本記事ではOracle Cloudが利用できる状態から開始した内容となります。
1. ADW Cloud インタンスのプロビジョニング
早速ですが、Oracle Cloudに接続してインスタンスをプロビジョニングします。インスタンスのプロビジョニングは、以下の3ステップで作成できますので非常に簡単です。
| ●ステップ1:Oracle Cloudにログイン ●ステップ2:Autonomous Data Warehouseのコンソールを起動 ●ステップ3:プロビジョニング設定およびインスタンス作成 |
ステップ1:Oracle Cloudにログイン
インターネットブラウザー(IEなど)で以下のURLにアクセスします。
URL:https://cloud.oracle.com/home
メニューバーの「Sign in」をクリックするとクラウドアカウントを入力する画面が表示されます。
| 【参考】日本語表示 メニューバーのプルダウンメニューで日本語にすることができます。 |
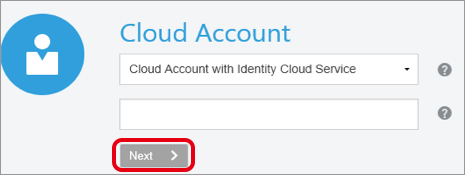
お持ちのクラウドアカウント名を入力して、「Next」をクリックします。
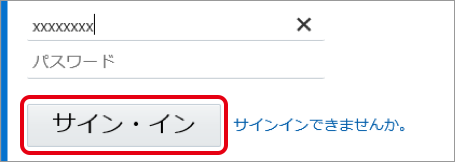
「クラウドアカウント名」と「パスワード」を入力して、「サイン・イン」をクリックします。
認証が成功するとダッシュボードが表示されます。
ステップ2:Autonomous Data Warehouseのコンソールを起動
ダッシュボードで「Database Classic」をクリックします。
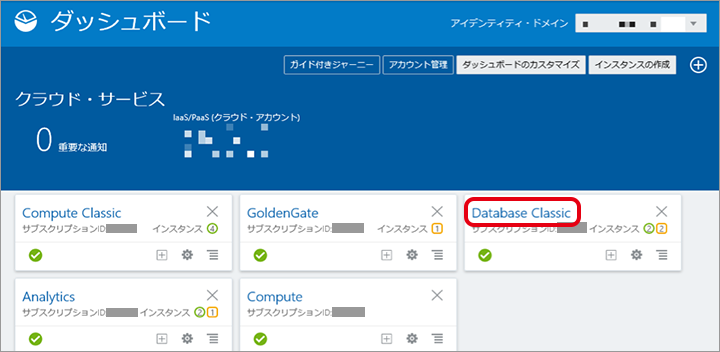
※新規の場合は、ダッシュボードにメニューが表示されません。本画面は表示設定など既に実施した画面となります。
画面右上の「サービス・コンソールを開く」をクリックします。
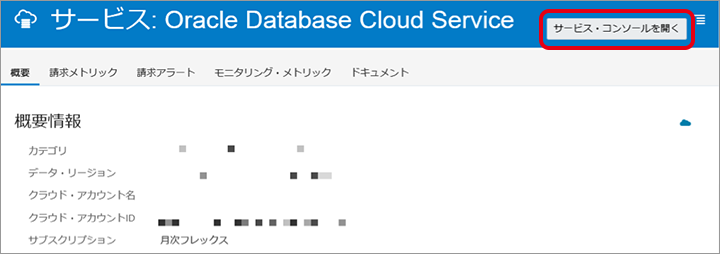
画面左上の「ナビゲーションメニュー」をクリックします。

ナビげ―ジョンメニューで「Autonomous Data Warehouse」をクリックします。
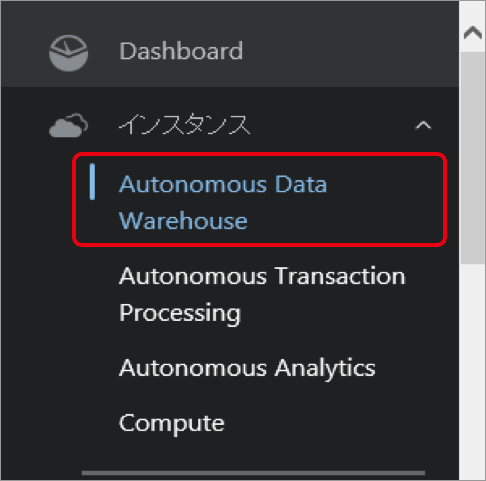
| 【参考】日本語表示 ダッシュボードのカスタマイズ設定して、ダッシュボードの表示項目に「Autonomous Data Warehouse」を表示させることも可能となります。 アクセス頻度が高い場合やせっかちな人にはカスタマイズをお勧めします。 |
