【Amazon Forecastで時系列予測】①データセットの準備

Amazon Forecastは、Amazon.comの機械学習予測技術に基づいて、統計アルゴリズムと機械学習アルゴリズムを使用し、高い精度の時系列予測を提供する完全マネージド型サービスです。
全5回のコラムを通して、Amazon Forecastの概要、そして時系列予測を実際にAmazon Forecastでどのように実施していくのかを操作手順ベースでご紹介していきます。
前回の記事では、Amazon Forecastの概要や時系列予測についてご説明しました。
第2回となる今回は、予測を行うためのデータセット群の準備に関する手順をご紹介します。
目次
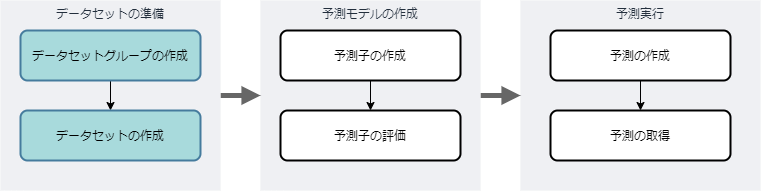
1. はじめに
データセットグループの作成とデータセットの作成を行い、予測を行うためのデータセット群の準備をします。
※各データセットはデータセットグループ単位でまとめることができます。
2. データの準備
Amazon Forecastの操作に入る前に、時系列予測に使用する各種データを準備し、Amazon S3バケットに格納しておきます。
Amazon S3に関する手順はここでは割愛します。
下記のAmazon S3の公式ドキュメントを別途参照下さい。
・Amazon S3公式サイト
データは、下記のData.worldとKaggleの公開データをもとに作成しています。
- COVID-19 Time Series Data
