BigData分析基盤検証:Apache Hadoop構築編(Single構成)

技術者が語るOracle Cloud
今回は自社検証環境でデータ分析基盤でもあるHadoopを構築し、Oracle Cloud上で構築した環境との簡単な比較を行いたいと思います。
また、最小構成で HDFSをSingle nodeで設定し検証していきたいと思います。
目次
1.検証環境情報
仮想マシンはVitrual Boxで作成
OS: CentOS7
CPU: 2
Memmory: 4GB
Storage: 30GB
その他必須ソフトウェア等
Hadoopソフトウェア: hadoop-3.1.3.tar.gz
Java version: OpenJDK 1.8.0_252
(※検証の為、FirewallとSELinuxは無効化しています)
2.パッケージの最新化
Rootユーザーで以下のコマンドを実行してパッケージの最新化を行います。
[root@hadoopsingle ~]# yum update #インストール済みのパッケージをアップロード [root@hadoopsingle ~]# yum updgrade #不要になったパッケージの削除
3.Hadoopインストールユーザーの作成
今回は以下のコマンドを実行しHadoopユーザを作成します。
[root@hadoopsingle~]# useradd hadoop [root@hadoopsingle~]# passwd hadoop # ユーザーのパスワードを設定
4.Javaのインストール
以下のコマンドを実行しJavaのインストールを行います。
[root@hadoopsingle~]# yum install java-1.8.0-openjdk-devel.x86_64 # javaをインストール [root@localhost ~]# java -version # javaバージョンの確認 openjdk version "1.8.0_252" OpenJDK Runtime Environment (build 1.8.0_252-b09) OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode) [root@localhost ~]#
5.sshの設定
ローカルにパスワードなしでログインできるようにします。
以下のコマンドをhadoopユーザーで実行し公開鍵を生成します。
[hadoop@hadoopsingle~]# su - hadoop [hadoop@hadoopsingle~]$ ssh-keygen -t rsa #公開鍵の設定 [hadoop@hadoopsingle~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [hadoop@hadoopsingle~]$ chmod 700 ~/.ssh/authorized_keys
一旦rootユーザーに戻りsshの設定ファイルの編集を行います。
[hadoop@hadoopsingle~]# exit
[root@hadoopsingle~]$ vi /etc/ssh/sshd_config #sshの設定ファイルを編集
su - hadoop
#RSAAuthentication yes
PubkeyAuthentication yes #この部分をコメントアウトします。
#AuthorizedKeysFile .ssh/authorized_keys
#AuthorizedKeysCommand none
#AuthorizedKeysCommandRunAs nobody
[root@hadoopsingle~]# systemctl restart sshd #sshdを再起動
[root@hadoopsingle ~]# su - hadoop #hadoop userに戻る
Last login: Sun Jun 14 17:58:51 EDT 2020 on pts/0
[hadoop@hadoopsingle ~]$
以下コマンドを実行し、ローカルにパスワード無しで接続できる事を確認します。
[hadoop@hadoopsingle ~]$ ssh localhost Last login: Sun Jun 14 18:23:49 2020 #passwordが聞かれずログインできる事を確認 [hadoop@hadoopsingle ~]$
6.Hadoopパッケージのダウンロード
以下のURLからHadoopの公式ページにアクセスし、hadoopのパッケージをダウンロードします。
今回は、バージョン3.1.3を使用してみたいと思います。
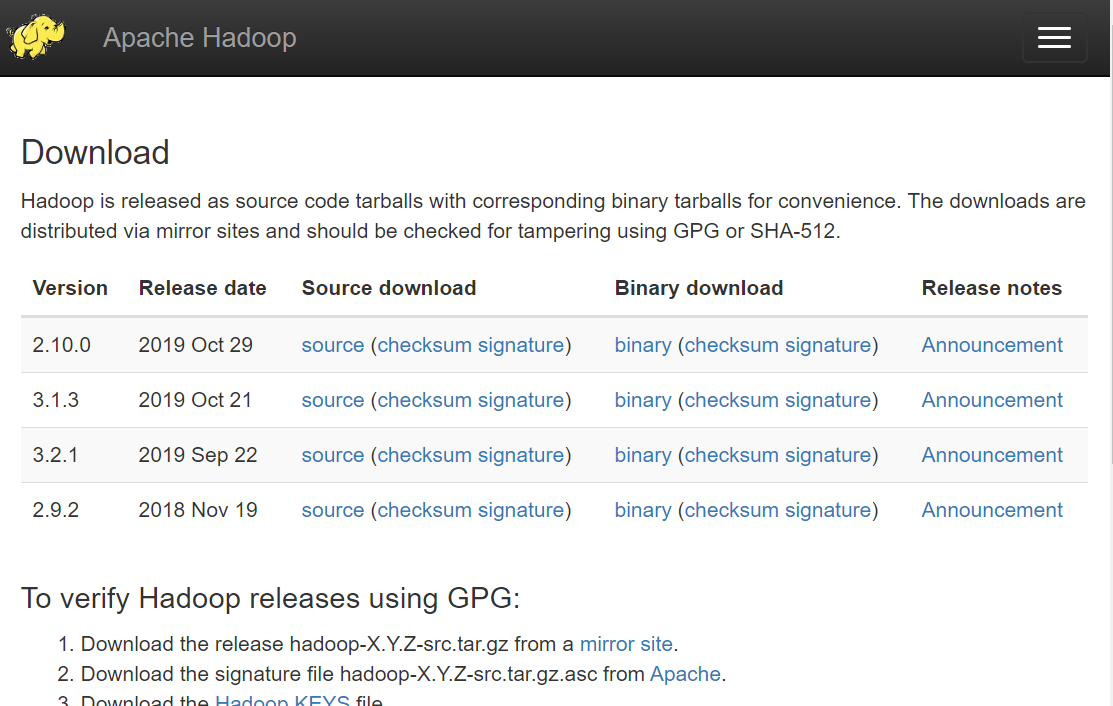
ダウンロードしたパッケージをscpコマンド等を使用し、hadoopユーザーのhomeディレクトリに配置します。
[hadoop@hadoopsingle ~]$ cd [hadoop@hadoopsingle ~]$ ls -l total 330156 -rw-r--r-- 1 hadoop hadoop 338075860 Jun 14 19:16 hadoop-3.1.3.tar.gz [hadoop@hadoopsingle ~]$
7.ユーザー環境変数の設定
以下のコマンドを実行し環境変数を追加します。
[hadoop@hadoopsingle~]$ vi ~/bash_profile export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64/jre export HADOOP_HOME=/home/hadoop/hadoop-3.1.3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin [hadoop@hadoopsingle~]$ source ~/.bashrc # 環境変数の設定の適用
8.Hadoopパッケージの展開
コマンドを実行し、hadoopパッケージを展開します。展開後、hadoopディレクトリが作成された事を確認します。
[hadoop@hadoopsingle ~]$ tar -zxvf hadoop-3.1.3.tar.gz [hadoop@hadoopsingle ~]$ ls -l total 330156 drwxr-xr-x 9 hadoop hadoop 149 Sep 12 2019 hadoop-3.1.3 -rw-r--r-- 1 hadoop hadoop 338075860 Jun 14 19:16 hadoop-3.1.3.tar.gz [hadoop@hadoopsingle ~]$