ステップ3:プロビジョニング設定およびインスタンス作成
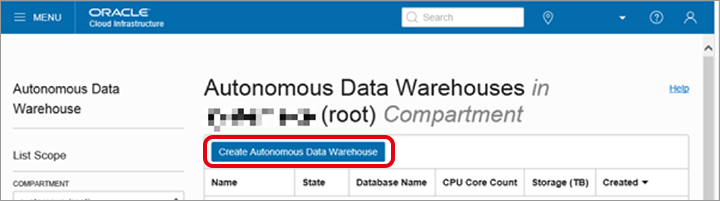
「Autonomous Data Warehouse」のコンソール画面で「Create Autonomous Data Warehouse」をクリックします。
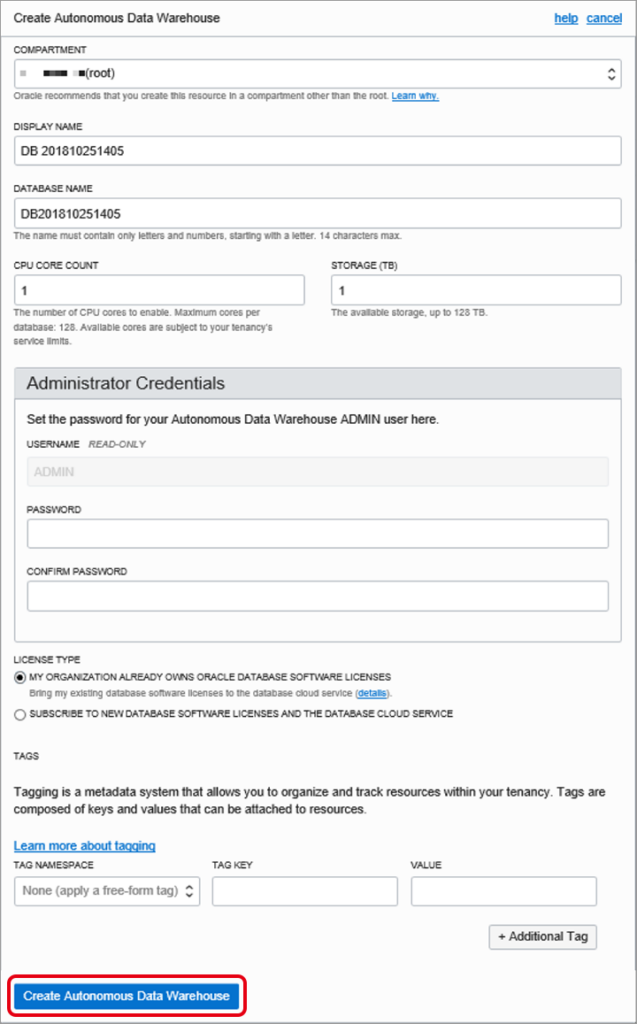
以下の項目を入力して、「Create Autonomous Data Warehouse」をクリックします。
| 設定項目 | 設定値 |
|---|---|
| 全般 | |
| COMPARTMENT | xxxxx(デフォルトで選択済み) |
| DISPLAY NAME | 任意の名称 ※コンソールの「Name」などに表示する名称 |
| DATABASE NAME | 任意の名称 ※データベースの名称(最大14文字) |
| CPU CORE COUNT | CPU数(デフォルト値「1CPU」) |
| STORAGE(TB) | ディスク容量(デフォルト値「1TB」) |
| Administrator Credentials | |
| USERNAME READ-ONLY | ADMIN ※READ-ONLYでデフォルトで作成される |
| PASSWORD | 「ADMIN」のパスワード ※パスワードの制限事項は以下の通りです。 文字数: 12~30文字 大文字数: 1文字以上 小文字数: 1文字以上 英数文字数: 1文字以上 特殊文字: 二重引用符(”)は使用不可 その他: 最後に使用した4つのパスワードとは異なるもの。24時間以内と同一は不可 |
| CONFIRM PASSWORD | 「ADMIN」のパスワード(確認用) |
| LICENSE TYPE | ☑ MY ORGANZATION ALREADY OWNS ORACLE DATABASE SOFTWARE LICENSES(デフォルトで選択済み) |
| □SUBSCRIBE TO NEW DATABASE SOFRTWARE LICENSES AND THE DATABASE CLOUD SERVICE | |
| TAGS | |
| TAG NAMESPACE | None (apply a free form tag) |