- Country Mapping – ISO, Continent, Region
- geo locations of countries ※現在は公開されていません
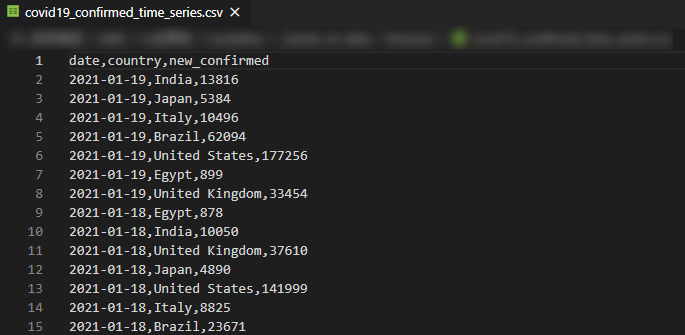
①TARGET_TIME_SERIES(ターゲット時系列)
予測したいデータに関する過去の時系列データとして、COVID-19の新規感染者数の時系列データを用意しました。
(データ期間:2020/01/22~2021/01/19)
データ列項目
- date:年月日
- country:国
- target_value:日別の新規感染者数
※画像をクリックすると新しいタブで開きます。
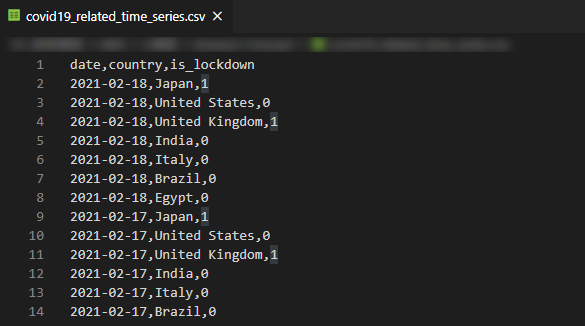
②RELATED_TIME_SERIES(関連する時系列)
予測したいデータに関連する補完的な時系列データとして、各国のロックダウンや緊急事態宣言の有無を示す時系列データを用意しました。
緊急レベルは一切考慮せず、何らかの規制が政府によって発令されている期間は「1」のフラグをたてる形でデータを作成しました。
(データ期間:2020/01/22~2021/02/18 TARGET_TIME_SERIESの期間+予測したい期間1ヶ月)
データ列項目
- date:年月日
- country:国
- is_lockdown:ロックダウン/規制の有無
※画像をクリックすると新しいタブで開きます。
