機密データを安全に活用するデータマスキングとは|「Insight Masking」検証レポート

個人情報や機密データを安全に取り扱うことは、今日のビジネスにおいて重要な課題の一つです。
開発・テスト環境で本番データを使用する際には、個人情報保護法などの規制に準拠しながら、データの有用性を保つ必要があります。
本記事では、データマスキングツール「Insight Masking」を用いた検証結果をもとに、その機能と実用性について詳しくご紹介します。
目次
1. Insight Maskingとは
Insight Maskingは、データベースやCSVファイルに含まれる個人情報や機密情報を自動的に検出し、マスキング(匿名化)するソリューションです。
AI技術を活用した自動検出機能により、マスキング対象の特定や設定作業の効率化を支援します。
また、Insight MaskingにはPDF文書内の個人情報を墨消し(黒塗り)する機能も備わっていますが、本記事ではCSVファイルのマスキングに焦点を当てて検証を実施しました。
2. Insight Maskingの主な特徴
AIによる自動検出
列名ではなく実際のデータ値を分析し、個人情報を自動判定します。
豊富なマスキング方式
テキスト、数値、日付、辞書など多様なマスキング方法に対応しています。
複数のデータソース対応
Oracle、SQL Server、MySQL、PostgreSQL、CSVファイルなどに対応しています。
柔軟な実行方式
手動実行、スケジュール実行、CLI実行に対応しています。
3. AIラベル解析機能の検証
Insight Maskingの最大の特徴であるAIラベル解析機能でどこまで自動判定できるかを検証しました。
検証方法
- データベースまたはCSVファイルをInsight Maskingに登録
- AIラベル解析を実行(サンプリング数1000件)
- 自動判定されたマスキング設定を確認
結果
- 氏名、メールアドレス、電話番号、住所などの個人情報を高精度で自動検出
- 列名に依存せず、実際のデータ値から判定するため、列名が不明瞭な場合でも正確に検出
- マイナンバー、クレジットカード番号、健康保険証番号などの特殊な個人情報も検出可能
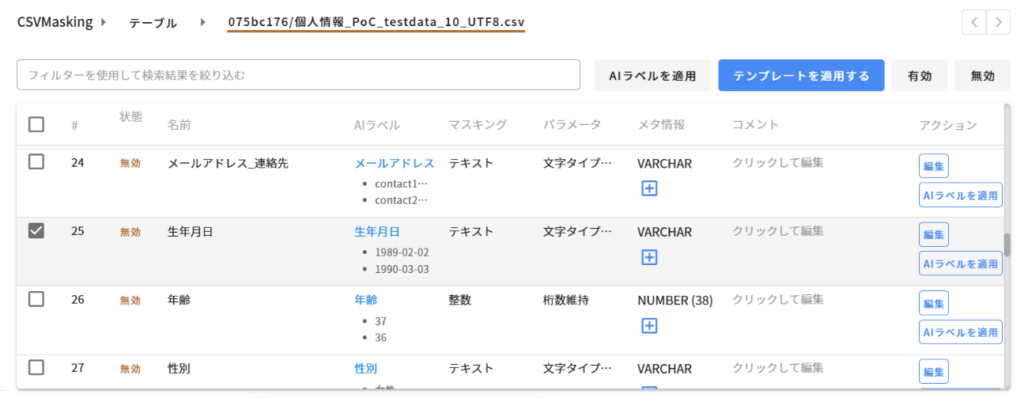