| TAG KEY | – |
| VALUE | – |
インスタンスのプロビジョニングが開始され、暫くするとインスタンスのプロビジョニングが完了します。
| 【参考】 インスタンスを「Terminate」した後、暫くするとコンソール上で表示されなくなりますが、同一の名称で再度作成すると既に登録済みとしてエラーになりました。 他の人が作成および削除したなど同一の名称で再作成する際は、注意が必要となります。 |
2. ADW Cloudインタンスへの接続
各インスタンスへの設定手順としては、以下の3ステップとなります。「1. ADW Cloud インタンスのプロビジョニング」同様で簡単に接続できます。
| ●ステップ1:[事前]接続ツール(SQL Developer や Oracle Clientなど)の準備 ●ステップ2:[共通]クレデンシャル・ウォレットのダウンロード ●ステップ3:[個別]接続ツールの設定 |
インスタンスへの接続方法は幾つかありますが、今回はステップ3で以下の接続方法をご紹介します。
① SQL*PLUS
② SQL Developer
ステップ1:[事前]接続ツール(SQL Developer や Oracle Clientなど)の準備
接続で使用したツールをOracleのサイトなどよりダウンロードしてファイルの展開や必要に応じてインストールを実施します。
※本記事ではステップ1は前提準備とし、ステップ2よりご紹介します。
ステップ2:[共通]クレデンシャル・ウォレットのダウンロード
まずは各インスタンスへの接続設定する作業の前にクレデンシャル・ウォレットをダウンロードします。
「1. ADWインタンスのプロビジョニング」を参考にADWインスタンスを開きます。
画面中央にインスタンス一覧のメニューから「Service Console」をクリックします。
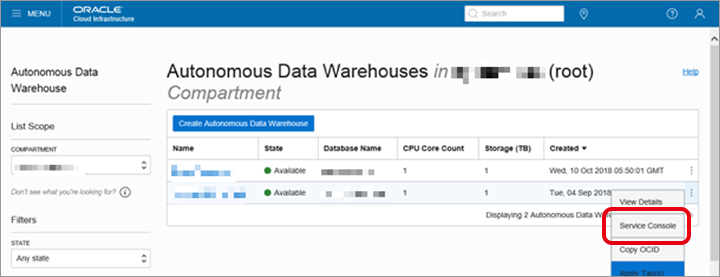
サイン・イン画面が表示されますので、以下の内容を入力して、「Sign in」をクリックします。
| 設定項目 | 設定値 |
|---|---|
| USERNAME | admin |
| PASSWORD | ADWインスタンスのプロビジョニング時に設定したパスワード |
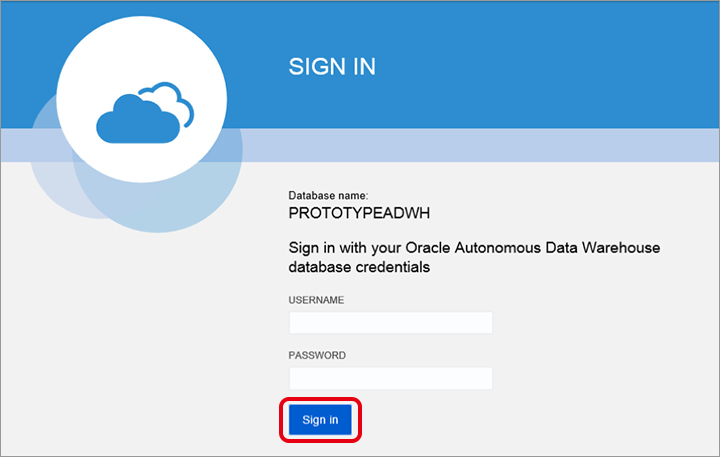
画面左の項目から「Administration」をクリックして、その後に画面中央の「Download Client Credentials」の順にクリックします。