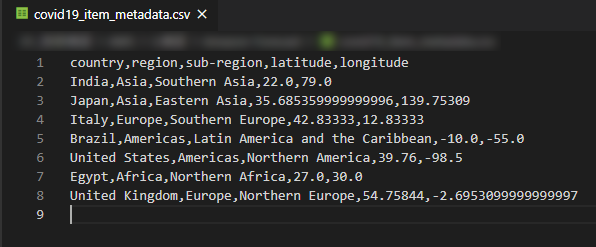
③ITEM_METADATA(項目メタデータ)
実際に予測する時系列データ以外のメタデータとして、国の地域に関するデータを用意しました。
データ列項目
- country:国
- region:大州
- sub-region:小地域
- latitude:緯度
- logngitude:経度
※画像をクリックすると新しいタブで開きます。
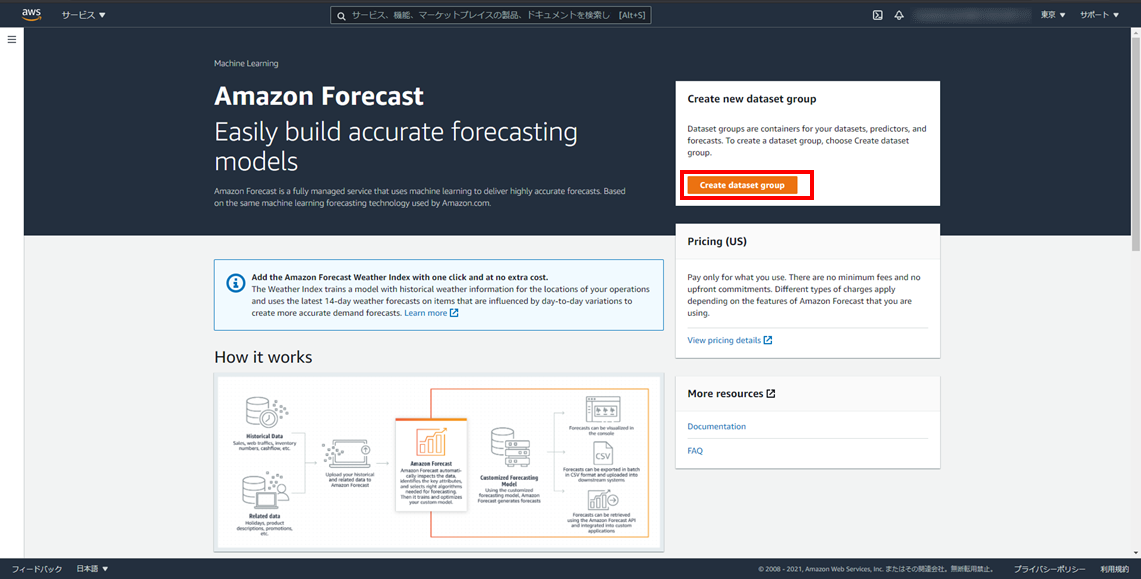
3. データセットグループの作成
ここからAmazon Forecastの操作になります。
AWSにログインして、Amazon Forecastを開きます。
Amazon Forecastのトップページ > Create dataset group
※画像をクリックすると新しいタブで開きます。
データセットグループ名とドメインを入力
※画像をクリックすると新しいタブで開きます。
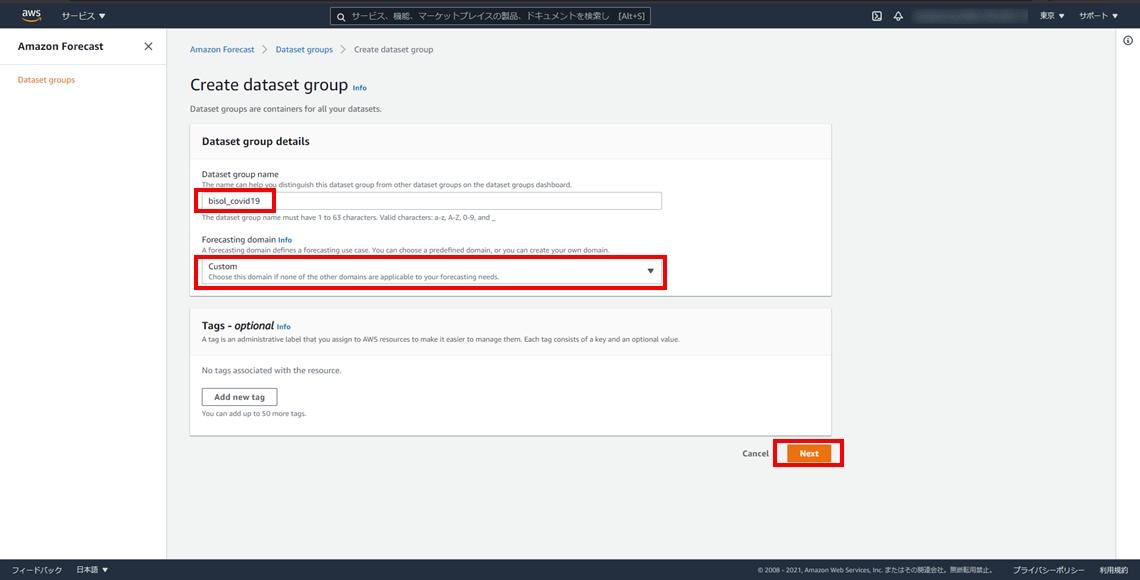
- データセットグループ名:bisol_covid19
- データセットドメイン:Custom
Amazon Forecastでは、扱うデータに応じてより良い予測ができるように各種ドメインが用意されています。
用意されているドメインにはまらない場合は、CUSTOMを選択します。
| ドメイン | 説明 |
|---|---|