9.環境変数設定スクリプトの編集
hadoopの環境変数設定ファイルを編集します。
JAVA_HOMEの部分にjavaのPathを設定します。
[hadoop@hadoopsingle~]$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64/jre [hadoop@hadoopsingle~]$
10.設定ファイルの編集
以下のパスに移動します。また以下の4つのxmlファイルの編集を行います。
[hadoop@hadoopsingle~]$ cd $HADOOP_HOME/etc/hadoop
core-site.xmlの編集
以下の様に編集を行います。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopsingle:9000</value>
</property>
</configuration>
hdfs-site.xmlの編集
以下の様に編集を行います。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xmlの編集
以下の様に編集を行います。
<configuration>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*,$HADOOP_MAPRED_HOME/share/hadoop/common/*,$HADOOP_MAPRED_HOME/share/hadoop/common/lib/*,$HADOOP_MAPRED_HOME/share/hadoop/yarn/*,$HADOOP_MAPRED_HOME/share/hadoop/yarn/lib/*,$HADOOP_MAPRED_HOME/share/hadoop/hdfs/*,$HADOOP_MAPRED_HOME/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
yarn-site.xmlの編集
以下の様に編集を行います。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
11.namenodeのフォーマット
以下のコマンドを実行し、namenodeをフォーマットします。
[hadoop@hadoopsingle jvm]$ hdfs namenode -format WARNING: /home/hadoop/hadoop-3.1.3/logs does not exist. Creating. 2020-06-14 19:58:30,259 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoopsingle/192.168.64.214 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.1.3 STARTUP_MSG: classpath = /home/hadoop/hadoop-3.1.3/etc/hadoop:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/accessors-smart-1.2.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/animal-sniffer-annotations-1.17.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/asm-5.0.4.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/audience-annotations-0.5.0.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/avro-1.7.7.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/checker-qual-2.5.2.jar:/home/hadoop/hadoop-3.1.3/share/hadoop/common/lib/commons-beanutils-1.9.3.jar:/home/hadoop/hadoop-3.1.3 --------------省略------------------------
12.Hadoop デーモンの起動
のコマンドを実行し、hadoopデーモンをそれぞれ起動します。
[hadoop@hadoopsingle ~]$ start-dfs.sh Starting namenodes on [hadoopsingle] Starting datanodes Starting secondary namenodes [hadoopsingle] [hadoop@hadoopsingle ~]$ [hadoop@hadoopsingle ~]$ jps #hadoopプロセスの確認 1924 DataNode 2164 SecondaryNameNode 1788 NameNode 2476 Jps [hadoop@hadoopsingle logs]$ start-yarn.sh Starting resourcemanager Starting nodemanagers [hadoop@hadoopsingle logs]$ jps 13648 NodeManager 1924 DataNode 2164 SecondaryNameNode 13509 ResourceManager 1788 NameNode 13998 Jps [hadoop@hadoopsingle logs]$
以下のコマンドを実行して HDFSの状態を確認してみます。
[hadoop@hadoopsingle ~]$ hdfs dfsadmin -report
2020-06-15 11:28:44,663 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 27899465728 (25.98 GB)
Present Capacity: 24664973312 (22.97 GB)
DFS Remaining: 24664969216 (22.97 GB)