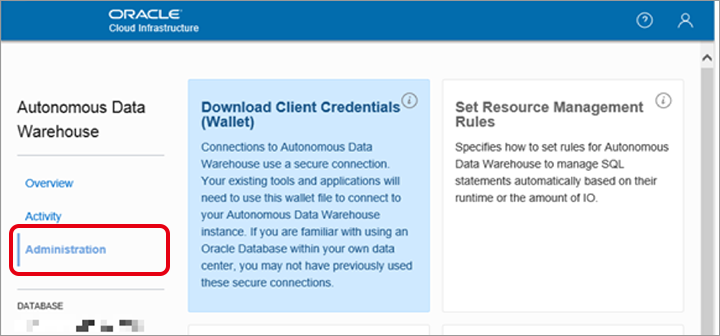
ウォレットのパスワードを設定して「Download」をクリックします。
※ウォレットのパスワードはDBに接続する際に利用します。JDBCアプリケーションのkeystoreなどに利用されますので、「Admin」とは別のパスワードを付与して下さい。
ステップ3:[個別]接続ツールの設定
① SQL*PLUS を利用したDB接続
一般的に使用されているCUIツールの接続方法をご紹介します。
1. Oracle Clientのインストール
Oracle Client のバージョンは12.2.0.1以降をインストールします。
2. ウォレットファイルの展開
ステップ2でダウンロードしたウォレットファイルを解凍(unzipなど)します。
3. 設定ファイルの準備
以下の設定ファイルに対して修正または追記します。
「sqlnet.ora」に追記および修正
WALLET_LOCATION =
(SOURCE =
(METHOD = file)
(METHOD_DATA = (DIRECTORY="<任意のディレクトリ>"))
)「tnsnames.ora」の配置または追記
ダウンロードしたウォレットファイルに含まれる「tnsnames.ora」を所定の場所に配置するか、または既存の「tnsnames.ora」に接続情報を追記します。
4. SQL*PLUSから接続
SQL*PLUSを起動して、以下の内容を参考にして接続する。
| 設定項目 | 設定値 |
|---|---|
| USERNAME | admin |
| PASSWORD | ADWインスタンスのプロビジョニング時に設定したパスワード |
| 接続名 | 「3」で設定した接続情報 |
| 【参考】DBサービスの補足 DBサービスは3種類提供されており、クレデンシャルファイルの「tnsnames.ora」に接続情報が含まれています。3種類のサービスはリソース・マネージャによるパフォーマンスの並列度を3段階のレベルで定義されています。本記事は基本セットアップの為、DBサービスは「LOW」で接続しています。 |
| 割当てリソース | 同時実行数 | 実行処理 | |
|---|---|---|---|
| HIGH | 最多 | 最少 | パラレル実行 |
| MEDIUM | 小 | 多 | パラレル実行 |