| RETAIL | 小売りの需要予測 |
| INVENTORY_PLANNING | サプライチェーンと在庫の計画 |
| EC2 CAPACITY | Amazon EC2キャパシティの予測 |
| WORK_FORCE | 従業員の計画 |
| WEB_TRAFFIC | 今後のウェブトラフィックの見積 |
| METRICS | 収益およびキャッシュフローなどの予測メトリクス |
| CUSTOM | その他すべての時系列予測のタイプ |
4. データセットの作成
Amazon S3に格納した各CSVファイルのデータをスキーマ経由でAmazon Forecastに読み込みます。
①TARGET_TIME_SERIES(ターゲット時系列)
※画像をクリックすると新しいタブで開きます。
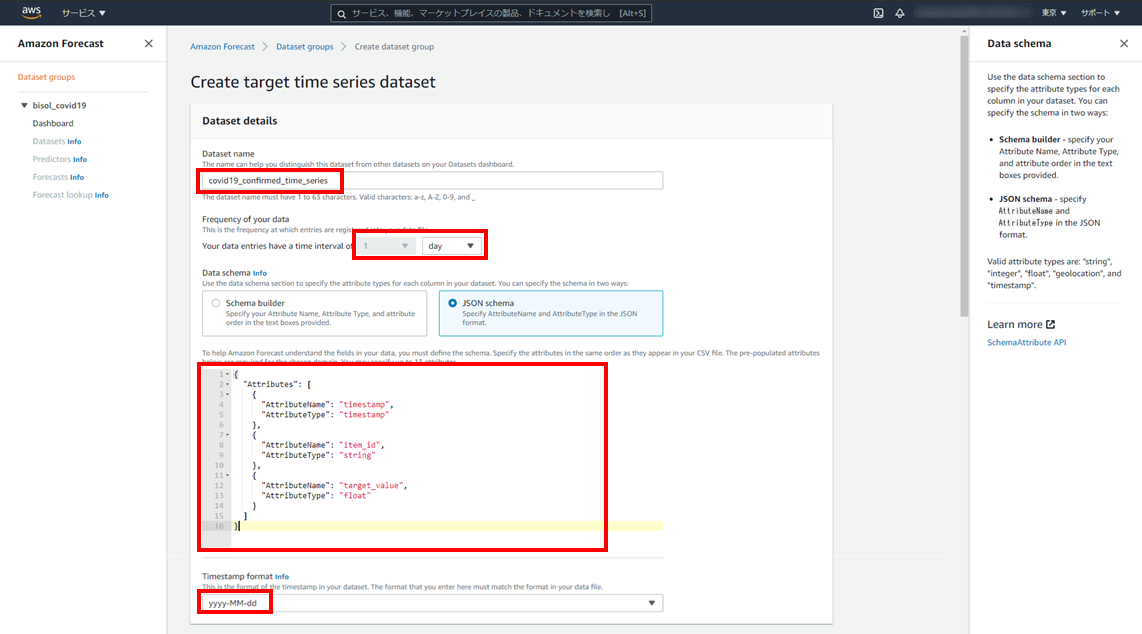
- データセット名:covid19_confirmed_time_series
- データ頻度:1day
- スキーマ定義:データタイプと順序で、CSVファイルの列に一致するように設定
- タイムスタンプ形式:yyyy-MM-dd
ハイフンつなぎのフォーマットしか対応していないため、スラッシュ区切りの場合は事前に加工が必要です。
{
"Attributes": [
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "target_value",
"AttributeType": "float"
