CASE STUDY
Microsoft Fabric上に消費者アンケートデータ分析基盤を構築し、調査結果データの登録〜分析までを標準化
飲料・研究領域におけるデータ活用基盤構築事例
- サービス:
- 課題・ニーズ:
- 社名
- 某飲料メーカーI社
- 事業内容
- 酒類・飲料を中心とした食品メーカー

導入前の課題
- アンケート結果(Excel)と分析データが複数の形式・保管場所に分散し、データ登録や参照に手間がかかっていた。
- 過去データは別環境(SQL Server)に蓄積されており、過去データの検索・活用を含めた一元管理が難しかった。
- Rスクリプトを用いた分析はあるものの、データ抽出〜分析〜出力までの運用が属人化しやすく、標準化が課題だった。
- 部署/製品種別ごとの参照制御や、監査・運用(バックアップ、ログ管理)を含む統制を整えたい。
導入効果
- Microsoft Fabric(OneLake/Lakehouse/Data Factory/Notebook)を基盤として、データ蓄積と処理フローを統一。登録プロセスを標準化することで、一連業務の省力化を実現した。
- 過去データの抽出・ロード・重複排除・確認までの移行プロセスを設計し、調査IDをキーにしたデータ紐付け・検索に対応。過去のデータを参照できる基盤となった。
- Notebook上でデータ抽出〜R分析〜結果出力(Excel)までを一括実行できる形に整理。分析業務の再現性向上が実現し、担当間でばらつきのない運用が可能となった。
- Microsoft Entra IDを活用し、ロールベースのアクセス制御を実現。部署・製品種別ごとの参照範囲制限を徹底できるようになった。加えて、自動バックアップ、ログ管理、監視などの運用要件をクラウド前提で整備し、継続運用の負担を軽減した。
顧客の課題
大手食品・飲料メーカーのI社では、消費者の嗜好アンケート調査を行っていますが、その調査結果や分析データの管理・運用に以下のような課題を抱えていました。
- 消費者の嗜好アンケート結果(Excel)と分析データが複数の形式・保管場所に分散し、データ登録や参照に手間がかかっていた。
- 過去データは別環境(SQL Server)に蓄積されており、過去データの検索・活用を含めた一元管理が難しかった。
- Rスクリプトを用いた分析はあるものの、データ抽出〜分析〜出力までの運用が属人化しやすく、標準化が課題だった。
- 部署/製品種別ごとの参照制御や、監査・運用(バックアップ、ログ管理)を含む統制を整えたい。
課題の解決方法
本プロジェクトでは、嗜好調査関連データ(調査結果・分析データ)を「蓄積し、必要な形で取り出して分析・活用できる」状態にすることを目的に、Microsoft Fabric上で嗜好分析データ基盤を構築しました。
入力画面を新規に開発するのではなく、現場で扱い慣れたExcelを中心に据え、調査情報ファイルと調査結果データをOneLakeに格納する運用に統一。登録時の入力チェック(禁止文字、必須項目、プルダウン列への直接入力禁止など)もルール化し、データ品質を担保しながら取り込みを実行できるように整理しました。
また、過去データについては、既存SQL Serverからの移行を想定し、抽出・ロード・重複排除・確認の流れを設計。調査IDをキーに、調査結果と分析データを紐付けて参照できる方針とし、過去データの検索(調査ID/製品情報ベース)にも対応できる構成としました。
分析処理はNotebook上でRスクリプトを実行し、必要な分析結果をExcel形式でOneLakeへ出力。後続の可視化・活用として複数のBIツールへスムーズに繋げられる形を目指しました。
構築後の効果
- 標準化されていなかった調査情報の登録〜分析までの一連の運用が、「OneLakeへの格納・取り込み・Notebook実行」として定型化され、手順のばらつきや属人化を抑制。各担当者が同じ流れで運用できるようになり、業務効率が向上した。
- 部署/製品種別ごとの閲覧範囲を制御しつつ、必要なメンバーが必要なデータにアクセスできる環境を整備し、ガバナンス強化と利便性向上を実現した。
- 自動バックアップやログ管理などの非機能要件を前提にした運用設計により、継続運用に対する安心感が向上した。
- データ量増加・利用者増(将来的に最大100名想定)を見据えた拡張性にも配慮し、今後の業務拡大や他システムとの連携など、新たなデータ活用ニーズ・分析要件が生じた際にも柔軟に対応できる基盤となった。
今後の展望
- DBからの抽出を起点に、Pythonベースの分析・簡易可視化や、MLモデルの実装・運用まで拡張していく構想。
- 調査データのさらなる活用(切り口別の分析拡充、レポートの高度化)に向けたNotebook整備とスキルトランスファーの継続。
- (将来)周辺DBとの連携や、分析対象の拡張に向けたデータ設計の見直し。
システム概要図
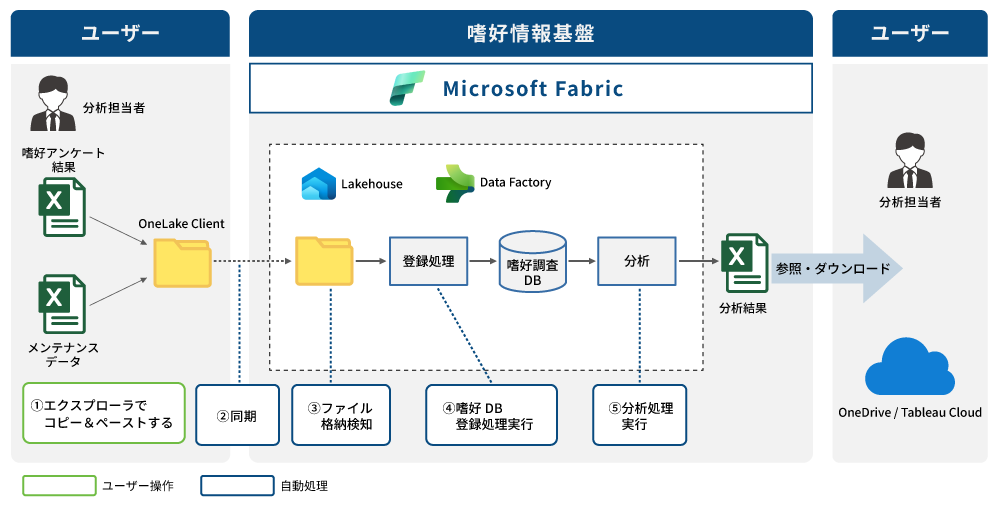
システム構成
| データ蓄積 | Microsoft Fabric(OneLake/Lakehouse) |
|---|---|
| データ連携・取り込み | Dataflow/Data Factory(運用フローに合わせて実装) |
| 分析実行 | Notebook(Rスクリプト実行) |
| 認証・権限管理 | Microsoft Entra ID(ロールベースアクセス制御) |
| 利用環境 | Windows 11/Microsoft Edge |
| 出力・活用 | OneLakeへExcel出力 →各BIツールで活用 |