| LOW | 最少 | 最多 | シリアル実行 |
【参考】接続サンプル
C:> sqlplus /nolog
SQL> conn admin/<パスワード>@xxxx_low
接続されました。
SQL>② SQL Developer を利用したDB接続
GUIツールでは、SI Object Browser を使用している方が多いと思いますが、本記事ではOracle社が提供しているSQL Developerでの接続をご紹介します。
本記事では準備はご紹介していませんが、ダウンロードして展開したフォルダの「sqldeveloper.exe」を実行します。

SQL Developerが起動後、画面左メニュー「+」を展開して「接続の作成」をクリックします。
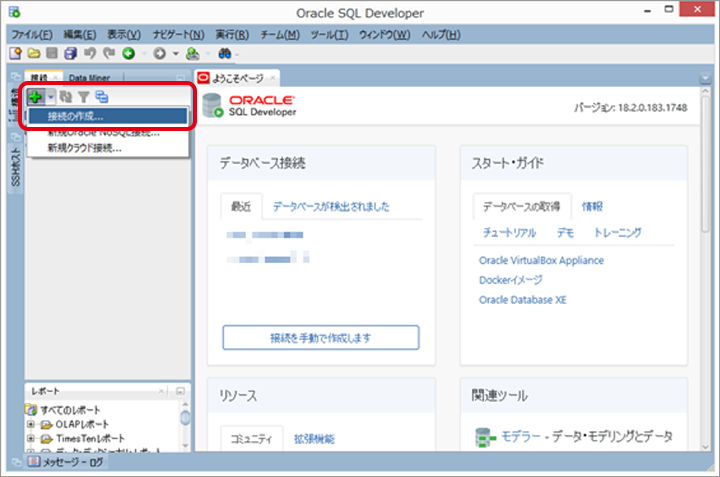
以下の項目を参考に①~③の項目を入力します。
| 区分 | 設定項目 | 設定値 | |
|---|---|---|---|
| ① | 全般 | 接続名 | 任意の名称 |
| ユーザー名 | admin | ||
| パスワード | ***** | ||
| パスワードの保存 | 任意 | ||
| ② | Oracle | 接続タイプ | クラウド・ウォレット |
| ロール | デフォルト | ||
| 構成ファイル | ダウンロードしたウォレットファイル ※Zipファイルを指定 | ||
| サービス | <DB名>_low ※ | ||
| ③ | HTTPプロキシの使用 | ※環境に応じて設定 | |
| OSSの構成 | ※環境に応じて設定 | ||
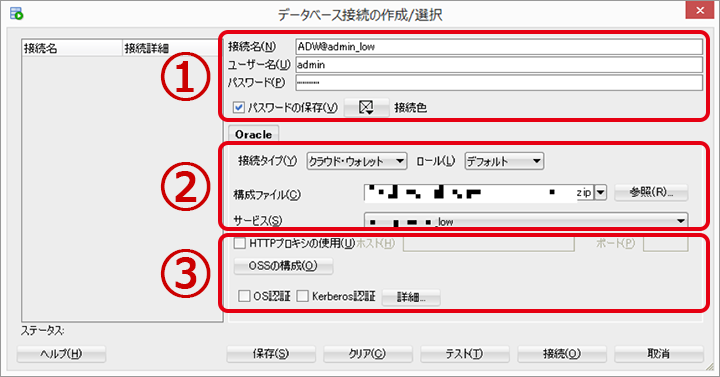
設定完了後、「テスト」をクリックすると接続確認することができ、設定に不備があればエラーの内容が表示されます。
「接続」をクリックするとインスタンスへ接続されます。「保存」をクリックして設定を保存しておくと次回以降に便利です。
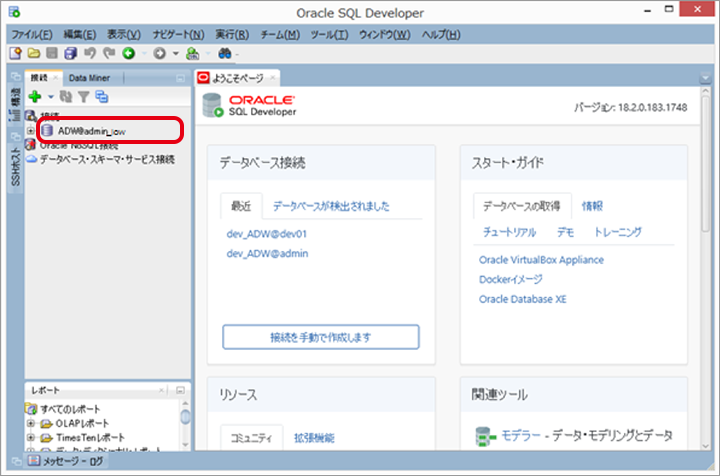
画面左に接続情報が表示されれば、完了となります。
3. データベースサービスとサンプルデータセット
ADW Cloudは、Oracle Sales History(SH)のサンプル・スキーマとStar Schema Benchmark(SSB)データセットを提供しています。