}
]
} これでスキーマ定義ができましたので、データをインポートします。
※画像をクリックすると新しいタブで開きます。
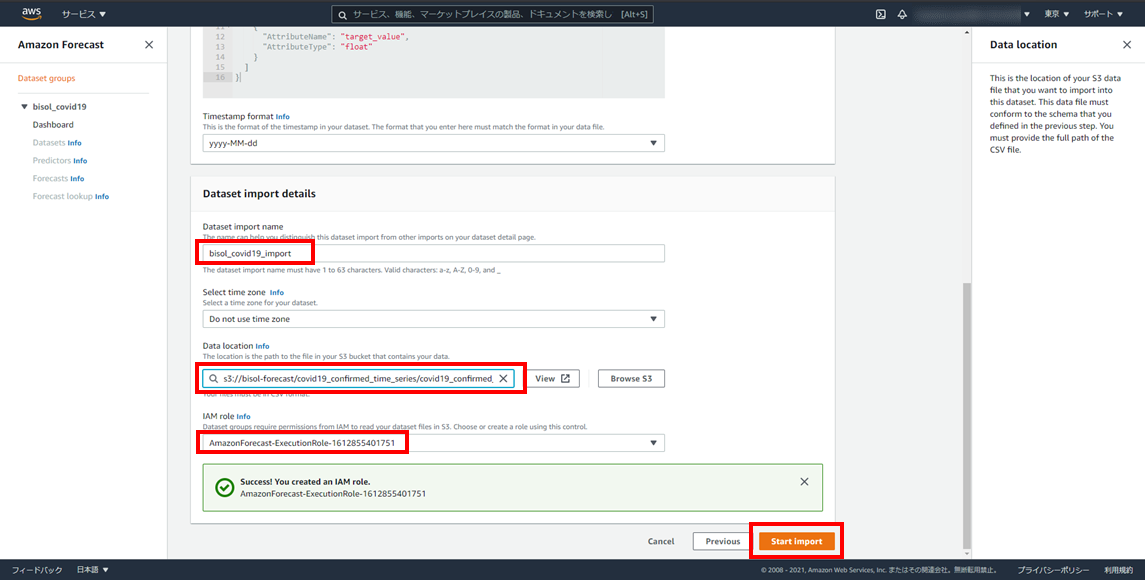
- データセットのインポートジョブ名:bisol_covid19_import
- データの場所:Amazon S3上のCSVファイルの場所を入力
- IAMロール:任意のIAMロールのAmazonリソースネーム(ARN)を入力
S3に格納したデータを読み込んでインポートするので、格納先S3バケットのRead権限のあるIAMロールを用意します。
データセットグループのダッシュボードページが表示され、ターゲット時系列データのインポートジョブのステータスが表示されます。
数分待つと、データセットのインポートが完了しステータスが「Active」に変わります。
※画像をクリックすると新しいタブで開きます。
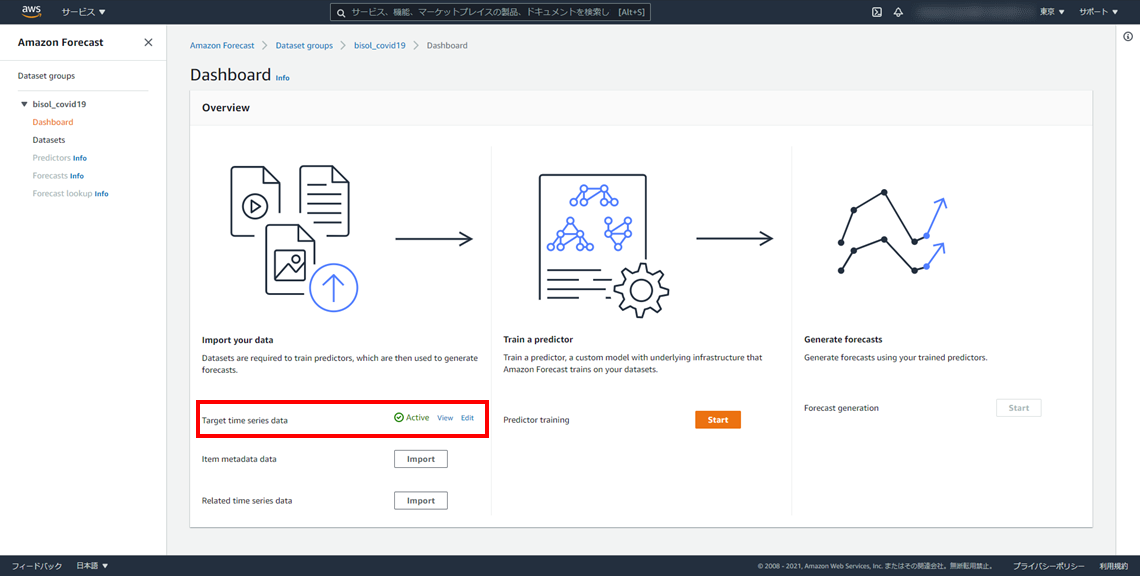
ターゲット時系列データのインポートができましたので、これで予測子の作成に進めます。
今回は、事前に準備した関連する時系列データと項目メタデータも同様にインポートしておきます。
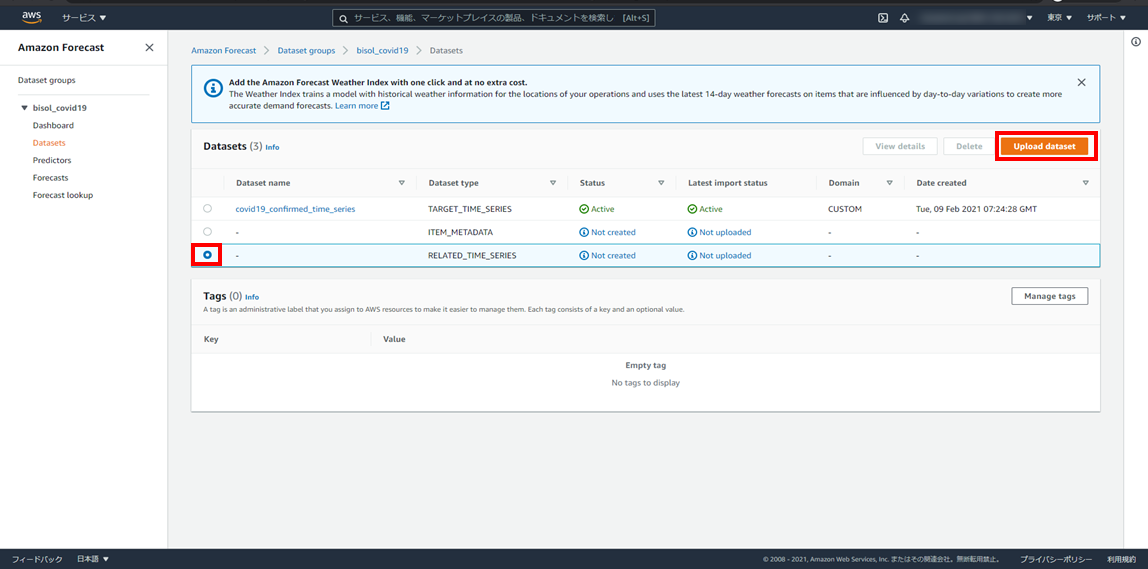
②RELATED_TIME_SERIES(関連する時系列)
RELATED_TIME_SERIES > Upload dataset
※画像をクリックすると新しいタブで開きます。