DFS Used: 4096 (4 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1): #生存datanodeが(1)なので動いているようです。
Name: 192.168.64.214:9866 (hadoopsingle)
Hostname: hadoopsingle
Decommission Status : Normal
Configured Capacity: 27899465728 (25.98 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 3234492416 (3.01 GB)
DFS Remaining: 24664969216 (22.97 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.41%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Jun 15 11:28:43 JST 2020
Last Block Report: Mon Jun 15 11:23:52 JST 2020
Num of Blocks: 0
[hadoop@hadoopsingle ~]$
以下のURLにアクセスしName node情報をweb上で確認します。
http://localhost:9870/

以下にアクセスしてResource Managerのステータスをweb上で確認します。
http://localhost:8088/

13.動作テスト
今回は以下のコマンドでmapreduceを使用して円周率を計算するサンプルプログラムを実行してみます。
[hadoop@hadoopsingle ~]$ /home/hadoop/hadoop-3.1.3/bin/hadoop jar /home/hadoop/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi 10 10000
Number of Maps = 10
Samples per Map = 10000
2020-06-15 12:25:31,139 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Wrote input for Map #0
2020-06-15 12:25:31,318 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Wrote input for Map #1
2020-06-15 12:25:31,339 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Wrote input for Map #2
2020-06-15 12:25:31,355 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-06-15 12:25:33,654 INFO mapred.LocalJobRunner: Finishing task: attempt_local2133126262_0001_r_000000_0
2020-06-15 12:25:33,656 INFO mapred.LocalJobRunner: reduce task executor complete.
2020-06-15 12:25:34,338 INFO mapreduce.Job: map 100% reduce 100%
---------------------------------------- 一部省略 ----------------------------------------
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 2.87 seconds
Estimated value of Pi is 3.14120000000000000000 #実行結果
[hadoop@hadoopsingle ~]$
計算できているようです。
14.Oracle Cloudとの比較
以前の記事でOracle Cloud上に構築した、「Big Data Cluster Computing Service Edition」との簡単な比較を行っていきます。
環境
| 比較項目 | Big Data Cluster Computing Service Edition | 今回構築したローカル環境 |
|---|---|---|
| OS | Oracle Linux 6 | Cent OS7 |
| CPU | 2 | 2 |
| Memory | 30GB | 2GB |
| Storage | 249GB | 30GB |
| Hadoop version | 2.7.1 | 3.1.3 |
| Java version | 1.8.0_221 | 1.8.0_252 |
BDCCSE(*1)だとHadoopのバージョンやJavaのバージョンの選択に制限があるようです。
オンプレミス上での構成の方が最新のソフトウェアや環境にあった選択ができるようです。
しかし、クラウドならではの高速に設定済みの環境を用意できる事、また今回行った設定等も一切行う必要が無いため、短い期間でデータ分析基盤が必要という方には重宝するサービスかと思います。
BDCCSEだと、膨大な巨大データに対して分散処理を行うオープンソースのフレームワーク「spark」や、Hadoop上で稼働するDWH兼分析パッケージ「Hive」等のミドルウェアをも自動で構築/設定される事が魅力かと思います。
時代の変化と共に毎年世界のデータ量は増え続けています。
従来通りの考えや決定方法では難しい部分がでてきました。
変化に取り残されない為にも、こういった技術を積極的に取り入れていくべきと思いました。
(*1) Big Data Cluster Computing Service Editionの略
15.最後に
今回の検証では、Apache HadoopをSingle nodeで実際に構築し、Oracle Cloud上で構築した際の環境と簡単な比較を行ってみました。
機会があれば、もっと詳細な設定を行いnode数を増やした完全分散処理モードでの検証も行いたいと思います。
※本記事の設定内容は検証目的の為、全ての環境で完全な動作を保証するものではありません