本手順は、約1TBで60億行のファクト表と複数ディメンション表を持つSSBデータセットに対して、サンプルのクエリを実行した内容となります。詳細の内容は以下のURLをご参照下さい。
SQL Developerを起動し、「2. ADWインタンスへの接続」で作成した接続情報でインスタンスに「DBサービス : LOW」で接続して、以下のSQLを実行します。
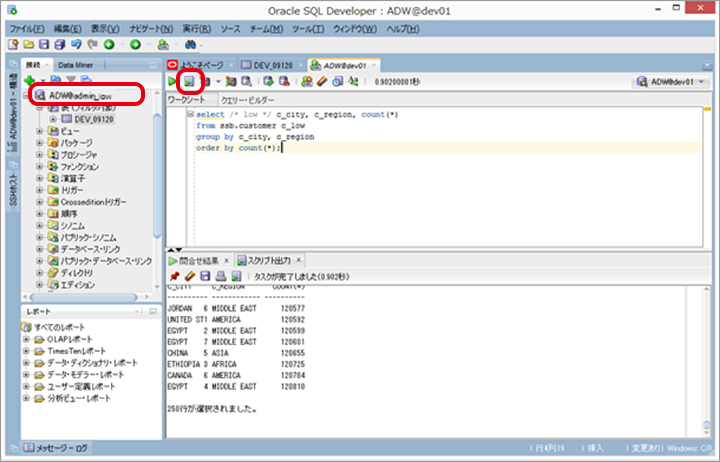
画面上部に処理時間、画面下部に選択行数などが表示されます。
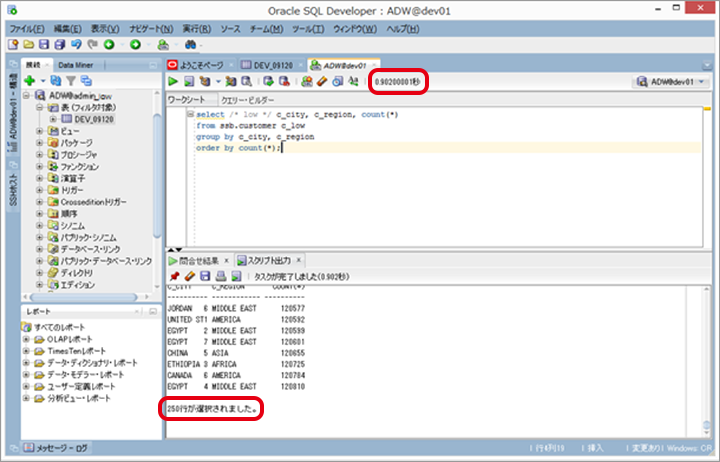
【参考】サンプルSQL
select /* low */ c_city, c_region, count(*)
from ssb.customer c_low
group by c_city, c_region
order by count(*);4. ローカルファイルの読込み
環境を準備しても分析にはデータが必要となりますので簡単ではありますが、SQL Developerでローカルファイルのデータ取込みをご紹介します。
1. データを取込むテーブルを準備
対象のインスタンスに接続し、データを取込むテーブルを作成します。
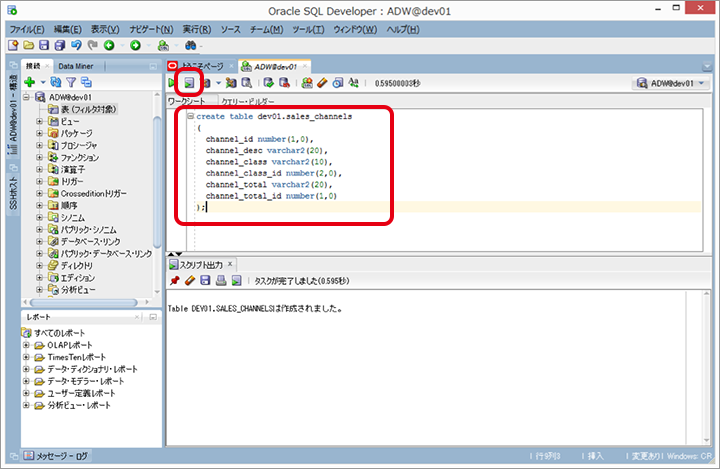
【参考】実行したSQLのサンプル
create table dev01.sales_channels
(
channel_id number(1,0),
channel_desc varchar2(20),
channel_class varchar2(10),
channel_class_id number(2,0),
channel_total varchar2(20),
channel_total_id number(1,0)
);2. データを取込み
画面左のリストで「1」で作成したテーブルを右クリックして、「データのインポート」をクリックします。
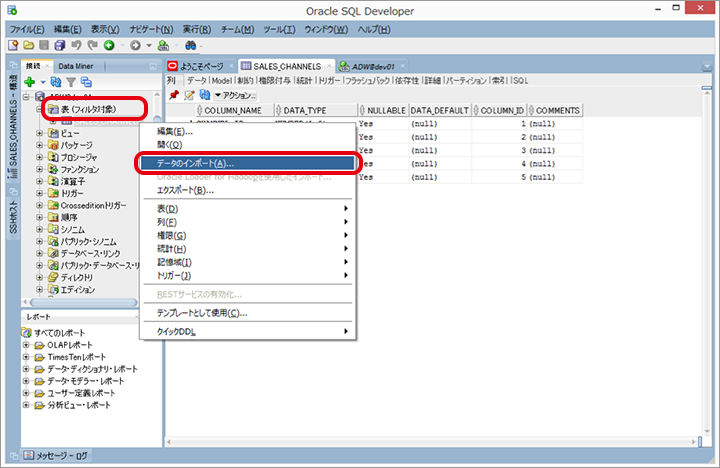
取込むファイルの内容に基づきファイル形式の設定を実施します。設定完了後、「次」をクリックします。
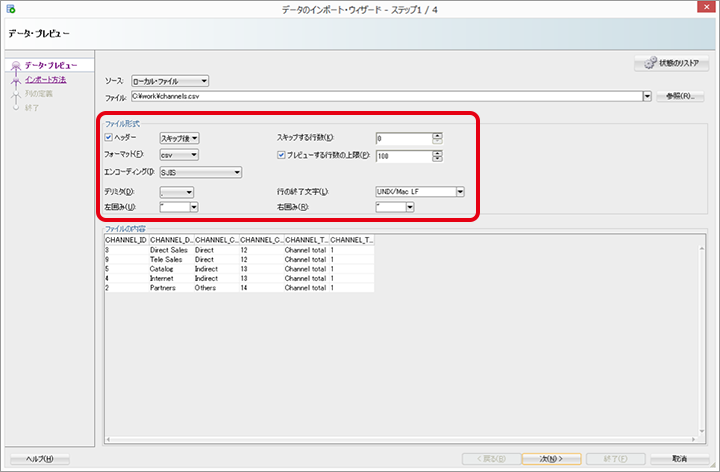
【参考】CSVサンプル
"CHANNEL_ID","CHANNEL_DESC","CHANNEL_CLASS","CHANNEL_CLASS_ID","CHANNEL_TOTAL","CHANNEL_TOTAL_ID"