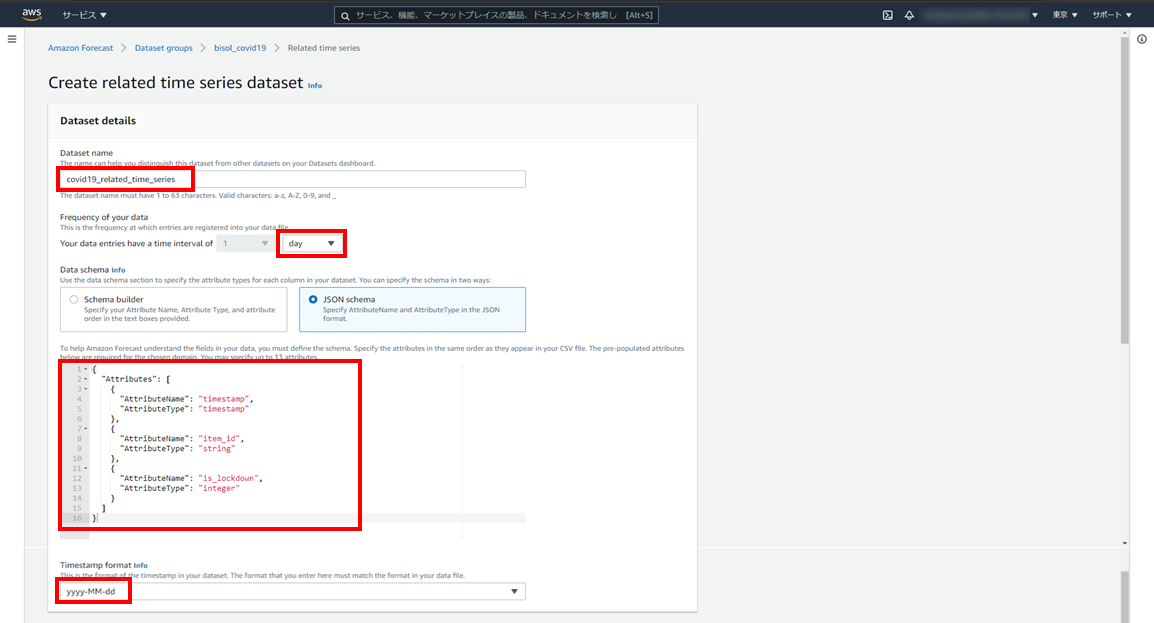
- データセット名:covid19_related_time_series
- データ頻度:1day
- スキーマ定義:データタイプと順序で、CSVファイルの列に一致するように設定
- タイムスタンプ形式:yyyy-MM-dd
ハイフンつなぎのフォーマットしか対応していないため、スラッシュ区切りの場合は事前に加工が必要です。
{
"Attributes": [
{
"AttributeName": "timestamp",
"AttributeType": "timestamp"
},
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "is_lockdown",
"AttributeType": "integer"
}
]
} ※画像をクリックすると新しいタブで開きます。
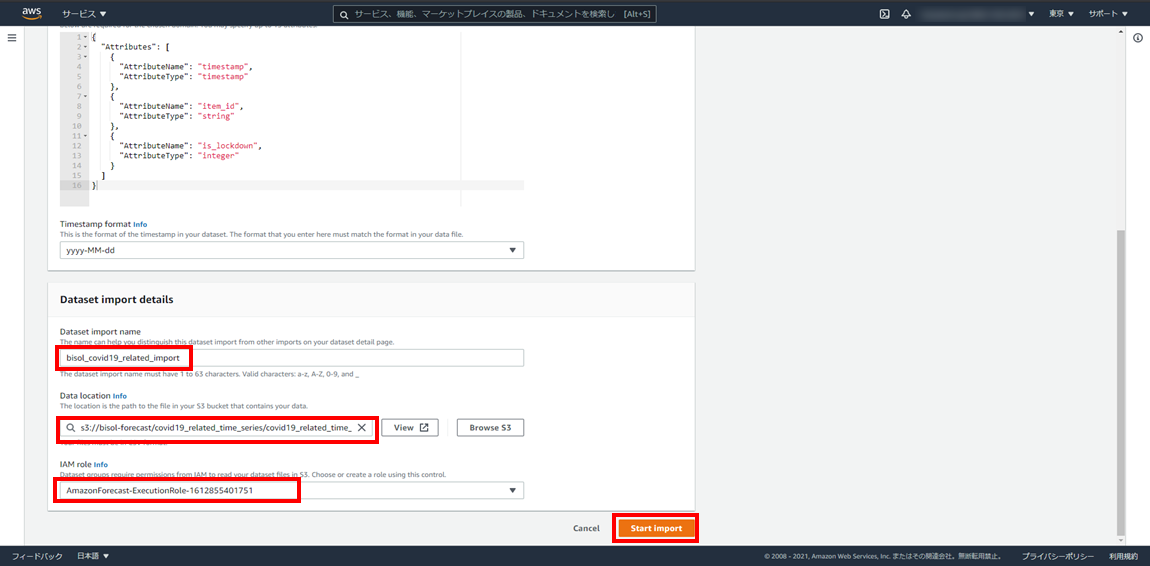
- データセットのインポートジョブ名:bisol_covid19_related_import
- データの場所:Amazon S3上のCSVファイルの場所を入力
- IAMロール:任意のIAMロールのAmazonリソースネーム(ARN)を入力
S3に格納したデータを読み込んでインポートするので、格納先S3バケットのRead権限のあるIAMロールを用意します。