AIラベル解析により、手動でマスキング対象を設定する手間が大幅に削減され、設定ミスのリスクも低減できることが確認できました。
4. マスキング方式の検証
Insight Maskingが提供するさまざまなマスキング方式を検証しました。
テキストマスキング
文字タイプを維持しながら元データとは異なる値に置き換える方式です。
例
- 元データ: ABC123
- マスク後: XYZ789(アルファベットと数字の位置関係を維持)
特徴
- 文字タイプ維持により、データの形式を保持
- カスタム文字グループの指定が可能
- 固定文字(例: *****)や固定文字列での置き換えも可能
カスタム文字のマスキング結果

固定文字のマスキング結果

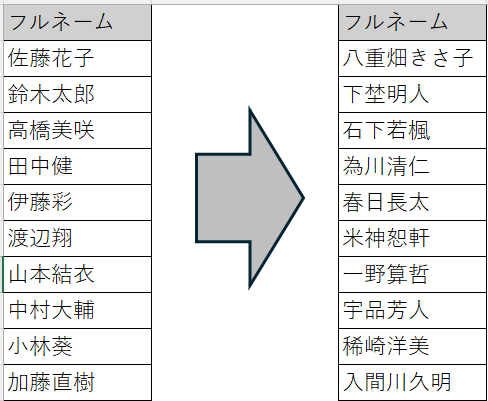
辞書マスキング
事前に用意された辞書ファイルからランダムに値を選択する方式です。
標準搭載辞書
- クレジットカード番号
- パスワード
- マイナンバー
- メールアドレス
- 住所
- 個人名
- 健康保険証番号
- 年齢
- 性別
- 旅券番号
- 汎用ID
- 法人名
- 法人番号
- 生年月日
- 運転免許証番号
- 郵便番号
- 銀行口座番号
- 電話番号
特徴
- 辞書ファイルに登録された値を使って、実データに近い置換値を生成できる
- 氏名、住所、メールアドレスなど、項目の意味に応じたマスキングに向いている
- 独自の辞書ファイルを用意することで、業務に合わせた置換値を利用できる
メールアドレスのマスキング結果
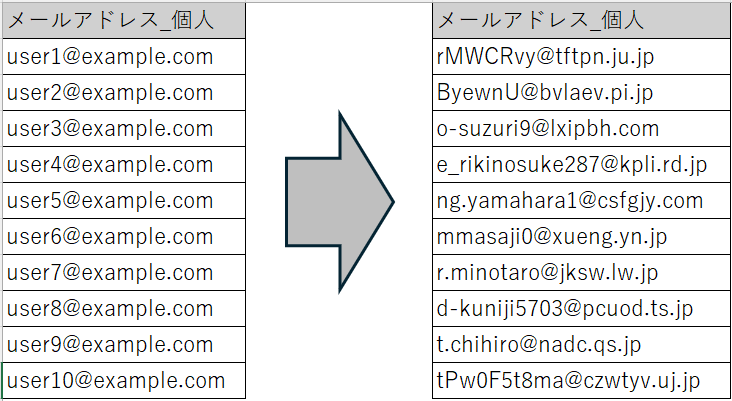
住所のマスキング結果
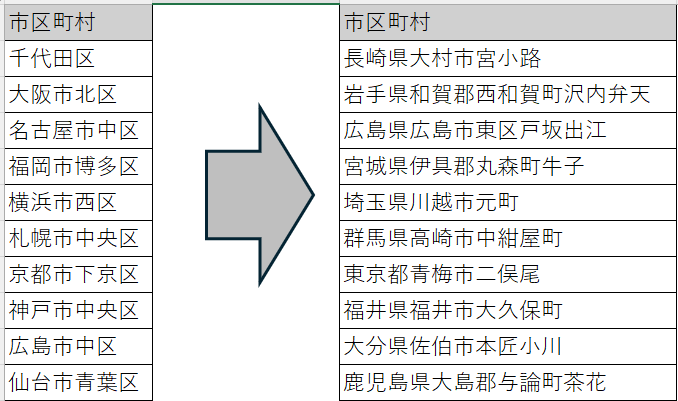
個人名(フルネーム)のマスキング結果
携帯電話番号のマスキング結果

辞書マスキングにより、元データの意味合いに近く、テスト用途で扱いやすいテストデータを生成できることを確認しました。
独自の辞書ファイルをアップロードして使用することも可能です。
分割テキストマスキング
文字列を指定した文字数で分割し、部分ごとに異なるマスキング設定を適用する方式です。
例
- 元データ: ABCDEFGHI