3,"Direct Sales","Direct",12,"Channel total",1
9,"Tele Sales","Direct",12,"Channel total",1
5,"Catalog","Indirect",13,"Channel total",1
4,"Internet","Indirect",13,"Channel total",1
2,"Partners","Others",14,"Channel total",1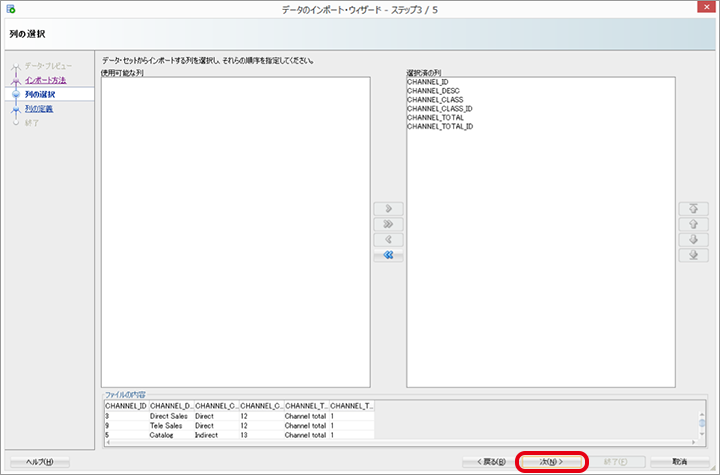
インポートする列情報を確認して、「次」をクリックします。
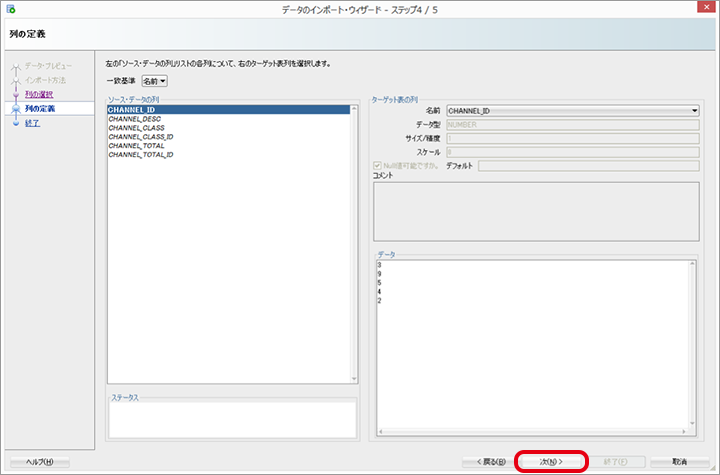
インポートする列情報で不備など無いか確認して、「次」をクリックします。
インポートするサマリー情報を確認して、「終了」をクリックします。
インポートが完了すると以下のポップアップが表示されますので、「OK」をクリックします。
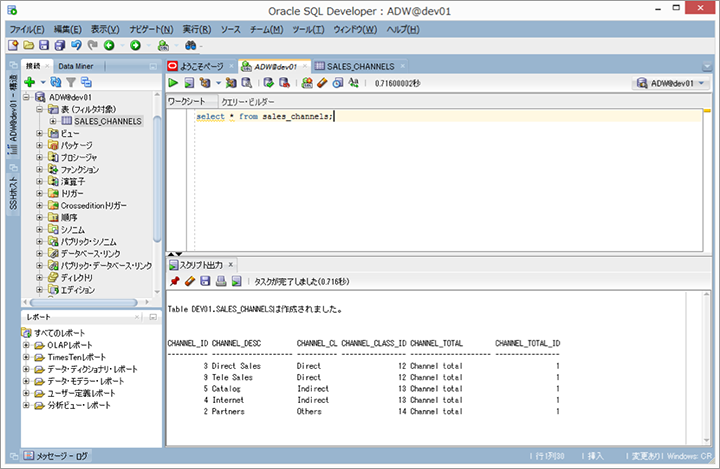
3. インポートしたテーブルの状況確認
「Select」文などでインポートしたデータ件数を確認する。
5. スケジューリングとパフォーマンス
ADW Cloudのリソースの変更対象はCPU数かStorageサイズとなり、メモリーやI/O帯域幅については、CPUリソースに比例して拡張または縮小されます。
ダウンタイムなしで動的にスケールアップやダウンが可能ですので、変更手順のご紹介とリソース変更中にデータ挿入した影響をご紹介します。
1. CPUリソースの増減
ADW Cloudのリソースをスケールアップまたはスケールダウンします。
CPUリソースの増減をオンラインで実施する手順をご紹介します。手順は、CPUリソース「1」⇒「2」に変更した内容となりますが、「2」⇒「1」に縮小する際も同様の手順で実施します。数クリックでリソースが変更でき、非常に簡単です。
Autonomous Data Warehousesのインスタンス一覧よりリソースを変更するインスタンスの「Name」をクリックします。
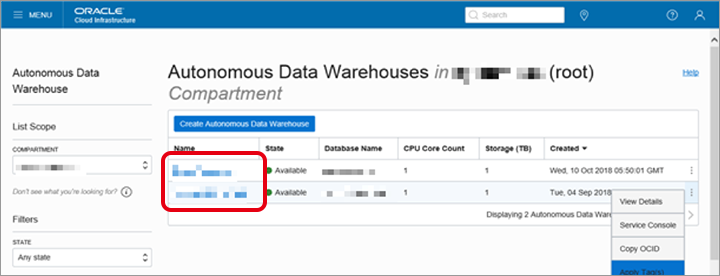
インスタンスの詳細画面が表示されますので、画面上部の「Scale Up/Down」をクリックします。