数分待つと、データセットのインポートが完了しインポートジョブのステータスが「Active」に変わります。
※画像をクリックすると新しいタブで開きます。
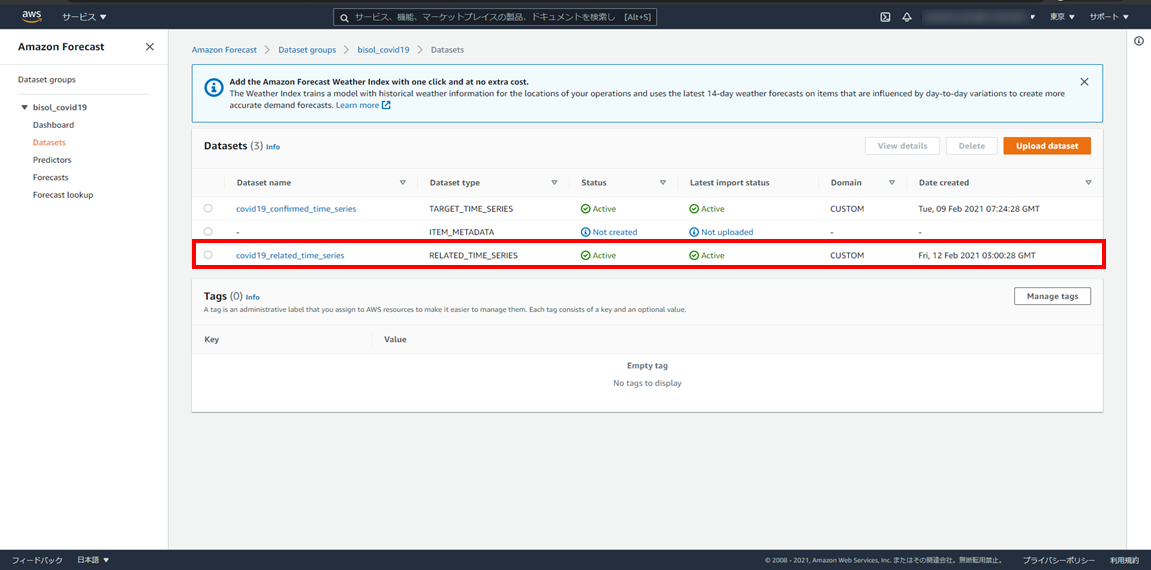
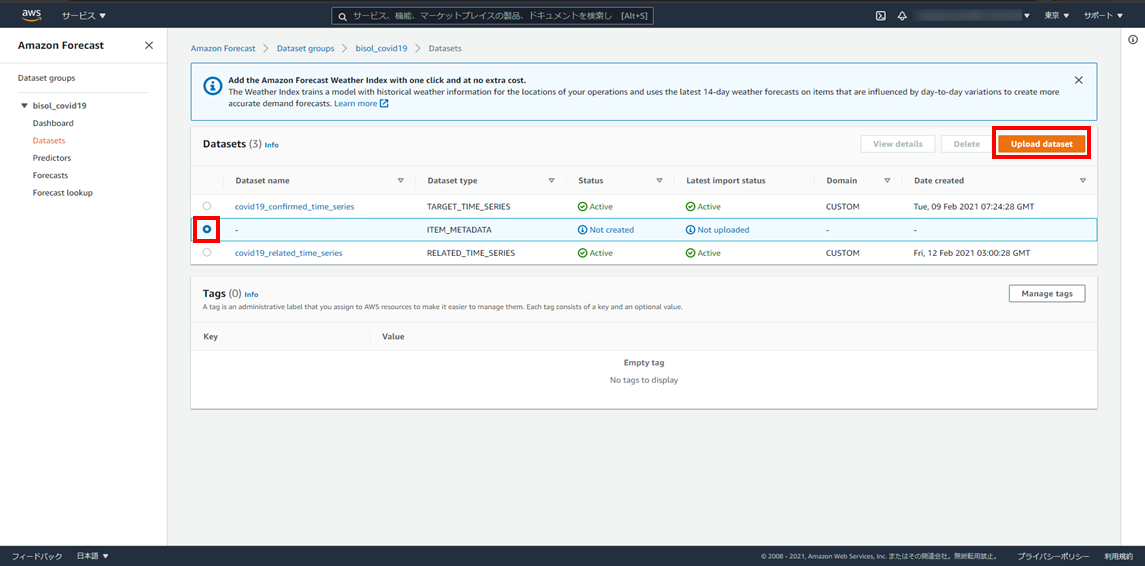
③ITEM_METADATA(項目メタデータ)
ITEM_METADATA > Upload dataset
※画像をクリックすると新しいタブで開きます。
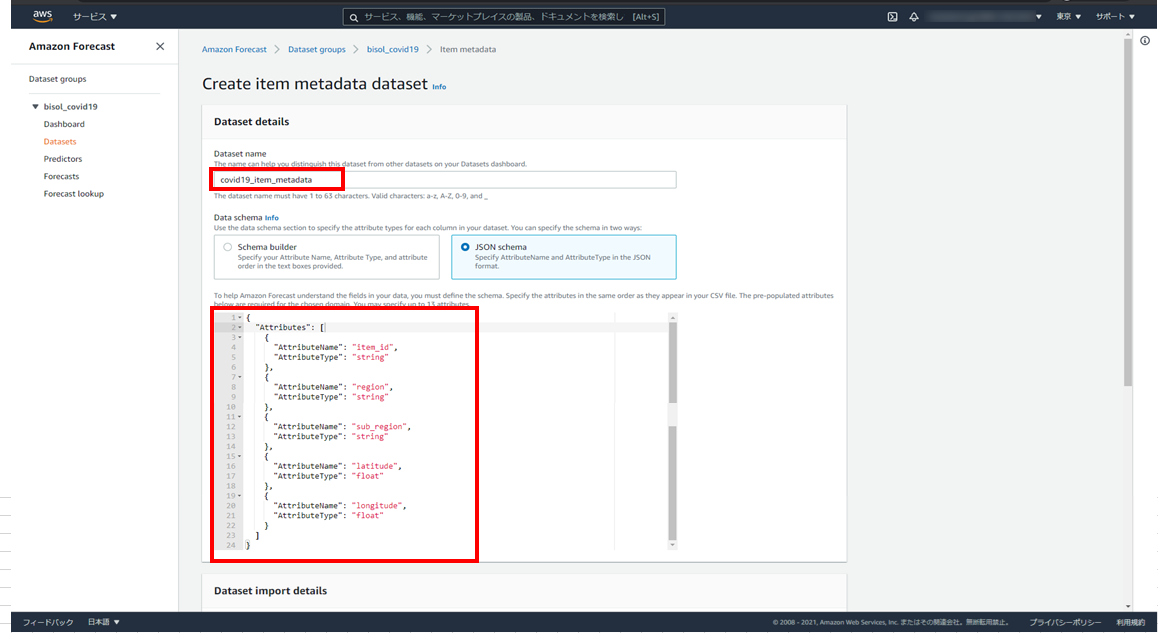
- データセット名:covid19_item_metadata
- スキーマ定義:データタイプと順序で、CSVファイルの列に一致するように設定
{
"Attributes": [
{
"AttributeName": "item_id",
"AttributeType": "string"
},
{
"AttributeName": "region",
"AttributeType": "string"
},
{
"AttributeName": "sub_region",
"AttributeType": "string"
},
{
"AttributeName": "latitude",
"AttributeType": "float"
},
{
"AttributeName": "longitude",
"AttributeType": "float"
}
]
} ※画像をクリックすると新しいタブで開きます。