- 設定: 先頭3文字は固定文字(*)、次の4文字は元の文字タイプ維持、残りは未指定
- マスク後: ***WXYZGHI
マスキング結果
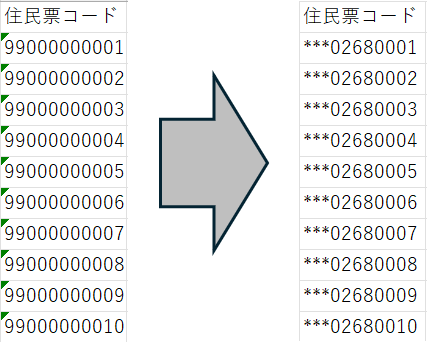
この方式は、特定のフォーマットを持つデータ(例: 会員番号や住民票コードの一部のみマスキング等)に有効です。
数値マスキング
整数や小数のマスキングでは、以下の方式を選択できます。
- 同じ桁数内でランダム化: 元の桁数を維持
- 範囲指定: 最小値~最大値の範囲内でランダムに生成
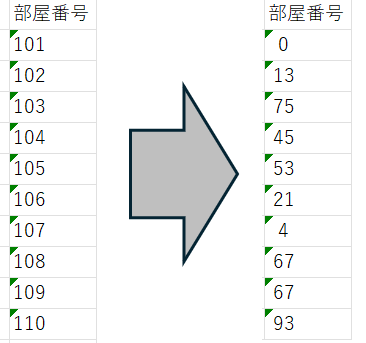
注意点: 数値項目で桁数に満たない場合の文字埋めがデフォルトで「空白で埋める」になっているため、出力形式に応じて事前に設定を確認する必要があります。
5. テンプレート機能の検証
複数の列に同じマスキング設定を適用したい場合、テンプレート機能が有効です。
使用方法
1. マスキング設定をテンプレートとして保存
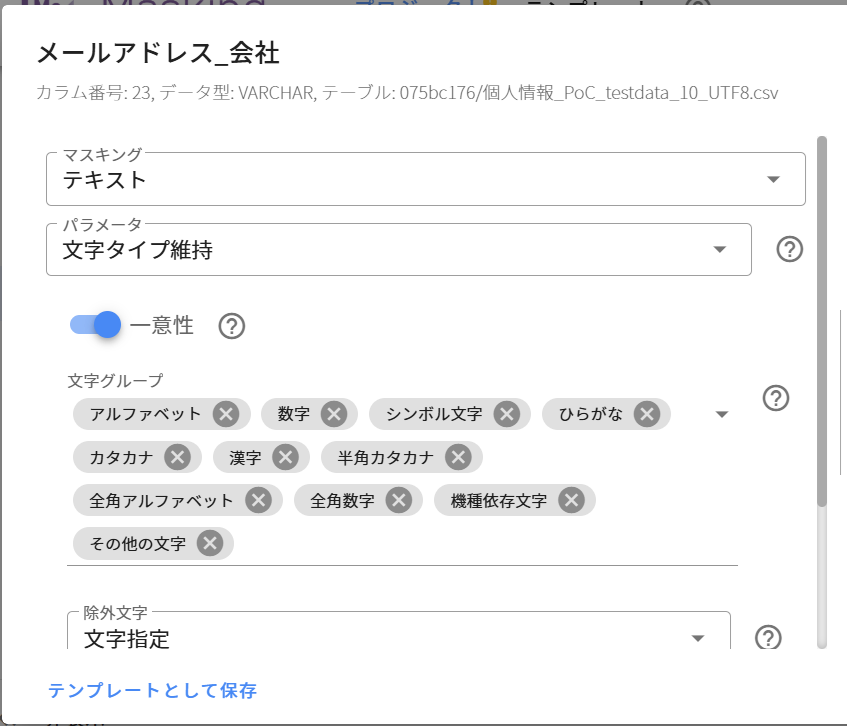
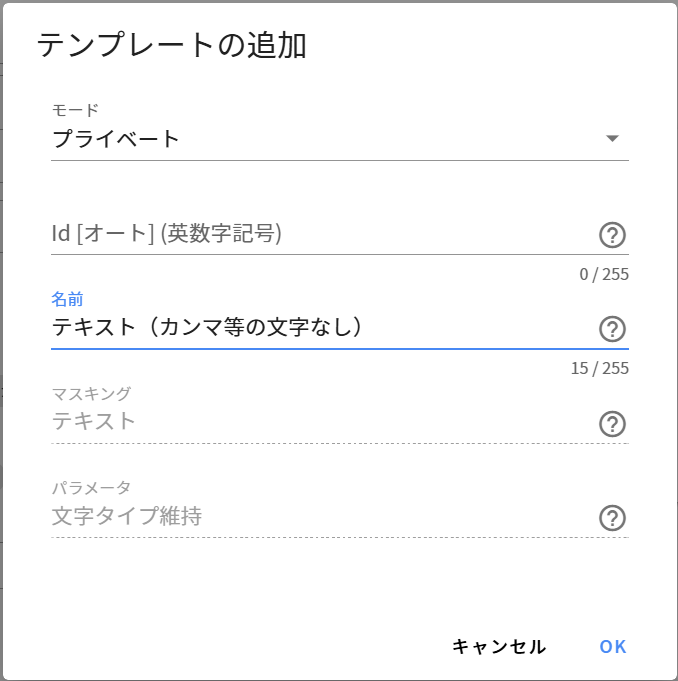
2. 対象の列を選択し、テンプレートを適用
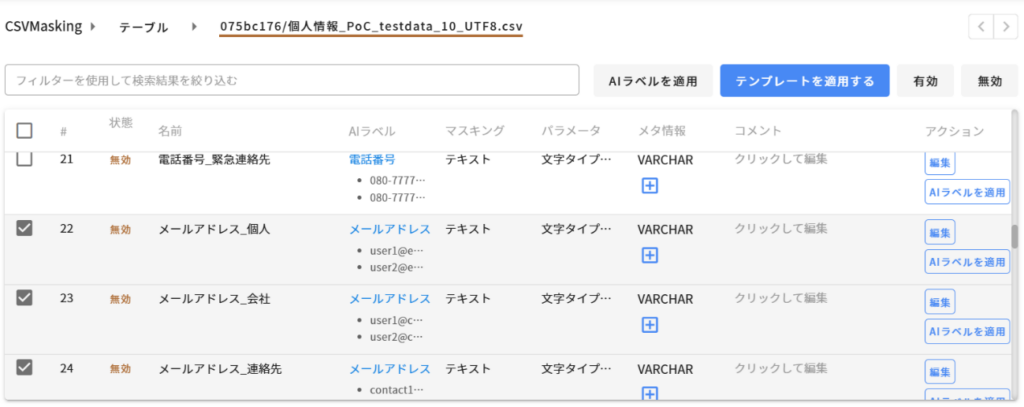
この機能により、複数の列に対して一貫したマスキング設定を効率的に適用できることを確認しました。
6. 実行方式の検証
Insight Maskingは3つの実行方式をサポートしています。
手動実行(GUI)
ブラウザ画面から「マスキング実行」ボタンをクリックして実行します。
対象: プロジェクト内で「有効」に設定されたすべてのデータソース
用途: 初回実行や設定確認時に最適
スケジュール実行
定期的な実行をスケジュール設定できます。
設定可能な間隔
- 毎日
- 毎週(曜日指定)
- 毎月(日付指定)
制限事項:
- 実行時間は5分単位で指定
- 休日・営業日設定は不可
- リトライ設定は不可
- 複数曜日を指定する場合は、設定を複数作成する必要がある
注意: スケジュールの一時停止機能がないため、実行を止めたい場合は削除するか、次回実行までの間隔を延ばす必要があります。
CLI実行