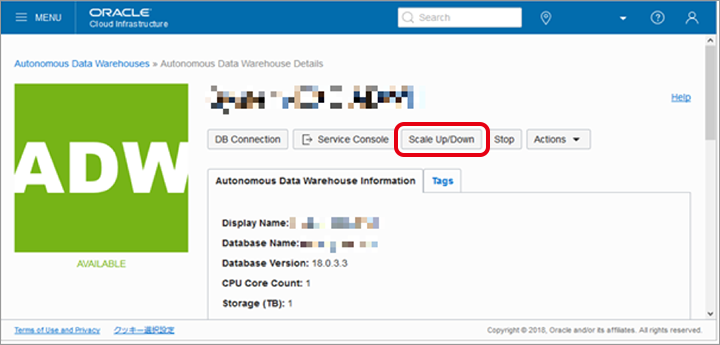
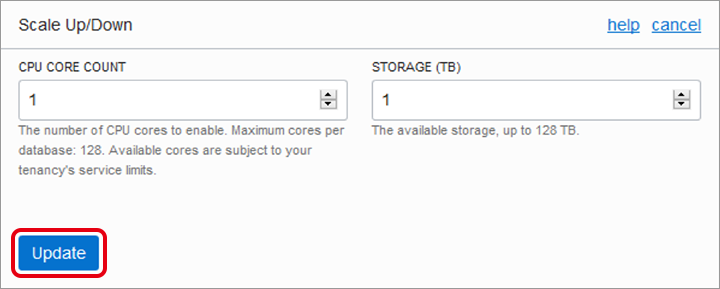
CPUリソースに対して、追加 or 減少させるリソースを入力して「Update」をクリックします。
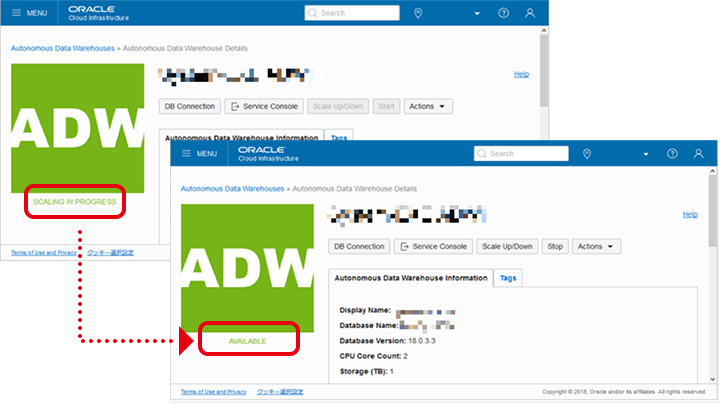
インスタンスの詳細画面が表示されます。
画面左のステータスが「AVAILABLE」が「SCALING IN PROGRESS」になり、処理が完了すると「AVAILABLE」が表示されます。
2. リソース増減時の影響確認
ADW Cloudをスケールアップまたはスケールダウンし、CPUリソースの増減をオンラインで実施した際、パフォーマンスへの影響を確認した内容となります。以下の内容で処理性能(処理時間)の違いを確認しました。
① テスト用のテーブルを作成
② 100万件のCSVファイルを準備し、テストテーブルにデータを挿入
③ データの挿入時にCPUリソースの増加または減少を実行
⇒ リソース固定・増加・減少のそれぞれでデータ挿入時の時間を計測
| 固定 | 1CPU ⇒ 2CPU | 2CPU ⇒ 1CPU | |
|---|---|---|---|
| 1回目 | 4分15秒 | 3分55秒 | 4分00秒 |
| 2回目 | 3分53秒 | 3分59秒 | 4分11秒 |
| 3回目 | 3分59秒 | 4分03秒 | 4分01秒 |
| 4回目 | 4分03秒 | 3分53秒 | 3分50秒 |
| 5回目 | 3分51秒 | 3分56秒 | 3分51秒 |
100万件程度のデータ挿入処理なので、それ程高い負荷状態ではないですが、リソースの変更処理中でも実行中の処理に対する影響は少ない結果となりました。
最後に
性能検証など別途検討していますが、今回は基本セットアップ編となります。
ハイスキルの専門知識があるに越したことはないですが、インスタンスのプロビジョニングやリソースの変更など容易な手順で対応が可能です。その為、ADW Cloudは簡単に始められると考えています。
最後になりますが、弊社は「データベースのオールマイティ企業」を謳っており、データベースに関する経験や知識、技術力を自負しています。データベース関連での課題解決等、必ずやお客様のお役に立てると信じていますので、何かございましたら弊社へご連絡下さい。
それでは、次回をお楽しみに!