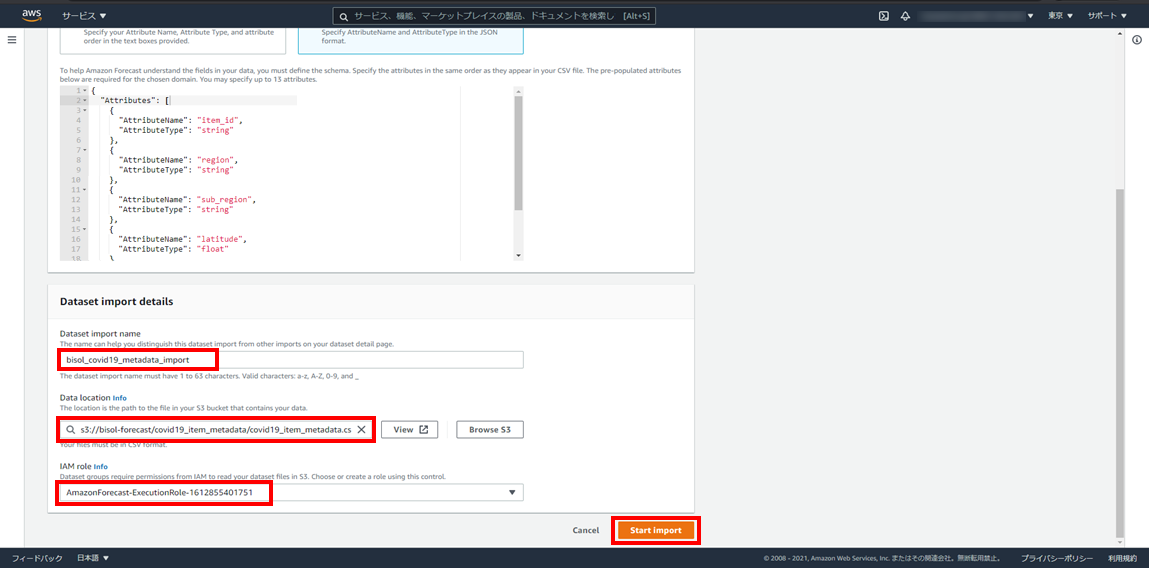
- データセットのインポートジョブ名:bisol_covid19_metadata_import
- データの場所:Amazon S3上のCSVファイルの場所を入力
- IAMロール:任意の IAM ロールの Amazon リソースネーム (ARN) を入力
S3に格納したデータを読み込んでインポートするので、格納先S3バケットのRead権限のあるIAMロールを用意します。
数分待つと、データセットがインポートが完了しインポートジョブのステータスが「Active」に変わります。
※画像をクリックすると新しいタブで開きます。
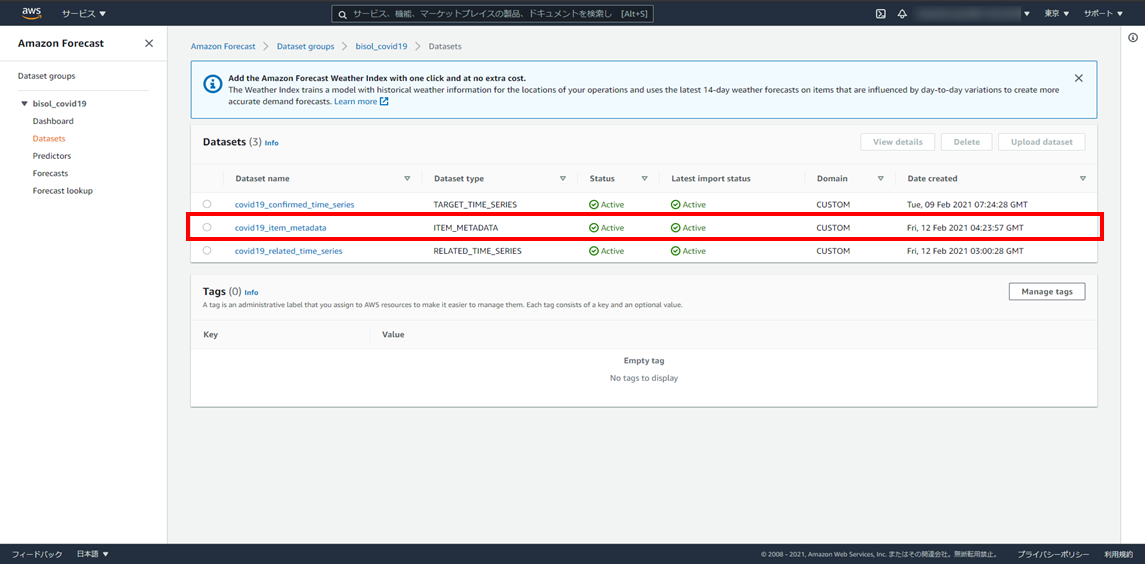
5. おわりに
これで予測を行うためのデータセット群の準備に関する作業は完了です。
次回は、これらのデータを用いて予測モデルの学習を行います。
■商標について
Amazon Web Services、および、かかる資料で使用されるその他のAWS商標は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
【Amazon Forecastで時系列予測】シリーズ コラム一覧(全5回)
第1回:Amazon Forecastとは
第3回:②予測モデルの作成(AutoML)
第4回:③予測モデルの作成(CNN-QR)
第5回:④予測実行(推論)