Linuxサーバー上でシェルスクリプトを実行してマスキング処理を起動できます。
実行例
/home/idminsight/idm-gui/storage/app/bin/batch-cli.sh <プロジェクトID>
メリット:
- 外部システムからの連携が容易
- cronなどの既存スケジューラーと統合可能
- 複数プロジェクトの一括実行が可能
CLI実行のログもWeb画面から確認できることを確認しました。
7. 大量データの処理性能の検証
実際の業務を想定し、大量データのマスキング性能を検証しました。
検証1:約200万レコード
| ファイル形式 | CSV |
|---|---|
| レコード数 | 2,065,535件 |
| 項目数 | 22項目 |
| マスキング項目数 | 22項目(全項目) |
| ファイルサイズ(マスキング前) | 486MB |
| 処理時間 | 10分36秒 |
| ファイルサイズ(マスキング後) | 507MB |
検証2:約400万レコード
| ファイル形式 | CSV |
|---|---|
| レコード数 | 4,065,535件 |
| 項目数 | 22項目 |
| マスキング項目数 | 22項目(全項目) |
| ファイルサイズ(マスキング前) | 957MB |
| 処理時間 | 20分42秒 |
| ファイルサイズ(マスキング後) | 998MB |
結果考察:
- レコード数に対してほぼ線形の処理時間
- 今回の条件では1分あたり約20万レコードの処理が可能
- 大量データでも安定した処理性能を確認
8. 外部ストレージ連携の検証
Insight MaskingはNFS接続により、外部サーバーのファイルを直接取り扱うことができます。
検証したストレージ
| ストレージの種類 | Insight Maskingから接続 | 備考 |
|---|---|---|
| Windows NFS共有 | ✓ 可能 | オンプレミス環境で有効 |
| Azure Files (NFS) | ✓ 可能 | Azure環境での利用に最適 |
| Azure Blob (NFS) | ✗ 不可 |
NFS接続により、ファイルのアップロード/ダウンロードの手間を省き、効率的なデータ処理が可能になることを確認しました。
注: Azure Blob (NFS)との直接連携には対応していませんが、カスタムAPIを実装することで連携が可能です。詳細はこちらの記事で紹介しています。
9. まとめ
Insight Maskingの検証を通じて、以下の点を確認できました。
優れている点
- AIによる自動検出機能により、設定工数を大幅に削減
- 豊富なマスキング方式で、さまざまなデータ形式に対応
- 大量データでも安定した処理性能
- 柔軟な実行方式(手動、スケジュール、CLI)
- 日本の個人情報(マイナンバー、健康保険証番号など)に標準対応し、自治体・医療・金融など機密データを扱う現場でそのまま活用しやすい
考慮すべき点
- スケジュール実行の柔軟性に制限がある
- 自動リトライ機能がない(CLI実行とCRONなど外部スケジューラーの組み合わせで代替可能)
総評
Insight Maskingは個人情報保護とデータ活用を両立させる有効なソリューションであることを確認しました。
特にAIラベル解析機能は、導入時の設定負荷を大幅に軽減し、迅速なデータマスキング環境の構築を可能にします。
ただし、マスキングはあくまで「機密データを安全に使う」ための第一歩です。
安全化したデータを、分析・可視化やRAG・生成AIといった「活用」につなげて初めて、データは“使える資産”になります。
10. おわりに
システムエグゼでは、Insight Maskingを提供するインサイトテクノロジー社と協力し、機密データの安全な活用を支援する「機密データ活用基盤構築サービス for Microsoft Fabric」を提供しています。
本サービスは、Insight Maskingによる機密情報の安全化とMicrosoft Fabricの統合基盤を組み合わせ、個人情報や営業秘密を含むデータの分析・可視化から生成AI活用までを一気通貫で支援します。
個人情報や営業秘密を含むデータの活用にお悩みの方、開発・テスト環境での安全なデータ利用をご検討の方は、ぜひお気軽にご相談ください。
サービスの詳細は下記資料でご紹介しています。
▽「機密データ活用基盤構築サービス for Microsoft Fabric」の詳細・資料請求はこちら
https://www.system-exe.co.jp/document-request/fabric_masking/


